
Explorando spaCy para Processamento de Linguagem Natural

Introdução ao spaCy: Uma Ferramenta Poderosa para PLN
Nos artigos anteriores, discutimos os fundamentos do Processamento de Linguagem Natural (PLN), desde a vetorização de palavras com TF-IDF até os embeddings estáticos do Word2Vec (transformers-cinco). Vimos como essas abordagens capturam semântica, mas carecem de contextualização dinâmica.
Neste ponto de todo este esforço, eu acho interessante apresentar uma ferramenta que pode ser utilizada para processamento de linguagem natural de forma voltada a produção e não a pesquisa e aprendizado. Neste caso, destaco o o spaCy. Esta biblioteca, escrita em Python, é amplamente utilizada para tarefas de PLN devido à sua eficiência e facilidade de uso. O spaCy oferece uma variedade de recursos, incluindo tokenização, análise sintática, reconhecimento de entidades nomeadas (NER) e visualização interativa.
O spaCy é conhecido por sua eficiência, facilidade de uso e pipelines pré-treinados, que permitem processar textos em vários idiomas, incluindo o nosso querido português. Este artigo detalha como configurar e utilizar o spaCy para processar textos, com ênfase em modelos para português (pt_core_news_sm, pt_core_news_md, pt_core_news_lg), análise de tokens, sintagmas nominais, dependências sintáticas, entidades nomeadas e visualizações interativas com displacy. Também exploramos como organizar resultados em tabelas com pandas para análises estruturadas.
Configurando o spaCy: Instalação e Modelos de Linguagem
Para começar, é necessário instalar o spaCy e um modelo de linguagem adequado. Em ambientes como Google Colab, a instalação do modelo pode ser feita diretamente via comandos de shell. Abaixo, mostramos como instalar um modelo em português, utilizando o modelo médio (pt_core_news_md) como ponto de partida para um equilíbrio entre precisão e desempenho.
# Instalação do modelo médio em português (execute apenas uma vez por sessão)
!python -m spacy download pt_core_news_md
print("Download do modelo concluído (se não houver erros acima).")
Após a instalação, o modelo pode ser carregado em Python para processar textos. Abaixo, um exemplo de carregamento e uso inicial:
import spacy
# Carrega o modelo médio em português
try:
nlp_pt = spacy.load("pt_core_news_md")
print("Modelo 'pt_core_news_md' carregado com sucesso!")
except OSError:
print("Erro ao carregar o modelo. Verifique se o download foi concluído.")
Escolhendo o Modelo Ideal
O spaCy oferece três tamanhos de modelos para português: pequeno (sm), médio (md) e grande (lg). Cada um tem características distintas, conforme detalhado na Tabela 1:
| Característica | pt_core_news_sm |
pt_core_news_md |
pt_core_news_lg |
|---|---|---|---|
| Tamanho | ~15-25 MB | ~40-60 MB | ~400-500+ MB |
| Precisão | Básica/Boa | Boa/Alta | Mais Alta |
| Velocidade | Mais Rápida | Média | Mais Lenta |
| Recursos | Menor consumo | Consumo moderado | Maior consumo |
| Vetores de Palavras | Menores/Menos eficazes | Mais eficazes | Maiores/Mais completos |
| NER | Desempenho básico | Melhor desempenho | Ótimo desempenho |
| Parsing | Desempenho básico | Melhor desempenho | Ótimo desempenho |
| Uso Recomendado | Prototipagem rápida, tarefas simples | Equilíbrio para aplicações de produção | Tarefas complexas com alta precisão |
Tabela 1: Comparação entre os modelos pt_core_news_sm, pt_core_news_md e pt_core_news_lg, destacando trade-offs entre tamanho, precisão e desempenho computacional.
O modelo md é frequentemente recomendado para aplicações gerais, pois oferece um bom equilíbrio entre precisão e eficiência computacional, enquanto o modelo lg é ideal para tarefas que exigem máxima precisão, como similaridade semântica complexa.
Processamento de Textos com spaCy
Uma vez carregado o modelo, o spaCy permite processar textos por meio de seu pipeline, que inclui tokenização, lematização, etiquetagem de classes gramaticais (POS), análise de dependências e reconhecimento de entidades. Abaixo, mostramos como processar um texto em português e extrair informações básicas dos tokens:
texto_pt = "O processamento de linguagem natural é fascinante e útil no Brasil."
doc_pt = nlp_pt(texto_pt)
print("\nAnálise do texto:")
for token in doc_pt:
print(f"{token.text:<15} {token.lemma_:<15} {token.pos_:<7} {spacy.explain(token.pos_):<20} {token.is_stop}")
Componentes do Pipeline
O pipeline do spaCy processa o texto em várias etapas:
- Tokenização: Divide o texto em unidades individuais (tokens), como palavras e pontuação.
- Lematização: Converte cada token para sua forma base (ex.:
é→ser). - Etiquetagem POS: Atribui classes gramaticais (ex.:
NOUN,VERB,ADJ) e etiquetas detalhadas (ex.:VBDpara verbo no passado). - Análise de Dependências: Identifica relações sintáticas entre tokens (ex.:
nsubjpara sujeito,dobjpara objeto direto). - Reconhecimento de Entidades Nomeadas (NER): Detecta entidades como pessoas, locais e organizações.
- Segmentação de Sentenças: Divide o texto em sentenças individuais.
O resultado é um objeto Doc, que funciona como um contêiner para o texto processado e suas anotações. Por exemplo, para iterar sobre sentenças:
texto = "O PLN é fascinante. Ele transforma textos em dados estruturados."
doc = nlp_pt(texto)
for sent in doc.sents:
print(f"> {sent}")
Análise Sintática e Noun Chunks
O spaCy permite um grau interessante de análise sintática, especialmente na identificação de sintagmas nominais (noun chunks) e dependências. Um noun chunk é um sintagma nominal com um substantivo ou pronome como núcleo, acompanhado de modificadores diretos (ex.: o gato preto). Abaixo, mostramos como extrair noun chunks e suas propriedades sintáticas:
Para saber mais: sintagma
Em linguística e gramática, um
sintagma(em inglês,phrase) é um grupo de uma ou mais palavras que funcionam juntas como uma unidade significativa dentro da estrutura de uma frase ou oração.Pense nele como um “bloco de construção” gramatical. As principais características de um
sintagmasão:
Núcleo(Head): Todosintagmaé construído em torno de uma palavra central chamadanúcleo. É onúcleoque define o tipo dosintagmae suas propriedades gramaticais básicas.Unidade Funcional: O grupo de palavras age como um único componente sintático. Ele pode desempenhar funções específicas na oração, como ser o sujeito, o objeto, o predicado, um modificador (adjunto), etc.
Estrutura: Pode consistir apenas no
núcleo(ex:'ele','corre') ou nonúcleoacompanhado pormodificadores(palavras que dão mais informação sobre onúcleo, como adjetivos, advérbios) e/oucomplementos(termos exigidos pelonúcleo, como o objeto de um verbo ou preposição).Tipos Comuns de Sintagmas (definidos pelo tipo do
núcleo):
Sintagma Nominal(SN/NP- Noun Phrase): Onúcleoé um substantivo ou pronome. Funciona tipicamente como sujeito, objeto, etc.Exemplos:
'o gato','a aliança estratégica entre os dois países','ela','President Donald J. Trump'. (Odoc.noun_chunksque vimos antes identifica variantes destes).Sintagma Verbal(SV/VP- Verb Phrase): Onúcleoé um verbo. Geralmente funciona como o predicado da oração, incluindo o verbo e seus objetos e/oumodificadores.Exemplos:
'comeu a maçã','reafirmaram a aliança','correu rapidamente','é'.Sintagma Adjetival(SAdj/AP- Adjective Phrase): Onúcleoé um adjetivo. Modifica substantivos ou funciona como predicativo.Exemplos:
'muito interessante','difícil','cheio de alegria'.Sintagma Adverbial(SAdv/AdvP- Adverb Phrase): Onúcleoé um advérbio. Modifica verbos, adjetivos, outros advérbios ou a frase inteira.Exemplos:
'muito bem','hoje','rapidamente'.Sintagma Preposicional(SP/PP- Prepositional Phrase): >É iniciado por uma preposição (que funciona comonúcleo) seguida por seu complemento (geralmente umsintagma nominal). Funciona como modificador (adjunto adnominal ou adverbial) ou complemento.- Exemplos:
'de Brazil','entre os dois países','com cuidado'.
Relevância para NLP (como no spaCy):
A análise sintática (parsing), como a dependency parsing que vimos na imagem ou a identificação de doc.noun_chunks, é fundamentalmente sobre identificar esses sintagmas e as relações entre eles para entender a estrutura gramatical e, consequentemente, o significado de uma sentença. Ferramentas como o spaCy são treinadas para reconhecer esses blocos de construção automaticamente.
texto = "Hoje, o presidente Bolsonaro e o presidente Trump reafirmaram a aliança estratégica."
doc = nlp_pt(texto)
for chunk in doc.noun_chunks:
print(f"{chunk.text:<30} {chunk.root.text:<15} {chunk.root.dep_:<10} {chunk.root.head.text}")
Sintagmas Nominais (Noun Chunks):
o presidente presidente nsubj reafirmaram
Bolsonaro Bolsonaro appos presidente
o presidente presidente conj presidente
Trump Trump appos presidente
a aliança estratégica aliança obj reafirmaram
A análise de dependências pode ser visualizada com o displacy, que gera diagramas de árvores sintáticas:
from spacy import displacy
displacy.render(doc, style="dep", jupyter=True)
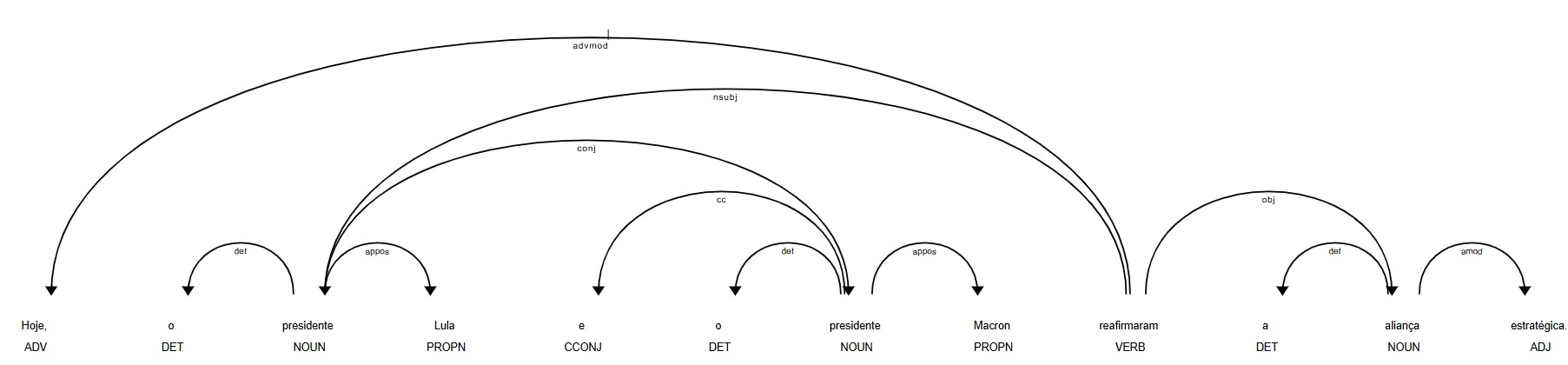 Figura 1: Visualização da árvore de dependências gerada pelo displacy, mostrando relações sintáticas como
Figura 1: Visualização da árvore de dependências gerada pelo displacy, mostrando relações sintáticas como nsubj (sujeito) e dobj (objeto direto) entre tokens.
Reconhecimento de Entidades Nomeadas (NER)
O spaCy é poderoso no reconhecimento de entidades nomeadas, como pessoas, locais e datas. Abaixo, um exemplo de extração de entidades e organização em um DataFrame:
import pandas as pd
cols = ("Texto", "Label")
rows = []
for ent in doc.ents:
rows.append([ent.text, ent.label_])
df = pd.DataFrame(rows, columns=cols)
print(df)
O resultado é um DataFrame que lista as entidades reconhecidas e suas respectivas classes, como ORG (organização), GPE (localidade) e DATE (data). As entidades também podem ser visualizadas diretamente no texto:
displacy.render(doc, style="ent", jupyter=True)
Organizando Resultados com pandas
Para análises mais estruturadas, os resultados do spaCy podem ser organizados em tabelas com pandas. Abaixo, um exemplo que extrai atributos detalhados de cada token:
cols = ("Texto", "Lemma", "POS", "Tag", "Dep", "Forma", "É Alfa", "É Stop")
rows = []
for token in doc:
row = [token.text, token.lemma_, token.pos_, token.tag_, token.dep_, token.shape_, token.is_alpha, token.is_stop]
rows.append(row)
df = pd.DataFrame(rows, columns=cols)
print(df)
Este dataframe pode ser visto na Figura 2, onde cada linha representa um token do texto processado, com colunas que incluem o texto original, a forma lematizada, a classe gramatical (POS), a etiqueta detalhada (Tag), a dependência sintática (Dep), a forma (Forma), se é alfabético (É Alfa) e se é uma stop word (É Stop).
Análise Detalhada de Tokens:
Texto Lemma POS Tag Dep Forma É Alfa É Stop
0 Hoje hoje ADV ADV advmod Xxxx True False
1 , , PUNCT PUNCT punct , False False
2 o o DET DET det x True True
3 presidente presidente NOUN NOUN nsubj xxxx True False
4 Lula Lula PROPN PROPN appos Xxxx True False
5 e e CCONJ CCONJ cc x True True
6 o o DET DET det x True True
7 presidente presidente NOUN NOUN conj xxxx True False
8 Macron Macron PROPN PROPN appos Xxxxx True False
9 reafirmaram reafirmar VERB VERB ROOT xxxx True False
10 a o DET DET det x True True
11 aliança aliança NOUN NOUN obj xxxx True False
12 estratégica estratégico ADJ ADJ amod xxxx True False
13 . . PUNCT PUNCT punct . False False
Essa abordagem permite análises quantitativas, como contagem de stop words ou distribuição de classes gramaticais.
Limitações do spaCy
Apesar de sua robustez, o spaCy tem limitações, especialmente em português:
- Suporte a Chunks: A identificação de noun chunks em português pode ser menos precisa devido a nuances linguísticas.
- Tamanho dos Modelos: Modelos grandes (
lg) consomem mais recursos, o que pode ser um problema em ambientes com restrições de memória. - Dependência de Dados de Treinamento: A precisão depende da qualidade dos dados usados para treinar os modelos, que podem não capturar todas as variações do português falado.
Essas limitações são abordadas em parte por modelos contextuais mais avançados, como os Transformers, que discutiremos em artigos futuros (transformers-oito).
O spaCy é uma ferramenta importante para o seu barco, nesta jornada entre algoritmos de processamento de linguagem natural, oferecendo pipelines para tokenização, análise sintática, reconhecimento de entidades e visualização. Sua facilidade de uso, combinada com modelos pré-treinados para português, o torna viável para aplicações que vão desde prototipagem rápida até sistemas de produção. No entanto, suas limitações, como o suporte parcial a noun chunks em português, destacam a importância de explorar modelos contextuais mais avançados.
Referências
- Documentação oficial do spaCy: https://spacy.io/
- Artigos anteriores da série: transformers-cinco, transformers-seis
- Biblioteca pandas: https://pandas.pydata.org/