
Cálculo Lambda para Neófitos

Começamos com os fundamentos teóricos e seguimos para as aplicações práticas em linguagens de programação funcionais. Explicamos abstração, aplicação e recursão. Mostramos exemplos de currying e combinadores de ponto fixo. O cálculo lambda é a base da computação funcional.
Introdução, História e Motivações e Limites
Todos os exercícios desta página foram removidos. Os exercícios estarão disponíveis apenas no livro que está sendo escrito. Removi também o capítulo sobre cálculo lambda simplesmente tipado. E algumas partes aleatórias que não estavam muito boas.
O cálculo lambda é uma teoria formal para expressar computação por meio da visão de funções como fórmulas. Um sistema para manipular funções como sentenças, desenvolvido por Alonzo Church sob uma visão extensionista das funções na década de 1930. Nesta teoria usamos funções para representar todos os dados e operações. Em cálculo lambda, tudo é uma função e uma função simples é parecida com:
\[\lambda x.\;x + 1\]Esta função adiciona $1$ ao seu argumento. O $\lambda$ indica que estamos definindo uma função.
Na teoria da computação definida por Church com o cálculo lambda existem três componentes básicos: as variáveis: $x$, $y$, $z$; as abstrações $\lambda x.\;E$. O termo $E$ representa uma expressão lambda e a aplicação $(E\;M)$. Com estes três componentes e o cálculo lambda é possível expressar qualquer função computacionalmente possível.
A Inovação de Church: Abstração Funcional
O trabalho de Alonzo Church é estruturado sobre a ideia de abstração funcional. Esta abstração permite tratar funções como estruturas de primeira classe. Neste cenário, as funções podem ser passadas como argumentos, retornadas como resultados e usadas em expressões compostas.
No cálculo lambda, uma função é escrita como $\lambda x.\;E$. Aqui, $\lambda$ indica que é uma função, $x$ é a variável ligada, na qual a função é aplicada, e $E$ é o corpo da função. Por exemplo, a função que soma $1$ a um número é escrita como $\lambda x.\;x + 1$. Isso possibilita a manipulação direta de funções, sem a necessidade de linguagens ou estruturas rígidas. A Figura 1.1.A apresenta o conceito de funções de primeira classe.
No cálculo lambda, uma função de ordem superior é uma função que aceita outra função como argumento ou retorna uma função como resultado. Isso significa que uma função de ordem superior trata funções como valores, podendo aplicá-las, retorná-las ou combiná-las com outras funções.
Seja $f$ uma função no cálculo lambda. Dizemos que $f$ é uma função de ordem superior se:
- $f$ aceita uma função como argumento.
- $f$ retorna uma função como resultado.
No cálculo lambda puro, as funções são anônimas. No entanto, em contextos de programação funcional, é comum nomear funções de ordem superior para facilitar seu uso e identificação em operações complexas. Vamos tomar esta licença poética, importada da programação funcional, de forma livre e temerária em todo este texto. Sempre que agradar ao pobre autor.
Considere a mesma função de adição de ordem superior, agora nomeada como
\[\text{adicionar} = \lambda x.\; \lambda y.\; x + y\]adicionar:Essa função nomeada pode ser usada como argumento para outras funções de ordem superior, como
\[\text{mapear} \; (\text{adicionar} \; 2) \; [1, 2, 3]\]mapear:Neste caso, a aplicação resulta em:
\[[3, 4, 5]\]
O cálculo lambda descreve um processo de aplicação e transformação de variáveis. Enquanto a Máquina de Turing descreve a computação de forma mecânica, o cálculo lambda foca na transformação de expressões. Para começarmos a entender o poder do cálculo lambda, podemos trazer a função $F$ um pouco mais perto dos conceitos de Church.
Vamos começar definindo uma expressão $M$ contendo uma variável $x$, na forma:
\[M(x) = x^2 + 2x + 1\]A medida que $x$ varia no domínio dos números naturais podemos obter a função representada na notação matemática padrão por $x \mapsto x^2 + x + 1$ este relação define o conjunto de valores que $M$ pode apresentar em relação aos valores de $x$. Porém, se fornecermos um valor de entrada específico, por exemplo, $2$, para $x$, valor da função será $2^2 + 4 + 1 = 9$.
Avaliando funções desta forma, Church introduziu a notação
\[λx: (x^2 + x + 1)\]Para representar a expressão $M$. Nesta representação temos uma abstração. Justamente porque a expressão estática $M(x)$, para $x$ fixo, torna-se uma função abstrata representada por $λx:M$.
Linguagens de programação modernas, como Python ou JavaScript, têm suas próprias formas de representar funções. Por exemplo, em Python, uma função pode ser representada assim:
-- Define a função f, que toma um argumento x and devolve x^2 + 2*x + 1
f :: Int -> Int
f x = x^2 + 2*x + 1
No cálculo lambda, usamos abstração e aplicação para criar e aplicar funções. Na criação de uma função que soma dois números, escrita como:
\[\lambda x. \lambda y.\;(x + y)\]A notação $\lambda$ indica que estamos criando uma função anônima. Essa abstração explícita é menos comum na notação matemática clássica na qual, geralmente definimos funções nomeadas.
A abstração cria uma função sem necessariamente avaliá-la. A variável $x$ em $\lambda x.\;E$ está ligada à função e não é avaliada até que um argumento seja aplicado. A abstração é puramente declarativa, descreve o comportamento da função sem produzir um valor imediato.
A aplicação, expressa por $M\;N$, é o processo equivalente a avaliar uma função algébrica em um argumento. Aqui, $M$ representa a função e $N$ o argumento que é passado para essa função. Ou, como dizemos em cálculo lambda, o argumento que será aplicado a função*. Considere a expressão:
\[(\lambda x.\;x + 5)\;3\]Neste caso, temos a aplicação da função $\lambda x.\;x + 5$ ao argumento $3$, resultando em $8$. Outro exemplo:
\[(\lambda f. \lambda x.\;f\;(f\;x))\;(\lambda y.\;y * 2)\;3\]Neste caso, temos uma função de composição dupla é aplicada à função que multiplica valores por dois e, em seguida, ao número $3$, resultando em $12$.
Em resumo, a abstração define uma função ao associar um parâmetro a um corpo de expressão; enquanto a aplicação avalia essa função ao fornecer um argumento. Ambas operações são independentes, mas interagem para permitir a avaliação de expressões no cálculo lambda.
O Cálculo Lambda e a Lógica
O cálculo lambda possui uma relação direta com a lógica matemática, especialmente através do isomorfismo de Curry-Howard. Esse isomorfismo cria uma correspondência entre provas matemáticas e programas computacionais. Em termos simples, uma prova de um teorema é um programa que constrói um valor a partir de uma entrada, e provar teoremas equivale a computar funções.
O cálculo lambda define computações e serve como uma linguagem para representar e verificar a correção de algoritmos. Esse conceito se expandiu na pesquisa moderna e fundamenta assistentes de prova e linguagens de programação com sistemas de tipos avançados, como o Sistema F e o Cálculo de Construções.
-
Funções como cidadãos de primeira classe: No cálculo lambda, funções são valores. Podem ser passadas como argumentos, retornadas como resultados e manipuladas livremente. Isso é um princípio central da programação funcional, notadamente em Haskell.
-
Funções de ordem superior: O cálculo lambda permite a criação de funções que operam sobre outras funções. Isso se traduz em conceitos aplicados em funções como
map,filterereduceem linguagens funcionais. -
currying: A técnica de transformar uma função com múltiplos argumentos em uma sequência de funções de um único argumento é natural no cálculo lambda e no Haskell e em outras linguagens funcionais.
-
Avaliação preguiçosa (lazy): Embora não faça parte do cálculo lambda puro, a semântica de redução do cálculo lambda, notadamente a estratégia de redução normal inspirou o conceito de avaliação preguiçosa em linguagens como Haskell.
-
Recursão: Definir funções recursivas é essencial em programação funcional. No cálculo lambda, isso é feito com combinadores de ponto fixo.
Representação de Valores e Computações
Uma das características principais do cálculo lambda é representar valores, dados e computações complexas, usando exclusivamente funções. Até números e booleanos são representados de forma funcional. Um exemplo indispensável é a representação dos números naturais, chamada Numerais de Church:
\[\begin{align*} 0 &= \lambda s.\;\lambda z.\;z \\ 1 &= \lambda s.\;\lambda z.\;s\;z \\ 2 &= \lambda s.\;\lambda z. s\;(s\;z) \\ 3 &= \lambda s.\;\lambda z.\;s\;(s (s\;z)) \end{align*}\]Essa codificação permite que operações aritméticas sejam definidas inteiramente em termos de funções. Por exemplo, a função sucessor, usada para provar a criação de conjuntos de números contáveis, como os naturais e os inteiros, pode ser expressa como:
\[\text{succ} = \lambda n.\;\lambda s.\;\lambda z.\;s\;(n\;s\;z)\]Assim, operações como adição e multiplicação podem ser construídas usando termos lambda.
Sintaxe e Semântica
O cálculo lambda usa uma notação simples para definir e aplicar funções. Ele se baseia em três elementos principais: variáveis, abstrações e aplicações.
As variáveis representam valores que podem ser usados em expressões. Uma variável é um símbolo que pode ser substituído por um valor ou outra expressão. Por exemplo, $x$ é uma variável que pode representar qualquer valor.
A abstração é a definição de uma função. No cálculo lambda, uma abstração é escrita usando a notação $\lambda$, seguida de uma variável, um ponto e uma expressão. Por exemplo:
\[\lambda x.\;x^2 + 2x + 1\]$\lambda x.$ indica que estamos criando uma função de $x$. A expressão $x^2 + 2x + 1$ é o corpo da função. A abstração define uma função anônima que pode ser aplicada a um argumento.
A aplicação é o processo de usar uma função em um argumento. No cálculo lambda, representamos a aplicação de uma função a um argumento colocando-os lado a lado. Por exemplo, se tivermos a função $\lambda x.\;x + 1\;$ e quisermos aplicá-la ao valor $2$, escrevemos:
\[(\lambda x.\;x + 1)\;2\]O resultado da aplicação é a substituição da variável $x$ pelo valor $2$, resultando em $2 + 1$ equivalente a $3$. Outros exemplos interessantes de função são a função identidade, que retorna o próprio valor e que é escrita como $\lambda x.\;x$ e uma função que some dois números e que pode ser escrita como $\lambda x. \lambda y.\;(x + y)$.
No caso da função que soma dois números, $\lambda x. \lambda y.\;(x + y)$, temos duas abstrações $\lambda x$ e $\lambda y$, cada uma com sua própria variável. Logo, $\lambda x. \lambda y.\;(x + y)$ precisa ser aplicada a dois argumentos. Tal como: $\lambda x. \lambda y.\;(x + y)\;3\;4$.
Formalmente dizemos que:
-
Se $x$ é uma variável, então $x$ é um termo lambda.
-
Se $M$ e $N$ são termos lambda, então $(M\; N)$ é um termo lambda chamado de aplicação.
-
Se $E$ é um termo lambda, e $x$ é uma variável, então a expressão $(λx. E)$ é um termo lambda chamado de abstração lambda.
Esses elementos básicos, variáveis, abstração e aplicação, formam a base do cálculo lambda. Eles permitem definir e aplicar funções de forma simples sem a necessidade de nomes ou símbolos adicionais.
Estrutura Sintática - Gramática
O cálculo lambda é um sistema formal para representar computação baseado na abstração de funções e sua aplicação. Sua sintaxe é simples, porém expressiva. Enfatizando a simplicidade. Tudo é uma expressão, ou termo, e existem três tipos de termos:
-
Variáveis: representadas por letras minúsculas como $x$, $y$, $z$. As variáveis não possuem valor intrínseco, como acontece nas linguagens imperativa. Variáveis atuam como espaços reservados para entradas potenciais de funções.
-
Aplicação: a aplicação $(M\;N)$ indica a aplicação da função $M$ ao argumento $N$. A aplicação é associativa à esquerda, então $M\;N\;P$ é interpretado como $((M\;N)\;P)$.
-
Abstração: a abstração $(\lambda x.\;E)$ representa uma função que tem $x$ como parâmetro e $E$ como corpo. O símbolo $\lambda$ indica que estamos definindo uma função. Por exemplo, $(\lambda x.\;x)$ é a função identidade.
A abstração é a base do cálculo lambda. Ela permite criar funções anonimas. Um conceito importante relacionado à abstração é a distinção entre variáveis livres e ligadas. Uma variável é ligada se aparece no escopo de uma abstração lambda que a define. Em $(\lambda x.\;x\;y)$, $x$ é uma variável ligada. Por outro lado, uma variável é livre se não estiver ligada a nenhuma abstração. No exemplo anterior, $y$ é uma variável livre.
A distinção entre variáveis livres e ligadas permitirá o entendimento da operação de substituição no cálculo lambda. A substituição é a base do processo de computação no cálculo lambda. O poder computacional do cálculo lambda está na forma como esses elementos simples podem ser combinados para expressar operações complexas como valores booleanos, estruturas de dados e até mesmo recursão usando esses os conceitos básicos, variáveis, abstração e aplicação, e a existência, ou não, de variáveis ligadas. Formalmente, podemos definir a sintaxe do cálculo lambda usando uma gramática representada usando sintaxe da Forma de Backus-Naur (BNF):
\[\begin{align*} \text{termo} &::= \text{variável} \\ &\;|\;\text{constante} \\ &\;|\;\lambda . \text{variável}.\;\text{termo} \\ &\;|\;\text{termo}\;\text{termo} \\ &\;|\;(\text{termo}) \end{align*}\]A gentil leitora pode facilitar o entendimento de abstrações e aplicações se pensar em um termo lambda como sendo uma árvore, cuja forma corresponde à forma como o termo aplica as regras de produção da gramática. Chamamos a árvore criada pela derivação das regras de produção de de árvore sintática ou árvore de derivação. Para um dado termo $M$, qualquer, está árvore terá vértices rotulados por $\lambda x$ ou $@$, enquanto as folhas serão rotuladas por variáveis.
Indutivamente, podemos definir que a árvore de construção de uma variável $x$ é somente uma folha, rotulada por $x$. A árvore de construção de uma abstração $\lambda x.\;E$ consistirá em um vértice rotulado por $\lambda x$ com uma única subárvore, que é a árvore de construção de $E$. Por fim, a árvore de construção de uma aplicação $E\;N$ consistirá em um vértice rotulado por $@$ com duas subárvores: a subárvore esquerda é a árvore de construção de $E$ e a subárvore direita é a árvore de construção de $N$. Por exemplo, a árvore de construção do termo $\lambda x \lambda y.\;x\;y\;\lambda z.\;y\;z$ será:
\[\begin{array}{c} \lambda x \\ \downarrow \\ \lambda y \\ \downarrow \\ \diagup \quad \diagdown \\ \begin{array}{cc} \quad x \quad & \quad \lambda z \quad \\ & \downarrow \\ & \begin{array}{cc} \;y &\;z \end{array} \end{array} \end{array}\]Neste texto, vamos dar prioridade a derivação gramatical, deixando as árvores para suporte a explicação das abstrações. Pelo sim, pelo não, vamos ver mais dois exemplos.
Exemplo 1: Representação da abstração $\lambda x.\;x\;x$
Antes de vermos a árvore, podemos analisar a estrutura do termo $\lambda x.\;x\;x$. Nesta expressão, o termo $\lambda x$ indica que $x$ é o parâmetro da função e o corpo da função é $x\;x$, a aplicação de $x$ a si mesmo.
Agora que a curiosa leitora entendeu a expressão construir a árvore.
\[\begin{array}{c} \lambda x \\ \downarrow \\ \begin{array}{c} @ \\ \diagup \quad \diagdown \\ x \quad \quad \quad x \end{array} \end{array}\]Esta árvore é composta de um vértice raiz, no topo, $\lambda x$, indicando a abstração de $x$. Logo em seguida, a leitora pode ver o vértice de aplicação $@$ no meio da árvore representando que $x$ está sendo aplicado a $x$. Finalmente, as folhas da árvore são as variáveis $x$ à esquerda e à direita do vértice de aplicação, correspondendo às duas ocorrências de $x$ no corpo da função.
Exemplo 2: Representação da aplicação $(\lambda x.\;x + 1)\;2$
Outra vez podemos começar com a estrutura do termo $(\lambda x.\;x + 1)\;2$. A expressão $\lambda x.\;x + 1$ define uma função que recebe $x$ como argumento e retorna $x + 1$. O termo $2$ é o argumento que é passado para a função. Consequentemente, a aplicação $(\lambda x.\;x + 1)\;2$ envolve a substituição de $x$ por $2$ no corpo da função, o que resultará na expressão $2 + 1$. Esta função é representada pela árvore:
\[\begin{array}{c} @ \\ \diagup \quad \diagdown \\ \begin{array}{c} \lambda x & \quad 2 \\ \downarrow \\ x + 1 \end{array} \end{array}\]A árvore sintática representa a aplicação de uma função a um argumento. O vértice de aplicação é representado por $@$ e suas subárvores mostram a função e o argumento.
Semântica Operacional
A semântica operacional é uma abordagem rigorosa para descrever o comportamento de linguagens formai, especificando como as expressões de uma linguagem são avaliadas. No caso de linguagens de programação é a semântica operacional que define como os programas irão funcionar.
No contexto do cálculo lambda, a semântica operacional se concentra em como os termos são transformados por meio de uma sequência de reduções. As reduções operam sobre a estrutura sintática dos termos, permitindo a análise detalhada do processo de avaliação, desde a aplicação de funções até a substituição de variáveis.
Abaixo, são apresentadas as principais reduções operacionais utilizadas no cálculo lambda:
-
Redução Beta: A regra que define a ação de aplicação e chamada de redução beta ou redução-$beta$. Usamos a redução beta quando uma função é aplicada a um argumento. Neste caso, a redução beta substitui a variável ligada no corpo da função pelo argumento fornecido:
\[(\lambda x.\;e_1)\;e_2\;\rightarrow\;e_1[x := e_2]\]Isso significa que aplicamos a função $\lambda x.\;e_1$ ao argumento $e_2$, substituindo $x$ por $e_2$ em $e_1$.
Exemplo: considere o termo:
\[(\lambda x.\;x^2)\;3\;\rightarrow\;3^2\]Existem duas estratégias para realização da redução beta:
-
Ordem normal: reduzimos a aplicação mais à esquerda e mais externa primeiro. Essa estratégia sempre encontra a forma normal, se esta existir.
Exemplo: considere o termo:
\[(\lambda x.\;(\lambda y.\;y + x)\;2)\;(3 + 4)\]Não reduzimos $3 + 4$ imediatamente. Aplicamos a função externa:
\[(\lambda x.\;(\lambda y.\;y + x)\;2)\;7\]Substituímos $x$ por $(3 + 4)$ em $(\lambda y.\;y + x)\;2$:
\[(\lambda y.\;y + (3 + 4))\;2\]Aplicamos a função interna:
\[2 + (3 + 4) \rightarrow 9\] -
Ordem aplicativa: avaliamos primeiro os subtermos (argumentos) antes de aplicar a função.
Exemplo:
\[(\lambda x.\;(\lambda y.\;y + x)\;2)\;(3 + 4)\]Avaliamos $3 + 4$:
\[(\lambda x.\;(\lambda y.\;y + x)\;2)\;7\]Substituímos $x$ por $7$:
\[(\lambda y.\;y + 7)\;2\]Avaliamos $2 + 7$:
\[9\]
-
-
Redução alfa ou redução-$\alpha$: esta redução determina as regras que permitem renomear variáveis ligadas na esperança de evitar conflitos.
Exemplo:
\[\lambda x.\;x + 1 \rightarrow \lambda y.\;y + 1\] -
Redução eta ou redução-$\eta$: esta redução define as regras de captura a equivalência entre funções que produzem os mesmos resultados.
Exemplo:
\[\lambda x.\;f(x) \rightarrow f\]
Essas regras garantem que a avaliação seja consistente. Por fim, mas não menos importante, o Teorema de Church-Rosser parece implicar que, se uma expressão pode ser reduzida de várias formas então todas chegarão à mesma forma normal, se esta forma existir1.
No cálculo lambda, podemos dizer que um termo está em forma normal quando não é possível realizar mais nenhuma redução beta sobre ele. Ou seja, é um termo que não contém nenhum redex, expressão redutível e, portanto, não pode ser simplificado ou reescrito de nenhuma outra forma. Formalmente: um termo $M$ está em forma normal se:
\[\forall N \, : \, M \not\rightarrow N\]Isso significa que não existe nenhum termo $N$ tal que o termo $M$ possa ser reduzido a $N$.
No cálculo lambda, um termo pode não ter uma forma normal se o processo de redução continuar indefinidamente sem nunca alcançar um termo irredutível. Isso acontece devido à possibilidade de loops infinitos ou recursões que não terminam. Os termos com esta característica são conhecidos como termos divergentes**.
Substituição
A substituição é a operação estrutural do cálculo lambda. Ela funciona substituindo uma variável livre por um termo, e sua formalização evita a captura de variáveis, garantindo que ocorra de forma correta. A substituição é definida recursivamente:
- $[N/x] x\;N$
- $[N/x] y\;y, \quad \text{se}\;x \neq y$
- $[N/x]\;(M_1 \, M_2) ([N/x]M_1)([N/x]M_2)$
- $[N/x]\;(\lambda Y \, M) \lambda Y \, ([N/x]M), \quad \text{se} ; x \neq Y \quad \text{e} \quad Y \notin FV(N)$
Aqui, $FV(N)$ é o conjunto de variáveis livres, Free Variable de $N$. A condição $y \notin FV(N)$ é necessária para evitar a captura de variáveis livres.
Formalmente dizemos que: para qualquer termo lambda $M$, o conjunto $FV(M)$ de variáveis livres de $M$ e o conjunto $BV(M)$ de variáveis ligadas em $M$ serão definidos de forma indutiva:
- Se $M = x$ (uma variável), então:
- $FV(x) = {x}$
- $BV(x) = \emptyset$
- Se $M = (M_1 M_2)$, então:
- $FV(M) = FV(M_1) \cup FV(M_2)$
- $BV(M) = BV(M_1) \cup BV(M_2)$
- Se $M = (\lambda x: M_1)$, então:
- $FV(M) = FV(M_1) \setminus {x}$
- $BV(M) = BV(M_1) \cup {x}$
Se $x \in FV(M_1)$, dizemos que as ocorrências da variável $x$ ocorrem no escopo de $\lambda$. Um termo lambda $M$ é fechado se $FV(M) = \emptyset$, ou seja, se não possui variáveis livres.
Exemplo:
\[FV\left((\lambda x: yx)z\right) = \{y, z\}, \quad BV\left((\lambda x: yx)z\right) = \{x\}\]e
\[FV\left((\lambda xy: yx)zw\right) = \{z, w\}, \quad BV\left((\lambda xy: yx)zw\right) = \{x, y\}.\]Podemos pensar na substituição como um processo de buscar e substituir em uma expressão, mas com algumas regras especiais. Lendo estas regras em bom português teríamos:
-
A regra 1 (Regra de Substituição Direta): $[N/x]\,x = N$ indica que a variável $x$ será substituída pelo termo $N$. Esta é a regra fundamenta a substituição. De forma mais intuitiva podemos dizer que esta regra significa que se encontrarmos exatamente a variável que estamos procurando, substituímos por nosso novo termo. Por exemplo, em $[3/x]\,x$, substituímos $x$ por $3$.
-
A regra 2 (Regra de Variável Livre): $[N/x]\,y = y$, se $x \neq y$, está correta ao indicar que as variáveis que não são $x$ permanecem inalteradas. Ou seja, se durante a substituição de uma variável encontramos uma variável diferente, deixamos como está. Por exemplo: na substituição $[3/x]\,y$, $y$ permanece $y$
-
A regra 3 (Regra de Distribuição da Substituição): $[N/x]\;(M_1\;M_2)\,=\,([N/x]M_1)([N/x]M_2)$ define corretamente a substituição em uma aplicação de termos. O que quer dizer que, se estivermos substituindo em uma aplicação de função, fazemos a substituição em ambas as partes. Por exemplo: em $[3/x]\;(x\;y)$, substituímos em $x$ e $y$ separadamente, resultando em $(3\;y)$.
-
A regra 4 (Regra de Evitação de Captura de Variáveis): $[N/x]\;(\lambda y.\;M) \, = \lambda y.\;([N/x]M)$, se $x \neq y$ e $y \notin FV(N)$, está bem formulada, indicando que a variável vinculada $y$ não será substituída se $x \neq y$ e $y$ não estiverem no conjunto de variáveis livres de $N$, o que evita a captura de variáveis. Em uma forma mais intuitiva podemos dizer que se encontrarmos uma abstração lambda, temos que ter cuidado: se a variável ligada for a mesma que estamos substituindo, paramos; se for diferente, substituímos no corpo, mas só se for seguro (sem captura de variáveis). Por exemplo: em $[3/x]\;(\lambda y.\;x)$, substituímos $x$ no corpo, resultando em $\lambda y.\;3$.
Para que a esforçada leitora possa fixar o entendimento destes conceitos, considere o seguinte exemplo:
\[[y/x]\;(\lambda y.\;x) \neq \lambda y.\;y\]Se realizarmos a substituição diretamente, a variável livre $y$ será capturada, alterando o significado do termo original. Para evitar isso, utilizamos a substituição com evasão de captura. Isto é feito com a aplicando a redução-$\alpha$ para as variáveis ligadas que possam causar conflito. Considere:
\[[y/x]\;(\lambda y.\;x) \, = \lambda z.\;[y/x]\;([z/y]x) \, = \lambda z.\;y\]Neste processo, a variável ligada $y$ foi renomeada como $z$ antes de realizar a substituição, evitando assim a captura da variável livre $y$.
Outro exemplo ilustrativo:
\[[z/x]\;(\lambda z.\;x) \neq \lambda z.\;z\]Se fizermos a substituição diretamente, a variável $z$ livre em $x$ será capturada pela abstração $\lambda z$, modificando o significado do termo. A solução correta é renomear a variável ligada antes da substituição:
\[[z/x]\;(\lambda z.\;x) \, = \lambda w.\;[z/x]\;([w/z]x) \, = \lambda w.\;z\]Este procedimento assegura que a variável livre $z$ em $x$ não seja capturada pela abstração $\lambda z$, preservando o significado original do termo.
Exemplo 1: Substituição direta sem captura de variável livre
\[[a/x]\;(x + y) \, = a + y\]Neste caso, substituímos a variável $x$ pelo termo $a$ na expressão $x + y$, resultando em $a + y$. Não há risco de captura de variáveis livres, pois $y$ não está ligada a nenhuma abstração e permanece livre na expressão resultante.
Exemplo 2: Substituição direta mantendo variáveis livres
\[[b/x]\;(x\;z) \, = b\;z\]Aqui, substituímos $x$ por $b$ na expressão $x\;z$, obtendo $b\;z$. A variável $z$ permanece livre e não ocorre captura, pois não está sob o escopo de nenhuma abstração lambda que a ligue.
Exemplo 3: Evasão de captura com renomeação de variável ligada
\[[y/x]\;(\lambda y.\;x) \, = \lambda z.\;[y/x]\;([z/y]x) \, = \lambda z.\;y\]Neste exemplo, se realizássemos a substituição diretamente, a variável livre $y$ em $x$ seria capturada pela abstração $\lambda y$, alterando o significado da expressão. Para evitar isso, seguimos os passos:
-
Renomeação (Redução Alfa): Renomeamos a variável ligada $y$ para $z$ na abstração, obtendo $\lambda z.\, [z/y]x$.
-
Substituição: Aplicamos $[y/x]\;(x)$, resultando em $y$.
-
Resultado: A expressão torna-se $\lambda z.\;y $, e $y$ permanece livre.
Evitamos a captura da variável livre $y$ pela abstração lambda.
Semântica Denotacional no Cálculo Lambda
A semântica denotacional é uma abordagem matemática para atribuir significados formais às expressões de uma linguagem formal, como o cálculo lambda.
Na semântica denotacional, cada expressão é mapeada para um objeto matemático que representa seu comportamento computacional. Isso fornece uma interpretação abstrata da computação, permitindo analisar e provar propriedades sobre programas com rigor.
No contexto do cálculo lambda, o domínio semântico é construído como um conjunto de funções e valores. O significado de uma expressão é definido por sua interpretação nesse domínio, utilizando um ambiente $\rho$ que associa variáveis a seus valores.
A interpretação denotacional é formalmente definida pelas seguintes regras:
-
Variáveis:
\[[x]_\rho = \rho(x)\]O significado de uma variável $x$ é o valor associado a ela no ambiente $\rho$.Intuitivamente podemos entender esta regra como: quando encontramos uma variável $x$, consultamos o ambiente $\rho$ para obter seu valor associado.
Exemplo: suponha um ambiente $\rho$ de tal forma que $\rho(x) \, = 5$.
\[[x]_\rho = \rho(x) \, = 5\]Assim, o significado da variável $x$ é o valor $5$ no ambiente atual.
-
Abstrações Lambda:
\[[\lambda x.\;E]_\rho = f\]O termo $f$ é uma função tal que:
\[f(v) \, = [E]_{\rho[x \mapsto v]}\]Isso significa que a interpretação de $\lambda x.\;E$ é uma função que, dado um valor $v$, avalia o corpo $E$ no ambiente no qual $x$ está associado a $v$. Em bom português esta regra significa que uma abstração $\lambda x.\;E$ representa uma função anônima. Na semântica denotacional, mapeamos essa abstração para uma função matemática que, dado um valor de entrada, produz um valor de saída. Neste caso, teremos dois passos:
-
Definição da Função $f$: A abstração é interpretada como uma função $f$. Neste caso, para cada valor de entrada $v$, calculamos o significado do corpo $e$ no ambiente estendido $\rho[x \mapsto v]$.
-
Ambiente Estendido: O ambiente $\rho[x \mapsto v]$ é igual a $\rho$, exceto que a variável $x$ agora está associada ao valor $v$.
Exemplo:
Considere a expressão $\lambda x.\;x + 1$.
Interpretação:
\[[\lambda x.\;x + 1]_\rho = f\]O termo $f(v) \, = [x + 1]_{\rho[x \mapsto v]} = v + 1$.
Significado: A abstração é interpretada como a função que incrementa seu argumento em 1.
-
-
Aplicações:
\[[e_1\;e_2]_\rho = [e_1]_\rho\left([e_2]_\rho\right)\]O significado de uma aplicação $e_1\;e_2$ é obtido aplicando o valor da expressão $e_1$ (que deve ser uma função) ao valor da expressão $e_2$. Para interpretar uma aplicação $e_1\;e_2$, avaliamos ambas as expressões e aplicamos o resultado de $e_1$ ao resultado de $e_2$. Neste cenário temos três passos:
-
Avaliar $e_1$: Obtemos $[e_1]_\rho$, que deve ser uma função.
-
Avaliar $e_2$: Obtemos $[e_2]_\rho$, que é o argumento para a função.
-
Aplicar: Calculamos $[e_1]\rho\left([e_2]\rho\right)$.
Exemplo: considere a expressão $(\lambda x.\;x + 1)\;4$. Seguiremos três passos:
Passo 1: Interpretar $\lambda x.\;x + 1$.
\[[\lambda x.\;x + 1]_\rho = f, \quad \text{tal que} \quad f(v) \, = v + 1\]Passo 2: Interpretar $4$.
\[[4]_\rho = 4\]Passo 3: Aplicar $f$ a $4$.
\[[(\lambda x.\;x + 1)\;4]_\rho = f(4) \, = 4 + 1 = 5\]A expressão inteira é interpretada como o valor $5$.
-
Ambiente $\rho$ e Associação de Variáveis
O ambiente $\rho$ armazena as associações entre variáveis e seus valores correspondentes. Especificamente, $\rho$ é uma função que, dado o nome de uma variável, retorna seu valor associado. Ao avaliarmos uma abstração, estendemos o ambiente com uma nova associação utilizando $[x \mapsto v]$.
Exemplo de Atualização:
-
Ambiente inicial: $\rho = { Y \mapsto 2 }$
-
Avaliando $\lambda x.\;x + y$ com $x = 3$:
-
Novo ambiente: $\rho’ = \rho[x \mapsto 3] = { Y \mapsto 2, x \mapsto 3 }$
-
Avaliamos $x + y$ em $\rho’$:
A semântica denotacional facilita o entendimento do comportamento dos programas sem se preocupar com detalhes de implementação. Permite demonstrar formalmente que um programa satisfaz determinadas propriedades. Na semântica denotacional o significado de uma expressão complexa é construído a partir dos significados de suas partes.
A experta leitora deve concordar que exemplos, facilitam o entendimento e nunca temos o suficiente.
Exemplo 1: Com Variáveis Livres: considere a expressão $\lambda x.\;x + y$, na qual $y$ é uma variável livre.
- Ambiente Inicial: $\rho = { Y \mapsto 4 }$
- Interpretação da Abstração:
- Aplicação: Avaliando $f(6)$, obtemos $6 + 4 = 10$.
Exemplo 2: Aninhamento de Abstrações. Considere $\lambda x.\;\lambda y.\;x + y$.
-
Interpretação:
- Primeiro, interpretamos a abstração externa:
- Agora, interpretamos a abstração interna no ambiente estendido:
-
Aplicação:
-
Avaliando $((\lambda x.\;\lambda y.\;x + y)\;3)\;5$:
- $f(3) \, = g$, para $g(w) \, = 3 + w$
- $g(5) \, = 3 + 5 = 8$
-
Observe que a Semântica Operacional é geralmente mais adequada para descrever a execução procedural de linguagens que usam passagem por referência, pois permite capturar facilmente como os estados mudam durante a execução. Por outro lado, a Semântica Denotacional é mais alinhada com linguagens puras, que preferem passagem por cópia, evitando efeitos colaterais e garantindo que o comportamento das funções possa ser entendido matematicamente.
Existe uma conexão direta entre a forma como a semântica de uma linguagem é modelada e o mecanismo de passagem de valor que a linguagem suporta. Linguagens que favorecem efeitos colaterais tendem a ser descritas de forma mais natural por semântica operacional, enquanto aquelas que evitam efeitos colaterais são mais bem descritas por semântica denotacional.
Técnicas de Redução, Confluência e Combinadores
As técnicas de redução no cálculo lambda são mecanismos para simplificar e avaliar expressões lambda. Estas incluem a redução-$\alpha$ e a redução beta, que são utilizadas para manipular e computar expressões lambda. Essas técnicas são relevantes tanto para a teoria quanto para a implementação prática de sistemas baseados em lambda, incluindo linguagens de programação funcional. A compreensão dessas técnicas permite entender como funções são definidas, aplicadas e transformadas no contexto do cálculo lambda. A redução-$\alpha$ lida com a renomeação de variáveis ligadas, enquanto a redução beta trata da aplicação de funções a argumentos.
O Teorema de Church-Rosser, conhecido como propriedade de confluência local, estabelece a consistência do processo de redução no cálculo lambda. currying, por sua vez, é uma técnica que transforma funções com múltiplos argumentos em uma sequência de funções de um único argumento. Os combinadores, como S, K, e I, são expressões lambda sem variáveis livres que permitem a construção de funções complexas a partir de blocos básicos. Esses conceitos complementam as técnicas de redução e formam a base teórica para a manipulação e avaliação de expressões no cálculo lambda.
Redução Alfa
A redução-$\alpha$, ou alpha reduction, é o processo de renomear variáveis ligadas em termos lambda, para preservar o comportamento funcional dos termos. Dois termos são equivalentes sob redução-$\alpha$ se diferirem unicamente nos nomes de suas variáveis ligadas.
A atenta leitora deve considerar um termo lambda $\lambda x.\;E$, na qual $E$ é o corpo do termo. A redução-$\alpha$ permitirá a substituição da variável ligada $x$ por outra variável, digamos $y$, desde que $y$ não apareça livre em $E$. O termo resultante é $\lambda y.\;E[x \mapsto y]$. Neste caso, a notação $E[x \mapsto y]$ indica a substituição de todas as ocorrências de $x$ por $y$ em $E$. Formalmente:
Seja $\lambda x.\;E$ um termo lambda, teremos:
\[\lambda x.\;E \to_\alpha \lambda y.\;E[x \mapsto y]\]com a condição:
\[y \notin \text{FV}(E)\]O termo $\text{FV}(E)$ representa o conjunto de variáveis livres em $E$, e $E[x \mapsto y]$ indica o termo resultante da substituição de todas as ocorrências da variável $x$ por $y$ em $E$, respeitando as ligações de variáveis para evitar a captura. A substituição $E[x \mapsto y]$ é definida formalmente por indução na estrutura de $E$. As possibilidades que devemos analisar são:
-
Se $E$ é uma variável, e for igual a $x$, a substituição resulta em $y$; caso contrário, $E[x \mapsto y]$ é o próprio $E$.
-
Se $E$ é uma aplicação $E_1\;E_2$, a substituição é aplicada a ambos os componentes, ou seja, $E[x \mapsto y] = E_1[x \mapsto y]\;E_2[x \mapsto y]$.
-
Se $E$ é uma abstração $\lambda z.\;E’$, a situação depende da relação entre $z$ e $x$.
-
Se $z$ é igual a $x$, então $E[x \mapsto y]$ é $\lambda z.\;E’$, pois $x$ está ligada por $\lambda z$ e não deve ser substituída dentro de seu próprio escopo.
-
Se $z$ é diferente de $x$, e $y$ não aparece livre em $E’$ e $z$ é diferente de $y$, então $E[x \mapsto y]$ é $\lambda z.\;E’[x \mapsto y]$.
-
-
Se $y$ aparece livre em $E’$ ou $z$ é igual a $y$, é necessário renomear a variável ligada $z$ para uma nova variável $w$ que não apareça em $E’$ nem em $y$, reescrevendo $E$ como $\lambda w.\;E’[z \mapsto w]$ e então procedendo com a substituição: $E[x \mapsto y] = \lambda w.\;E’[z \mapsto w][x \mapsto y]$.
Finalmente temos que a condição $y \notin \text{FV}(E)$ é a forma de evitar a captura de variáveis livres durante a substituição, garantindo que o conjunto de variáveis livres permaneça inalterado e que a semântica do termo seja preservada.
Usamos A redução-$\alpha$ para evitar a captura de variáveis livres durante a substituição na redução beta. Ao substituir um termo $N$ em um termo $E$, é possível que variáveis livres em $N$ tornem-se ligadas em $E$, o que irá alterar o significado semântico do termo. Para evitar isso, é necessário renomear as variáveis ligadas em $E$ para novas variáveis que não conflitem com as variáveis livres em $N$.
Exemplo 1: Considere o termo:
\[(\lambda x.\;x)\;(\lambda y.\;y)\]Este termo é uma aplicação de função com duas funções identidade. Podemos começar com a estrutura do termo: uma função externa $\lambda x.\;x$ aplicada a um argumento que é uma função, $\lambda y.\;y$.
Uma vez que entendemos a estrutura, podemos fazer a análise das variáveis ligadas. Na função externa, $(\lambda x.\;x)$, $x$ é uma variável ligada. No argumento, $(\lambda y.\;y)$, $y$ é uma variável ligada.
Nosso próximo passo é verificar o escopo das variáveis. No termo original, $x$ está ligada no escopo de $\lambda x.\;x$ e $y$ está ligada no escopo de $\lambda y.\;y$
Com o Exemplo 2 podemos perceber que a necessidade de redução-$\alpha$ não depende somente da presença de variáveis ligadas, mas depende de como seus escopos interagem no termo como um todo.
Exemplo 2: Considere o termo:
\[(\lambda x.\;\lambda x.\;x)\;y\]Observe que neste termo, a variável $x$ está ligada duas vezes em escopos diferentes, duas abstrações lambda. Para evitar confusão, podemos aplicar a redução-$\alpha$ para renomear uma das variáveis ligadas. Podemos aplicar na abstração interna ou na abstração externa. Vejamos:
-
Renomear a variável ligada interna:
\[\lambda x.\;\lambda x.\;x \to_\alpha \lambda x.\;\lambda z.\;z\]Esta escolha é interessante por alguns motivos. O primeiro é que esta redução preserva a semântica do termo mantendo o significado original da função externa intacto. A redução da abstração interna preserva o escopo mínimo de mudança. Alterando o escopo mais interno, minimizamos o impacto em possíveis referências externas.
A escolha pela abstração interna mantém a clareza da substituição. Durante a aplicação, redução-$beta$, ficará evidente que $y$ irá substituir o $x$ externo, enquanto $z$ permanece inalterado. Por fim, a redução da abstração interna é consistente com as práticas de programação e reflete o princípio de menor surpresa, mantendo variáveis externas estáveis. Por último, a escolha da abstração interna previne a captura acidental de variáveis livres.
-
Renomear a variável ligada externa:
\[\lambda x.\;\lambda x.\;x \to_\alpha \lambda z.\;\lambda x.\;x\]A escolha pela abstração externa implica no risco de alteração semântica, correndo o risco de mudar o comportamento se o termo for parte de uma expressão maior que referencia $x$. Outro risco está na perda de informação estrutural. Isso será percebido após a aplicação, redução-$\beta$, ($\lambda x.\;x$), perde-se a informação sobre a abstração dupla original. Existe ainda possibilidade de criarmos uma confusão de escopos que pode acarretar uma interpretações errônea sobre qual variável está sendo referenciada em contextos mais amplos.
Há uma razão puramente empírica. A escolha pela abstração externa contraria as práticas comuns ao cálculo lambda, no qual as variáveis externas geralmente permanecem estáveis. Por fim, a escolha pela abstração externa reduz a rastreabilidade das transformações em sistemas de tipos ou em sistemas de análise estáticas.
A perspicaz leitora deve ter percebido o esforço para justificar a aplicação da redução-$\alpha$ a abstração interna. Agora que a convenci, podemos fazer a aplicando, β-redução, após a abordagem 1:
\[(\lambda x.\;\lambda z.\;z)\;y \to_\beta \lambda z.\;z\]Esta redução resulta em uma expressão que preserva a estrutura essencial do termo original, mantendo a abstração interna intacta e substituindo a variável externa, conforme esperado na semântica do cálculo lambda.
redução Beta
A redução beta é o mecanismo de computação do cálculo lambda que permite simplificar expressões por meio da aplicação de funções aos seus argumentos. As outras reduções $\beta$ e $\eta$ são mecanismos de transformação que facilitam, ou possibilitam, a redução-$beta$.Formalmente, a redução beta é definida como:
\[(\lambda x.\;E)\;N \to_\beta [x/N]E\]A notação $[x/N]M$ representa a substituição de todas as ocorrências livres da variável $x$ no termo $E$ pelo termo $N$. Eventualmente, quando estudamos semântica denotacional, ou provas formais, usamos a notação $E[x := y]$.
A substituição indicada em uma redução-$beta$ deve ser realizada com cuidado para evitar a captura de variáveis livres em $N$ que possam se tornar ligadas em $E$ após a substituição. Para evitar a captura de varáveis livres, pode ser necessário realizar uma redução-$\alpha$ antes de começar a redução beta, renomeando variáveis ligadas em $E$ que possam entrar em conflito com variáveis livres em $N$, Figura 3.2.A.
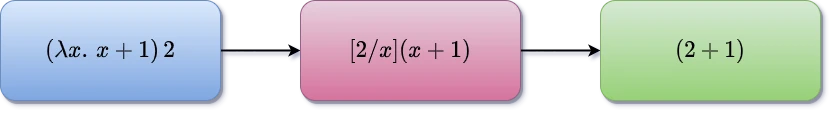 3.2.A: Exemplo de Redução Beta
3.2.A: Exemplo de Redução Beta
Considere, por exemplo, o termo $E = (\lambda y.\;x + y)$ e o objetivo de substituir $x$ por $N = y$. Se fizermos a substituição diretamente, obteremos:
\[[x/y]E = (\lambda y.\;y + y)\]Nesse caso, a variável livre $y$ em $N$ tornou-se ligada devido ao $\lambda y$ em $E$, resultando em captura de variável e alterando o significado original da expressão. Para evitar a captura, aplicamos uma redução-$\alpha$ ao termo $E$, renomeando a variável ligada $y$ para uma nova variável que não apareça em $N$, como $z$:
\[E = (\lambda y.\;x + y) \quad \rightarrow_\beta \quad (\lambda z.\;x + z)\]Agora, ao substituir $x$ por $y$, obtemos:
\[[x/y]E = (\lambda z.\;y + z)\]A variável livre $y$ permanece livre após a substituição, e a captura é evitada. Outro exemplo é o termo $E = (\lambda x.\;\lambda y.\;x + y)$ com $N = y$. Tentando substituir diretamente, temos:
\[[x/y]E = (\lambda y.\;y + y)\]Aqui, a variável livre $y$ em $N$ foi capturada pelo $\lambda y$ interno. Para prevenir isso, realizamos uma redução-$\alpha$ renomeando a variável ligada $y$ para $z$:
\[E = (\lambda x.\;\lambda y.\;x + y) \quad \xrightarrow{\text{alfa}} \quad (\lambda x.\;\lambda z.\;x + z)\]Procedendo com a substituição:
\[[x/y]E = (\lambda z.\;y + z)\]Assim, a variável livre $y$ não é capturada, preservando o significado da expressão original.
Em suma, ao realizar a substituição $[x/N]E$, é essencial garantir que as variáveis livres em $N$ permaneçam livres após a substituição e não sejam capturadas por variáveis ligadas em $E$. A persistente leitora deve avaliar os exemplos a seguir:
Exemplo 1: considere a expressão:
\[(\lambda x.\;x + y)\;3\]Aplicando a redução beta:
\[(\lambda x.\;x + y)\;3 \to_\beta 3 + y\]Neste caso, substituímos $x$ por $3$ no corpo da função $x + y$, resultando em $3 + y$. A variável $y$ permanece inalterada por ser uma variável livre.
Exemplo 2: se houver risco de captura de variáveis, é necessário realizar uma redução-$\alpha$ antes. Por exemplo:
\[(\lambda x.\;\lambda y.\;x + y)\;y\]Aplicando a redução beta diretamente:
\[(\lambda x.\;\lambda y.\;x + y)\;y \to_\beta \lambda y.\;y + y\]Aqui, a variável livre $y$ no argumento foi capturada pela variável ligada $y$ na função interna. Para evitar isso, realizamos uma redução-$\alpha$ renomeando a variável ligada $y$ para $z$:
\[\lambda x.\;\lambda z.\;x + z\]Agora podemos aplicar a redução beta:
\[(\lambda x.\;\lambda z.\;x + z)\;y \to_\beta \lambda z.\;y + z\]Assim, evitamos a captura da variável livre $y$, mantendo o significado original da expressão.
Exemplo 3: considere a expressão:
\[(\lambda x.\;x+1)2\]Aplicando a redução beta:
\[(\lambda x.\;x+1)2 \to_\beta [2/x]\;(x+1) \, = 2+1 = 3\]Aqui, o valor $2$ é substituído pela variável $x$ na expressão $x + 1$, resultando em $2 + 1 = 3$.
Redução Eta
A redução-$\eta$ é uma das três formas de redução no cálculo lambda, juntamente com as reduções alfa e beta. A redução-$\eta$ captura a ideia de extensionalidade, permitindo simplificar termos que representam a mesma função pelo comportamento externo. Formalmente, a redução-$\eta$ é definida pela seguinte regra:
\[\lambda x.\;f\;x \to_\eta f \quad \text{se } x \notin \text{FV}(f)\]Neste caso, esta expressão é formada por: uma função $\lambda x.\;f\;x$ que recebe um argumento $x$ e aplica a função $f$ a $x$; $\text{FV}(f)$ representa o conjunto de variáveis livres em $f$ e a condição $x \notin \text{FV}(f)$ garante que $x$ não aparece livre em $f$, evitando a captura de variáveis.
A redução-$\eta$ permite eliminar a abstração $\lambda x$ quando a função aplica $f$ diretamente a $x$, resultando que $\lambda x.\;f\;x$ é equivalente a comportamentalmente a $f$. Isso ocorre quando $x$ não aparece livre em $f$, garantindo que a eliminação da abstração não altera o significado do termo. Podemos dizer que a redução-$\eta$ expressa o princípio de que duas funções são iguais se, para todos os argumentos, elas produzem os mesmos resultados. Se uma função $\lambda x.\;f\;x$ aplica $f$ diretamente ao seu argumento $x$, e $x$ não aparece livre em $f$, então $\lambda x.\;f\;x$ pode ser reduzido a $f$.
Exemplo 1: Considere o termo:
\[\lambda x.\;f\;x\]Se $f = \lambda y.\;y + 2$ e $x$ não aparece livre em $f$, a redução-$\eta$ pode ser aplicada:
\[\lambda x.\;f\;x \to_\eta f = \lambda y.\;y + 2\]Assim, $\lambda x.\;f\;x$ reduz-se a $f$.
Exemplo 2: Considere o termo:
\[\lambda x.\;(\lambda y.\;y^2)\;x\]Como $x$ não aparece livre em $f = \lambda y.\;y^2$, a redução-$\eta$ pode ser aplicada:
\[\lambda x.\;f\;x \to_\eta f = \lambda y.\;y^2\]Portanto, $\lambda x.\;(\lambda y.\;y^2)\;x$ reduz-se a $\lambda y.\;y^2$.
Se $x$ aparece livre em $f$, a redução-$\eta$ não é aplicável, pois a eliminação de $\lambda x$ alteraria o comportamento do termo. Por exemplo, se $f = \lambda y.\;x + y$. Neste caso, $x$ é uma variável livre em $f$, então:
\[\lambda x.\;f\;x = \lambda x.\;(\lambda y.\;x + y)\;x \to_\beta \lambda x.\;x + x\]Neste caso, não é possível aplicar a redução-$\eta$ para obter $f$, pois $x$ aparece livre em $f$, e remover $\lambda x$ deixaria $x$ indefinida.
A condição $x \notin \text{FV}(f)$ é fundamental. Se $x$ aparecer livre em $f$, a redução-$\eta$ não pode ser aplicada, pois a remoção da abstração $\lambda x$ poderia alterar o significado do termo.
Exemplo Contrário: Considere a expressão:
\[\lambda x.\;x\;x\]Aqui, $x$ aparece livre no corpo $x\;x$. Não podemos aplicar a redução-$\eta$ para obter $x$, pois isso alteraria o comportamento da função.
Propriedade de Extensionalidade
A redução-$\eta$ está relacionada ao conceito de extensionalidade em matemática. Neste conceito, duas funções são consideradas iguais se produzem os mesmos resultados para todos os argumentos. No cálculo lambda, a redução-$\eta$ formaliza esse conceito, permitindo a simplificação de funções que são extensionais.
Em matemática, o conceito de extensionalidade refere-se à ideia de que dois objetos são considerados iguais se têm as mesmas propriedades externas ou observáveis. No contexto das funções, a extensionalidade implica que duas funções $f$ e $g$ são consideradas iguais se, para todo argumento $x$ em seu domínio comum, $f(x) \, = g(x)$. Isso significa que a identidade de uma função é determinada pelos seus valores de saída para cada entrada possível, e não pela sua definição interna ou pela forma como é construída.
A extensionalidade é um princípio em várias áreas da matemática, incluindo teoria dos conjuntos e lógica matemática. Na teoria dos conjuntos, o axioma da extensionalidade afirma que dois conjuntos são iguais se e somente se contêm exatamente os mesmos elementos. No cálculo lambda e na programação funcional, a extensionalidade se manifesta através de conceitos como a redução-$\eta$, que permite tratar funções que produzem os mesmos resultados para todas as entradas como equivalentes, independentemente de suas estruturas internas.
Para ilustrar o conceito de extensionalidade e sua relação com a redução-$\eta$, a esforçada leitora deve considerar os seguintes exemplos:
Exemplo 1: Suponha que temos duas funções no cálculo lambda:
\[f = \lambda x.\;x^2 + 2x + 1\]e
\[g = \lambda x.\;(x + 1)^2\]Embora $f$ e $g$ tenham definições diferentes, podemos demonstrar que elas produzem o mesmo resultado para qualquer valor de $x$:
\[f(x) \, = x^2 + 2x + 1 \\ g(x) \, = (x + 1)^2 = x^2 + 2x + 1\]Portanto, para todo $x$, $f(x) \, = g(x)$, o que significa que $f$ e $g$ são extensionais, apesar de suas diferentes expressões internas.
Exemplo 2: Considere as funções:
\[h = \lambda x.\;f\;x \\ k = f\]Se $x$ não aparece livre em $f$, a redução-$\eta$ nos permite afirmar que $h$ é equivalente a $k$:
\[h = \lambda x.\;f\;x \to_\eta f = k\]Isso mostra que, embora $h$ seja definido como uma função que aplica $f$ a $x$, ela é extensionamente igual a $f$ em si, reforçando o princípio de que a forma interna da função é menos relevante do que seu comportamento externo.
Teorema de Church-Rosser
Um dos obstáculos enfrentado por Church durante o desenvolvimento do cálculo lambda dizia respeito a consistência do processo de redução. Ou seja, provar que um termo lambda mesmo que reduzido de formas diferentes, chegaria a mesma forma normal, caso esta forma existisse. Em busca desta consistência, Church e J. Barkley Rosser, seu estudante de doutorado, formularam o teorema que viria a ser chamado de Teorema de Church-Rosser2. Este teorema, chamado de propriedade da confluência local, garante a consistência e a previsibilidade do sistema de redução beta, afirmando que, independentemente da ordem em que as reduções beta são aplicadas, o resultado\;se existir, é o mesmo Figura 3.4.A.
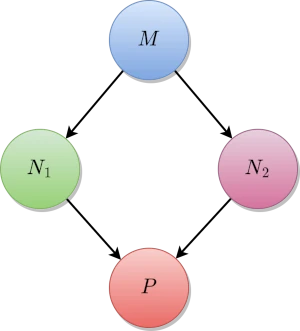
Figura 3.4.A: Diagrama da Propriedade de Confluência determinada pelo Teorema de Church-Rosser
Formalmente teremos:
\[\forall M, N_1, N_2\;(\text{se}\;M \twoheadrightarrow_\beta N_1\;\text{e}\;M \twoheadrightarrow_\beta N_2,\;\text{então existe um}\;P\;\text{tal que}\;N_1 \twoheadrightarrow_\beta P\;\text{e}\;N_2 \twoheadrightarrow_\beta P).\]Ou:
\[(M \twoheadrightarrow_\beta N_1 \land M \twoheadrightarrow_\beta N_2) \implies \exists P\;(N_1 \twoheadrightarrow_\beta P \land N_2 \twoheadrightarrow_\beta P)\]O símbolo $\twoheadrightarrow_\beta$ representa uma sequência, possivelmente vazia, de reduções beta. Com um pouco menos de formalidade, podemos ler o enunciado do Teorema de Church-Rosser como:
Se um termo $M$ pode ser reduzido a $N_1$ e $N_2$ exclusivamente em um passo, então existe um termo $P$ tal que $N_1$ e $N_2$ podem ser reduzidos a $P$.
A prova de Barendregt utiliza o Lema de Newman, que afirma que um sistema de reescrita é confluentemente terminante se for fortemente normalizante e localmente confluentemente terminante. A prova pode ser dividida em três partes principais:
- Confluência Local: a confluência local é definida da seguinte forma:
Se $M$ é um termo no cálculo lambda e pode ser reduzido em um passo para dois termos distintos $N_1$ e $N_2$, então existe um termo comum $ P$ tal que $N_1$ e $N_2$ podem ser reduzidos em um número finito de passos para $P$. Formalmente:
\[M \rightarrow N_1 \quad \text{e} \quad M \rightarrow N_2 \implies \exists P \, : \, N_1 \twoheadrightarrow P \quad \text{e} \quad N_2 \twoheadrightarrow P\]Por exemplo: considere o termo $ M = (\lambda x. x\;x) (\lambda x. x\;x)$. Esse termo pode ser reduzido de duas formas diferentes:
Redução da aplicação externa: $(\lambda x.\;x\;x) (\lambda x.\;x\;x) \rightarrow (\lambda x.\;x\;x) (\lambda x.\;x\;x)$ (permanece o mesmo)
Redução da aplicação interna: $(\lambda x.\;x\;x) (\lambda x.\;x\;x) \rightarrow (\lambda x.\;x\;x)$
No entanto, ambos os caminhos eventualmente se reduzem ao mesmo termo $(\lambda x.\;x\;x)$, o que ilustra a confluência local.
Confluência Global: a confluência global é estabelecida ao aplicar o Lema de Newman, que afirma que:
Se um sistema de reescrita é fortemente normalizante, ou seja, todas as sequências de reduções terminam em um termo normal, e
Se o sistema é localmente confluentemente terminante, então ele é globalmente confluentemente terminante.
Para aplicar o Lema de Newman no cálculo lambda, é necessário provar duas coisas: a Normalização forte, todos os termos no cálculo lambda podem eventualmente ser reduzidos a uma forma normal (caso exista) e a Confluência local, que demonstrei anteriormente.
Como o cálculo lambda satisfaz ambas as condições, ele é confluente e terminante globalmente.
A prova completa envolve mostrar que, mesmo quando existem múltiplos >redexes, subtermos que podem ser reduzidos, a ordem de redução não interfere no resultado . Barendregt utiliza as técnicas de reescrita paralela e substituição simultânea para lidar com as reduções múltiplas.
A reescrita paralela envolve a ideia de aplicar todas as reduções possíveis de um termo ao mesmo tempo. Por exemplo, se um termo $M$ contém dois redexes diferentes, como $(\lambda x.\;x)\;(\lambda y.\;y)$, a reescrita paralela reduz ambos os redexes simultaneamente:
\[M = (\lambda x.\;x)\;(\lambda y.\;y) \rightarrow (\lambda y.\;y)\]Essa abordagem simplifica a prova de confluência, pois elimina a necessidade de considerar todas as possíveis sequências de redução.
Já substituição simultânea é usada para manter a consistência ao aplicar várias reduções ao mesmo tempo. Por exemplo, se temos um termo $(\lambda x.\;M)\;N$, a substituição simultânea permite que o termo $M[N/x]$ seja avaliado sem considerar ordens de substituição diferentes.
A prova de confluência de Barendregt é considerada elegante devido à sua simplicidade e clareza ao estruturar a demonstração de confluência no cálculo lambda. Notadamente porque: assegura a consistência do cálculo lambda, permite que linguagens de programação baseadas no cálculo lambda sejam previsíveis e determinísticas e tem implicações diretas na teoria da prova, nas linguagens de programação funcional e na lógica computacional. 3
O Teorema de Church-Rosser ao estabelecer que o cálculo lambda é um sistema confluente, estabelece que, embora possam existir diferentes caminhos de redução a partir de um termo inicial, todos os caminhos levam a um resultado comum. além de provar a consistência do cálculo lambda, O Teorema de Church-Rosser teve impacto na prova da existência da unicidade da forma normal e da independência da estratégia de redução.
Finalmente podemos dizer que o cálculo lambda puro é consistente porque como não é possível derivar termos contraditórios, ou ambíguos. A consistência, por sua vez, implica na confiabilidade em sistemas formais e linguagens de programação funcionais.
Por sua vez, a Unicidade da Forma Normal é uma consequência imediata da consistência. Se um termo $M$ possui uma forma normal, um termo irredutível, então essa forma normal é única. Isso assegura que o processo de computação no cálculo lambda é determinístico em termos do resultado . Até aqui, vimos que o cálculo lambda é consistente e determinístico.
A última consequência do Teorema de Church-Rosser, a Independência da Estratégia de Redução garante que a ordem, ou estratégia, com que as reduções beta são aplicadas não afeta a forma normal final de um termo. Isso permite flexibilidade na implementação de estratégias de avaliação, como avaliação preguiçosa (lazy evaluation) ou avaliação estrita (eager evaluation).
Finalmente, podemos dizer que o Teorema de Church-Rosser é o suporte necessário para que a amável leitora possa entender que o cálculo lambda é consistente, determinístico e flexível. A esforçada leitora de acompanhar os seguintes exemplos:
Exemplo 1: redução de uma Função Aplicada a Dois Argumentos. Considere o termo:
\[M_1 = (\lambda x.\;(\lambda y.\;x + y))\;3\;2\]Caminho 1: reduza o termo externo primeiro:
\[M_1 = (\lambda x.\;(\lambda y.\;x + y))\;3\;2\] \[\to_\beta (\lambda y.\;3 + y)\;2\]Agora, aplique a segunda função:
\[\to_\beta 3 + 2 = 5\]Caminho 2: reduza o termo interno primeiro:
\[M_1 = (\lambda x.\;(\lambda y.\;x + y))\;3\;2\] \[\to_\beta (\lambda x.\;(\lambda y.\;x + y))\;3\]Reduza o termo externo:
\[\to_\beta (\lambda y.\;3 + y)\;2\]Finalmente, aplique a segunda função:
\[\to_\beta 3 + 2 = 5\]Neste exemplo, ambos os caminhos de redução resultam na forma normal $5$.
Exemplo 2: redução de uma Função de Ordem Superior. Considere o termo:
\[M_2 = (\lambda f.\;(\lambda x.\;f (f x)))\;(\lambda y.\;y + 1)\;1\]Caminho 1: reduza o termo externo primeiro:
\[M_2 = (\lambda f.\;(\lambda x.\;f (f x)))\;(\lambda y.\;y + 1)\;1\] \[\to_\beta (\lambda x.\;(\lambda y.\;y + 1)\;((\lambda y.\;y + 1)\;x))\;1\]Aplique a função interna:
\[\to_\beta (\lambda y.\;y + 1)\;((\lambda y.\;y + 1)\;1)\]Aplique a primeira função:
\[\to_\beta (\lambda y.\;y + 1)\;(1 + 1)\]Aplique a segunda função:
\[\to_\beta 2 + 1 = 3\]Caminho 2: reduza o termo interno primeiro:
\[M_2 = (\lambda f.\;(\lambda x.\;f (f x)))\;(\lambda y.\;y + 1)\;1\] \[\to_\beta (\lambda f.\;(\lambda x.\;f (f x)))\;(\lambda y.\;y + 1)\]Aplique a função externa:
\[\to_\beta (\lambda x.\;(\lambda y.\;y + 1)\;((\lambda y.\;y + 1)\;x))\;1\]Agora, aplique a função interna:
\[\to_\beta (\lambda y.\;y + 1)\;((\lambda y.\;y + 1)\;1)\]Aplique a primeira função:
\[\to_\beta (\lambda y.\;y + 1)\;(1 + 1)\]Aplique a segunda função:
\[\to_\beta 2 + 1 = 3\]Neste exemplo, ambos os caminhos de redução resultam na forma normal $3$.
Exemplo 3: considere o termo lambda:
\[M = (\lambda x.\;x\;x) (\lambda x.\;x\;x)\]Este termo pode ser reduzido de formas diferentes:
Caminho 1: reduza o termo externo primeiro:
\[\begin{align*} M &= (\lambda x.\;x\;x) (\lambda x.\;x\;x) \\ &\to_\beta (\lambda x.\;x\;x) (\lambda x.\;x\;x) \end{align*}\]Se tomarmos o caminho 1, este processo continuará indefinidamente, indicando que não há forma normal.
Caminho 2: reduza o termo interno primeiro:
\[\begin{align*} M &= (\lambda x.\;x\;x) (\lambda x.\;x\;x) \\ &\to_\beta (\lambda x.\;x\;x) (\lambda x.\;x\;x) \end{align*}\]Novamente, o processo é infinito e não temos uma forma normal.
Neste caso, ambos os caminhos levam a um processo de redução infinito, mas o Teorema de Church-Rosser assegura que, se houvesse uma forma normal, ela seria única, independentemente do caminho escolhido.
A confluência garantida pelo Teorema de Church-Rosser é análoga a um rio com vários afluentes que eventualmente convergem para o mesmo oceano. Ou se preferir a antiga expressão latina Omnes viae Romam ducunt Não importa qual caminho a água siga, ou que estrada a nômade leitora pegue, ela acabará chegando ao mesmo destino. No contexto do cálculo lambda, isso significa que diferentes sequências de reduções beta não causam ambiguidades no resultado da computação.
Currying
O cálculo Lambda assume intrinsecamente que uma função possui um único argumento. Esta é a ideia por trás da aplicação. Como a atenta leitora deve lembrar: dado um termo $M$ visto como uma função e um argumento $N$, o termo $(M\;N)$ representa o resultado de aplicar $M$ ao argumento $N$. A avaliação é realizada pela redução-$\beta$.
Embora o cálculo lambda defina funções unárias estritamente, aqui, não nos limitaremos a essa regra para facilitar o entendimento dos conceitos de substituição e aplicação.
O conceito de _currying_vem do trabalho do matemático Moses Schönfinkel, que iniciou o estudo da lógica combinatória nos anos 1920. Mais tarde, Haskell Curry popularizou e expandiu essas ideias. O cálculo lambda foi amplamente influenciado por esses estudos, tornando o _currying_uma parte essencial da programação funcional e da teoria dos tipos.
Por exemplo, uma função de dois argumentos $f(x, y)$ pode ser convertida em uma sequência de funções $f’(x)(y)$. Aqui, $f’(x)$ retorna uma nova função que aceita $y$ como argumento. Assim, uma função que requer múltiplos parâmetros pode ser aplicada parcialmente, fornecendo alguns argumentos de cada vez, resultando em uma nova função que espera os argumentos restantes. Ou, com um pouco mais de formalidade: uma função de $n$ argumentos é vista como uma função de um argumento que toma uma função de $n - 1$ argumentos como argumento.
Considere uma função $f$ que aceita dois argumentos: $f(x, y)$ a versão currificada desta função será:
\[F = \lambda x.(\lambda y.\;; f(x, y))\]Agora, $F$ é uma função que aceita um argumento $x$ e retorna outra função que aceita $y$. Podemos ver isso com um exemplo: suponha que temos uma função que soma dois números: $soma(x, y) = x + y$. A versão currificada seria:
\[add = \lambda x.\;(\lambda y.\;(x + y))\]Isso significa que $add$ é uma função que recebe um argumento $x$ e retorna outra função $\lambda y.(\;x + y)$. Esta função resultante espera um segundo argumento $y$ para calcular a soma de $x$ e $y$.
Quando aplicamos $add$ ao argumento $3$, obteremos:
\[(add \; 3) = (\lambda x.\;(\lambda y.\;(x + y))) \; 3\]Nesse ponto, estamos substituindo $x$ por $3$ na função externa, resultando em:
\[\lambda y.\;(3 + y)\]Isso é uma nova função que espera um segundo argumento $y$. Agora, aplicamos o segundo argumento, $4$, à função resultante:
\[(\lambda y.\;(3 + y))\;4\]Substituímos $y$ por $4$, obtendo:
\[3 + 4\]Finalmente:
\[7\]Assim, $(add \;3) \;4$ é avaliado para $7$ após a aplicação sequencial de argumentos à função currificada. A Figura 3.5.A, apresenta a aplicação $(add \; 3) = (\lambda x.\;(\lambda y.\;(x + y))) \; 3$ que explicamos acima.
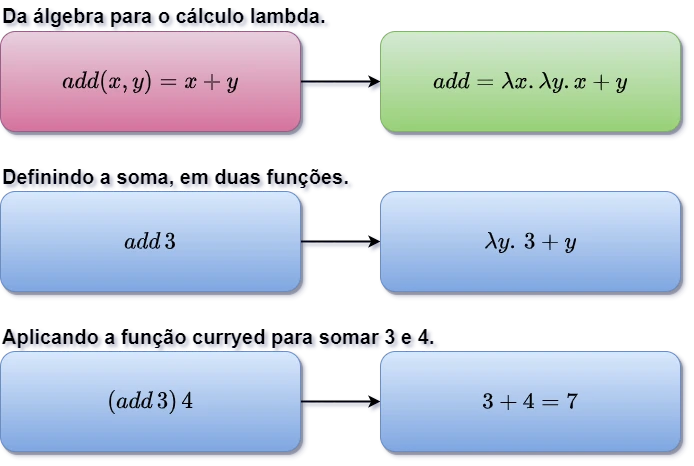 _Figura 3.5.A: Diagrama mostrando o processo de currying_em Cálculo lambda
_Figura 3.5.A: Diagrama mostrando o processo de currying_em Cálculo lambda
No currying, uma função que originalmente recebe dois argumentos, como $f: \mathbb{N} \times \mathbb{N} \rightarrow \mathbb{N}$, é transformada em uma função que recebe um argumento e retorna outra função. O resultado é uma função da forma $f’: \mathbb{N} \rightarrow (\mathbb{N} \rightarrow \mathbb{N})$. Assim, $f’$ recebe o primeiro argumento e retorna uma nova função que espera o segundo argumento para realizar o cálculo final.
Podemos representar essa transformação de forma mais abstrata usando a notação da teoria dos conjuntos. Uma função que recebe dois argumentos é representada como $\mathbb{N}^{\mathbb{N} \times \mathbb{N}}$, o que significa “o conjunto de todas as funções que mapeiam pares de números naturais para números naturais”. Quando fazemos currying, essa função é transformada em $(\mathbb{N}^{\mathbb{N}})^{\mathbb{N}}$, o que significa “o conjunto de todas as funções que mapeiam um número natural para outra função que, por sua vez, mapeia um número natural para outro”. Assim, temos uma cadeia de funções aninhadas.
Podemos fazer uma analogia com a álgebra:
\[(m^n)^p = m^{n \cdot p}\]Aqui, elevar uma potência a outra potência equivale a multiplicar os expoentes. Similarmente, no currying, estruturamos as funções de forma aninhada, mas o resultado é equivalente, independentemente de aplicarmos todos os argumentos de uma vez ou um por um. Portanto, o currying cria um isomorfismo entre as funções dos tipos:
\[f : (A \times B) \to C\]e
\[g : A \to (B \to C)\]Este isomorfismo significa que as duas formas são estruturalmente equivalentes e podem ser convertidas uma na outra sem perda de informação ou alteração do comportamento da função. A função $f$ que recebe um par de argumentos $(a, b)$ é equivalente à função $g$ que, ao receber $a$, retorna uma nova função que espera $b$, permitindo que os argumentos sejam aplicados um por vez.
Ordem Normal e Estratégias de Avaliação
A ordem em que as reduções beta são aplicadas pode afetar tanto a eficiência quanto a terminação do cálculo. Existem duas principais estratégias de avaliação:
-
Ordem Normal: Sempre reduz o redex mais externo à esquerda primeiro. Essa estratégia garante encontrar a forma normal de um termo, se ela existir. Na ordem normal, aplicamos a função antes de avaliar seus argumentos.
-
Ordem Aplicativa: Nesta estratégia, os argumentos são reduzidos antes da aplicação da função. Embora mais eficiente em alguns casos, pode não terminar em expressões que a ordem normal resolveria.
Talvez a atenta leitora entenda melhor vendo as reduções sendo aplicadas:
\[(\lambda x.\;y)(\lambda z.\;z\;z)\]-
Ordem Normal: A função $(\lambda x.\;y)$ é aplicada diretamente ao argumento $(\lambda z.\;z\;z)$, resultando em:
\[(\lambda x.\;y)(\lambda z.\;z\;z) \to_\beta y\]
Aqui, não precisamos avaliar o argumento, pois a função simplesmente retorna $y$.
-
Ordem Aplicativa: Primeiro, tentamos reduzir o argumento $(\lambda z.\;z\;z)$, resultando em uma expressão que se auto-aplica indefinidamente, causando um loop infinito:
\[(\lambda x.\;y)(\lambda z.\;z\;z) \to_\beta (\lambda x.\;y)((\lambda z.\;z\;z)(\lambda z.\;z\;z)) \to_\beta ...\]
Este exemplo mostra que a ordem aplicativa pode levar a uma não terminação em termos nos quais a ordem normal poderá encontrar uma solução.
Combinadores e Funções Anônimas
Os combinadores tem origem no trabalho de Moses Schönfinkel. Em um artigo de 1924 Moses Schönfinkel define uma família de combinadores incluindo os combinadores padrão $S$, $K$ e $I$ e demonstra que apenas $S$ e $K$ são necessários[\^cite3]. Um conjunto dos combinadores iniciais pode ser visto na Tabela 3.6.A:
| Abreviação Original | Função Original em Alemão | Tradução para o Inglês | Expressão Lambda | Abreviação Atual |
|---|---|---|---|---|
| $I$ | Identitätsfunktion | função identidade | $\lambda x.\;x$ | $I$ |
| $K$ | Konstanzfunktion | função de constância | $\lambda\;y\;x.\;x$ | $C$ |
| $T$ | Vertauschungsfunktion | função de troca | $\lambda\;y\;xz.\;z\;y\;x$ | $C$ |
| $Z$ | Zusammensetzungsfunktion | função de composição | $\lambda\;y\;xz.\;xz(yz)$ | $B$ |
| $S$ | Verschmelzungsfunktion | função de fusão | $\lambda\;y\;xz.\;xz(yz)$ | $S$ |
Tabela 3.6.A: Relação dos Combinadores Originais.
A Figura 3.6.A mostra as definições dos combinadores $I$, $K$, $S$, e uma aplicação de exemplo de cada um.
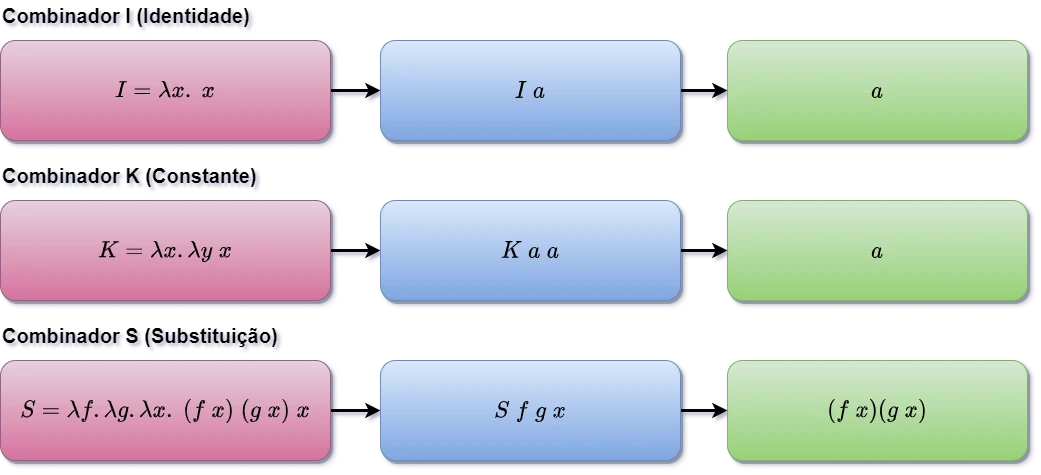 Figura 3.6.A: Definição e Aplicação dos Combinadores $I$, $K$, $S${: class=”legend”}
Figura 3.6.A: Definição e Aplicação dos Combinadores $I$, $K$, $S${: class=”legend”}
Schönfinkel apresentou combinadores para representar as operações da lógica de primeiro grau, um para o traço de Sheffer, NAND, descoberto em 1913, e outro para a quantificação.
Em funções booleanas e no cálculo proposicional, o traço de Sheffer é uma operação lógica que representa a negação da conjunção. Essa operação é expressa em linguagem comum como não ambos. Ou seja, dados dois operandos, ao menos um deles deve ser falso. Em termos técnicos, essa operação é chamada de não-conjunção, negação alternativa ou NAND, dependendo do texto no qual estão sendo analisados. Esta operação simplesmente nega a conjunção dos operandos e esta é a origem da nomenclatura NAND a abreviação de Not AND.
Esta operação foi introduzida pelo filósofo e lógico Henry Maurice Sheffer, por isso o nome, em 1913.
O trabalho que definiu o traço de Sheffer demonstrou que todas as operações booleanas podem ser expressas usando somente a operação NAND, simplificando a lógica proposicional. Em lógica de primeira ordem representamos esta a operação NAND por $ \mid $, $\uparrow$, ou $\overline{\wedge}$. Não é raro que neófitos confundam a representação do traço de Sheffer com $ \vert \vert $, que normalmente é usado para representar disjunção. A precavida leitora deve tomar cuidado com isso.
Formalmente, a operação $p \mid q$ pode ser expressa como:
\[p \mid q = \neg (p \land q)\]Indicando que a operação do Traço de Sheffer é verdadeira quando a proposição $p \land q$ é falsa. Quando não ambos $p$ e $q$ são verdadeiros.
O Traço de Sheffer possuí as seguintes propriedades:
Universalidade: a operação NAND é uma operação lógica universal, significando que qualquer função booleana pode ser construída apenas com NANDs. Isso é particularmente importante em eletrônica digital. A popularidade dessa porta em circuitos digitais se deve à sua versatilidade e à sua implementação relativamente simples em termos de hardware.
Identidade: O traço de Sheffer é auto-dual e pode representar qualquer outra operação lógica. Podemos representar a disjunção, a conjunção, a negação, o condicional ou a bicondicional através de combinações específicas de NANDs.
A importância da NAND pode ser verificada construindo uma operação de negação ($\neg p$) usando o traço de Sheffer, podemos fazê-lo com a seguinte expressão:
\[\neg p = p \mid p\]Neste caso, $p \mid p$ significa “não ambos $p$ e $p$”, ou seja, simplesmente $\neg p$.
$p$ $p \mid p$ $\neg p$ V F F F V V Quando $p$ é verdadeiro ($V$): $p \mid p$ é falso, pois o operador NAND aplicado a dois valores verdadeiros resulta em falso. Portanto, $\neg p$ é falso. Quando $p$ é falso ($F$): $p \mid p$ é verdadeiro, pois o operador NAND aplicado a dois valores falsos resulta em verdadeiro. Portanto, $\neg p$ é verdadeiro.
Este exemplo simples ilustra como a operação NAND pode ser usada como um bloco de construção para criar outras operações lógicas.
Schönfinkel, inspirado em Sheffer, buscou reduzir a lógica de predicados ao menor número possível de elementos, e, anos mais tarde, descobriu-se que os quantificadores para todo e existe da lógica de predicados se comportam como abstrações lambda.
O que Schönfinkel e seus sucessores descobriram é que os quantificadores universais ($\forall$) e existenciais ($\exists$) podem ser modelados como abstrações lambda. A estrutura da lógica de predicados é compatível com as regras de abstração e aplicação do cálculo lambda.
O quantificador universal $\forall x. P(x)$ pode ser interpretado como uma função que, dada uma variável $x$, retorna verdadeiro para todos os valores de $x$ que satisfazem $P(x)$. Esta interpretação esta alinhada com o conceito de abstração lambda, na qual uma função recebe um argumento e retorna um valor dependendo desse argumento. Em termos de cálculo lambda, poderíamos expressar o quantificador universal:
\[\forall x. P(x) \equiv (\lambda x. P(x))\]Aqui, a função $\lambda x. P(x)$ é uma abstração que, para cada $x$, verifica a verdade de $P(x)$.
Da mesma forma, o quantificador existencial $\exists x. P(x)$ pode ser interpretado como a aplicação de uma função que verifica se existe algum valor de $x$ que torna $P(x)$ verdadeiro. Novamente, isso pode ser modelado como uma abstração lambda:
\[\exists x. P(x) = (\lambda x. \neg P(x))\]Essa correspondência revela a natureza fundamental das abstrações lambda e sua aplicação além do cálculo lambda puro.
Para nós, neste momento, um combinador é uma expressão lambda fechada, ou seja, sem variáveis livres. Isso significa que todas as variáveis usadas no combinador estão ligadas dentro da própria expressão.
A perceptiva leitora deve observar que o poder dos combinadores surge de que eles permitem criar funções complexas usando blocos simples, sem a necessidade de referenciar variáveis externas aos blocos.
Começamos com o combinador $K$, definido como:
\[K = \lambda x.\lambda y.\;x\]Este combinador é uma função de duas variáveis que sempre retorna o primeiro argumento, ignorando o segundo. Ele representa o conceito de uma função constante. As funções constante sempre retornam o mesmo valor. No cálculo lambda o combinador $K$ sempre retorna o primeiro argumento independentemente do segundo.
Por exemplo, $KAB$ reduz para $A$, sem considerar o valor de $B$:
\[KAB = (\lambda x.\lambda y.x)AB \rightarrow_\beta (\lambda y.A)B \rightarrow_\beta A\]Os três combinadores, a seguir, são referenciados como básicos e estruturais para a definição de funções compostas em cálculo lambda:
1.Combinador I (Identidade):
\[I = \lambda x.\;x\]O combinador identidade retorna o valor que recebe como argumento, sem modificá-lo.
Exemplo: aplicando o combinador $I$ a qualquer valor, ele retornará esse mesmo valor:
\[I\;5 \rightarrow_\beta 5\]Outro exemplo:
\[I\;(\lambda y.\;y + 1) \rightarrow_\beta \lambda y.\;y + 1\]2.Combinador K (ou C de Constante):
\[K = \lambda x.\lambda y.x\]Este combinador ignora o segundo argumento e retorna o primeiro.
Exemplo: Usando o combinador $K$ com dois valores:
\[K\;7\;4 \rightarrow_\beta (\lambda x.\lambda y.\;x)\;7\;4 \rightarrow_\beta (\lambda y.\;7)\;4 \rightarrow_\beta 7\]Aqui, o valor $7$ é retornado, e o valor $4$ ignorando.
3.Combinador S (Substituição):
\[S = \lambda f.\lambda g.\lambda x.\;fx(gx)\]Este combinador é mais complexo, pois aplica a função $f$ ao argumento $x$ e, simultaneamente, aplica a função $g$ a $x$, passando o resultado de $g(x)$ como argumento para $f$.
Exemplo: Vamos aplicar o combinador $S$ com as funções $f = \lambda z.\;z^2$ e $g = \lambda z.\;z + 1$, e o valor $3$:
\[S\;(\lambda z.\;z^2)\;(\lambda z.\;z + 1)\;3\]Primeiro, substituímos $f$ e $g$:
\[\rightarrow_\beta (\lambda x.(\lambda z.\;z^2)\;x\;((\lambda z.\;z + 1)\;x))\;3\]Agora, aplicamos as funções:
\[\rightarrow_\beta (\lambda z.\;z^2)\;3\;((\lambda z.\;z + 1)\;3)\] \[\rightarrow_\beta 3^2\;(3 + 1)\] \[\rightarrow_\beta 9\;4\]Assim, $S\;(\lambda z.\;z^2)\;(\lambda z.\;z + 1)\;3$ resulta em $9$.
No cálculo lambda as funções são anônimas. Desta forma, sempre é possível construir funções sem a atribuição nomes explícitos. Aqui estamos próximos da álgebra e longe das linguagens de programação imperativas, baseadas na Máquina de Turing. Isso é possível, como a atenta leitora deve lembrar, graças a existência das abstrações lambda:
\[\lambda x.\;(\lambda y.\;y)\;x\]A abstração lambda acima, representa uma função que aplica a função identidade ao seu argumento $x$. Nesse caso, a função interna $\lambda y.\;y$ é aplicada ao argumento $x$, e o valor resultante é simplesmente $x$, já que a função interna é a identidade. Estas funções inspiraram a criação de funções anônimas e alguns operadores em linguagens de programação imperativas. Como as funções arrow em JavaScript ou às funções lambdas em C++ e Python.
Os combinadores ampliam a utilidade das funções lambda e permitem a criação de funções complexas sem o uso de variáveis nomeadas. Esse processo, conhecido como abstração combinatória, elimina a necessidade de variáveis explícitas, focando em operações com funções. Podemos ver um exemplo de combinador de composição, denotado como $B$, definido por:
\[B = \lambda f.\lambda g.\lambda x.\;f\;(g\;x)\]Aqui, $B$ aplica a função $f$ ao resultado da função $g$, ambas aplicadas a $x$. Esse é um exemplo clássico de um combinador que não utiliza variáveis explícitas e demonstra o poder do cálculo lambda puro, no qual toda computação pode ser descrita através de combinações.
Podemos ver um outro exemplo na construção do combinador Mockingbird, ou $M$. Um combinador que aplica uma função a si mesma, definido por:
\[M = \lambda f.\;f\;f\]Sua função é replicar a aplicação de uma função sobre si mesma, o que é fundamental em certas construções dentro do cálculo lambda, mas não se relaciona com o comportamento do combinador de composição.
Exemplo 1: Definindo uma função constante com o combinador $K$
O combinador $K$ pode ser usado para criar uma função constante. A função criada sempre retorna o primeiro argumento, independentemente do segundo.
Definimos a função constante:
\[f = K\;A = \lambda x.\lambda y. ; x A = \lambda y.\;A\]Quando aplicamos $f$ a qualquer valor, o resultado é sempre $A$, pois o segundo argumento é ignorado.
Exemplo 2: Definindo a aplicação de uma função com o combinador $S$
O combinador $S$ permite aplicar uma função a dois argumentos e combiná-los. Ele pode ser usado para definir uma função que aplica duas funções diferentes ao mesmo argumento e, em seguida, combina os resultados.
Definimos a função composta:
\[f = S\;g\;h = \lambda x.\;(g x)(h x)\]Aqui, $g$ e $h$ são duas funções que recebem o mesmo argumento $x$. O resultado é a combinação das duas funções aplicadas ao mesmo argumento.
\[f A = (\lambda x.(g x)(h x)) A \rightarrow_\beta (g A)(h A)\]A remoção de variáveis nomeadas simplifica a computação. Este é um dos pontos centrais da teoria dos combinadores.
Em linguagens funcionais como Haskell, essa característica é usada para criar expressões modulares e compostas. Isso traz clareza e concisão ao código.
Estratégias de Redução
No cálculo lambda, a ordem em que as expressões são avaliadas define o processo de redução dos termos. As duas estratégias mais comuns para essa avaliação são a _estratégia normal e a estratégia aplicativa.
Na estratégia normal, as expressões mais externas são reduzidas antes das internas. Já na estratégia aplicativa, os argumentos de uma função são reduzidos primeiro, antes de aplicar a função.
Essas estratégias influenciam o resultado e o comportamento do processo de computação, especialmente em expressões que podem divergir ou não possuir valor definido. Vamos ver estas estratégias com atenção.
Ordem Normal (Normal-Order)
Na ordem normal, a redução prioriza o redex mais externo à esquerda (redução externa). Essa estratégia é garantida para encontrar a forma normal de um termo, caso ela exista. Como o argumento não é avaliado de imediato, é possível evitar o cálculo de argumentos que nunca serão utilizados, tornando-a equivalente à avaliação preguiçosa em linguagens de programação.
Uma vantagem da ordem normal é que sempre que encontramos a forma normal de um termo, se existir, podemos evitar a avaliação de argumentos desnecessários. Melhorando a eficiência do processo em termos de espaço.
Por outro lado, a ordem normal pode ser ineficiente em termos de tempo, já que, acabamos por reavaliar expressões várias vezes quando elas são necessárias repetidamente.
Exemplo 1: considere a expressão:
\[M = (\lambda f.\;(\lambda x.\;f\;(x\;x))\;(\lambda x.\;f\;(x\;x)))\;(\lambda y.\;y + 1)\]Vamos reduzir $M$ usando a ordem normal.
Passo 3: Identificamos o redex mais externo à esquerda:
\[\underline{(\lambda f.\;(\lambda x.\;f\;(x\;x))\;(\lambda x.\;f\;(x\;x)))\;(\lambda y.\;y + 1)}\]Aplicamos a redução beta ao redex, substituindo $f$ por $(\lambda y.\;y + 1)$:
\[\to_\beta (\lambda x.\;(\lambda y.\;y + 1)\;(x\;x))\;(\lambda x.\;(\lambda y.\;y + 1)\;(x\;x))\]Passo 2: Novamente, identificamos o redex mais externo à esquerda:
\[\underline{(\lambda x.\;(\lambda y.\;y + 1)\;(x\;x))\;(\lambda x.\;(\lambda y.\;y + 1)\;(x\;x))}\]Aplicamos a redução beta, substituindo $x$ por $(\lambda x.\;(\lambda y.\;y + 1)\;(x\;x))$:
\[\to_\beta (\lambda y.\;y + 1)\;\left( \underline{(\lambda x.\;(\lambda y.\;y + 1)\;(x\;x))\;(\lambda x.\;(\lambda y.\;y + 1)\;(x\;x))} \right)\]Passo 3: Dentro do argumento, identificamos o redex mais externo:
\[\underline{(\lambda x.\;(\lambda y.\;y + 1)\;(x\;x))\;(\lambda x.\;(\lambda y.\;y + 1)\;(x\;x))}\]Aplicamos a redução beta novamente, substituindo $x$ por $(\lambda x.\;(\lambda y.\;y + 1)\;(x\;x))$:
\[\to_\beta (\lambda y.\;y + 1)\;\left( (\lambda y.\;y + 1)\;\left( \underline{(\lambda x.\;(\lambda y.\;y + 1)\;(x\;x))\;(\lambda x.\;(\lambda y.\;y + 1)\;(x\;x))} \right) \right)\]Passo 4: Observamos que o processo está se repetindo. A cada aplicação da redução beta, o termo dentro dos parênteses permanece o mesmo, indicando um loop infinito:
\[\to_\beta (\lambda y.\;y + 1)\;\left( (\lambda y.\;y + 1)\;\left( (\lambda y.\;y + 1)\;\left( \cdots \right) \right) \right)\]Na estratégia de ordem normal, a redução do termo $M$ não termina, pois entra em um ciclo infinito de reduções. Não é possível alcançar uma forma normal para $M$ usando esta estratégia, já que continuaremos expandindo o termo indefinidamente sem simplificá-lo a um resultado . Este exemplo ilustra como a ordem normal pode levar a reduções infinitas em certos casos, especialmente quando lidamos com termos autoreferenciados ou combinadores que causam expansão infinita.
Observamos que a expressão começa a repetir a si mesma, indicando um ciclo infinito. Contudo, na ordem normal, como o argumento não é necessário para o resultado\;a redução pode ser concluída sem avaliá-lo.
Ordem Aplicativa (Applicative-Order)
Na ordem aplicativa, a estratégia de redução no cálculo lambda consiste em avaliar primeiro os argumentos de uma função antes de aplicar a função em si. Isso significa que a redução ocorre das partes mais internas para as mais externas (redução interna). Essa abordagem corresponde à avaliação estrita, onde os argumentos são completamente avaliados antes da aplicação da função.
A ordem aplicativa é utilizada em muitas linguagens de programação, especialmente nas imperativas e em algumas funcionais, como ML e Scheme. Uma vantagem dessa estratégia é que, quando o resultado de um argumento é utilizado várias vezes no corpo da função, a avaliação prévia evita reavaliações redundantes, podendo ser mais eficiente em termos de tempo. No entanto, a ordem aplicativa pode levar a problemas de não-terminação em casos nos quais a ordem normal encontraria uma solução. E pode resultar em desperdício de recursos ao avaliar argumentos que não são necessários para o resultado da função.
Exemplo 1: Considere a expressão:
\[M = (\lambda x.\;x)\;((\lambda y.\;y\;y)\;(\lambda y.\;y\;y))\]Na ordem aplicativa, avaliamos primeiro o argumento: Avaliamos o argumento $N = ((\lambda y.\;y\;y)\;(\lambda y.\;y\;y))$:
Aplicamos a redução beta:
\[(\lambda y.\;y\;y)\;(\lambda y.\;y\;y) \to_\beta (\lambda y.\;y\;y)\;(\lambda y.\;y\;y)\]Observamos que o termo se repete indefinidamente, resultando em uma redução infinita. Como o argumento não pode ser completamente avaliado, a aplicação da função não ocorre, e a redução não termina.
Na ordem normal, a função $(\lambda x.\;x)$ não utiliza o argumento além de retornar o próprio argumento. No entanto, na ordem aplicativa, a avaliação do argumento impede a conclusão da redução.
Exemplo 2: considere a expressão:
\[M = (\lambda x.\;\lambda y.\;x)\;\left( (\lambda z.\;z + 1)\;5 \right)\;\left( (\lambda w.\;w \times 2)\;3 \right)\]Na ordem aplicativa, procedemos da seguinte forma: avaliamos o primeiro argumento:
Calculamos $A = (\lambda z.\;z + 1)\;5$:
\[(\lambda z.\;z + 1)\;5 \to_\beta 5 + 1 = 6\]Avaliamos o segundo argumento:
Calculamos $B = (\lambda w.\;w \times 2)\;3$:
\[(\lambda w.\;w \times 2)\;3 \to_\beta 3 \times 2 = 6\]Aplicamos a função ao primeiro argumento avaliado:
\[(\lambda x.\;\lambda y.\;x)\;6 \to_\beta \lambda y.\;6\]Aplicamos a função resultante ao segundo argumento avaliado:
\[(\lambda y.\;6)\;6 \to_\beta 6\]O resultado é $6$. Note que ambos os argumentos foram avaliados, embora o segundo argumento não seja utilizado no resultado . Isso exemplifica como a ordem aplicativa pode desperdiçar recursos ao avaliar argumentos desnecessários.
Exemplo 3: considere a expressão:
\[M = (\lambda x.\;42)\;\left( (\lambda y.\;y\;y)\;(\lambda y.\;y\;y) \right)\]Na ordem aplicativa, avaliamos primeiro o argumento:
Avaliamos o argumento $N = (\lambda y.\;y\;y)\;(\lambda y.\;y\;y)$:
Aplicamos a redução beta:
\[(\lambda y.\;y\;y)\;(\lambda y.\;y\;y) \to_\beta (\lambda y.\;y\;y)\;(\lambda y.\;y\;y) \to_\beta \cdots\]O termo entra em uma redução infinita.
Como o argumento não pode ser completamente avaliado, a aplicação da função não ocorre, e a redução não termina. Na ordem normal, a função $(\lambda x.\;42)$ não utiliza o argumento $x$, portanto, o resultado seria imediatamente $42$, sem necessidade de avaliar o argumento que causa a não-terminação.
Exemplo 4: considere a expressão:
\[M = (\lambda f.\;f\;(f\;2))\;(\lambda x.\;x \times x)\]Na ordem aplicativa, procedemos assim:
Avaliamos o argumento $N = (\lambda x.\;x \times x)$, que é uma função e não requer avaliação adicional.
Aplicamos a função externa ao argumento:
\[(\lambda f.\;f\;(f\;2))\;(\lambda x.\;x \times x) \to_\beta (\lambda x.\;x \times x)\;((\lambda x.\;x \times x)\;2)\]Avaliamos o argumento interno $(\lambda x.\;x \times x)\;2$:
Aplicamos a redução beta:
\[(\lambda x.\;x \times x)\;2 \to_\beta 2 \times 2 = 4\]Aplicamos a função externa ao resultado:
\[(\lambda x.\;x \times x)\;4 \to_\beta 4 \times 4 = 16\]O resultado é $16$. Neste caso, a ordem aplicativa é eficiente, pois avalia os argumentos necessários e evita reavaliações.
A escolha entre ordem aplicativa e ordem normal depende do contexto e das necessidades específicas da computação. Em situações nas quais todos os argumentos são necessários e podem ser avaliados sem risco de não-terminação, a ordem aplicativa pode ser preferível. No entanto, quando há possibilidade de argumentos não terminarem ou não serem necessários, a ordem normal oferece uma estratégia mais segura.
Equivalência Lambda e Definição de Igualdade
No cálculo lambda, a noção de equivalência vai além da simples comparação sintática entre dois termos. Ela trata de quando dois termos podem ser considerados igualmente computáveis ou equivalentes em um sentido mais profundo, independentemente de suas formas superficiais. Esta equivalência tem impactos na otimizações de programas, verificação de tipos e raciocínio em linguagens funcionais.
Dois termos lambda $M$ e $N$ são considerados equivalentes, denotado por $M\to_\beta N$, se podemos transformar um no outro através de uma sequência, possivelmente vazia de:
-
$\alpha$-reduções: que permitem a renomeação de variáveis ligadas, assegurando que a identidade de variáveis internas não afeta o comportamento da função.
-
$\beta$-reduções: que representam a aplicação de uma função ao seu argumento, o princípio básico da computação no cálculo lambda.
-
$\eta$-reduções: que expressam a extensionalidade de funções, permitindo igualar duas funções que se comportam da mesma forma quando aplicadas a qualquer argumento.
Extensionalidade refere-se ao princípio de que objetos ou funções são iguais se têm o mesmo efeito em todos os contextos possíveis. Em lógica, duas funções são consideradas extensionais se, para todo argumento, elas produzem o mesmo resultado. Em linguística, extensionalidade se refere a expressões cujo significado é determinado exclusivamente por seu valor de referência, sem levar em conta contexto ou conotação.
Formalmente, a relação $\to_\beta$ é a menor relação de equivalência que satisfaz as seguintes propriedades:
-
redução-$beta$: $(\lambda x.\;M)N \to_\beta M[N/x]$
Isto significa que a aplicação de uma função $(\lambda x.\;M)$ a um argumento $N$ resulta na substituição de todas as ocorrências de $x$ em $M$ pelo valor $N$.
-
$\eta$-redução: $\lambda x.\;Mx\to_\beta M$, se $x$ não ocorre livre em $M$
A $\eta$-redução captura a ideia de extensionalidade. Se uma função $\lambda x.\;Mx$ aplica $M$ a $x$ sem modificar $x$, ela é equivalente a $M$.
-
Compatibilidade com abstração: Se $M\to_\beta M’$, então $\lambda x.\;M\to_\beta \lambda x.\;M’$
Isto garante que se dois termos são equivalentes, então suas abstrações, funções que os utilizam, serão equivalentes.
-
Compatibilidade com aplicação: Se $M\to_\beta M’$ e $N\to_\beta N’$, então $M\;N\to_\beta M’N’$
Esta regra mostra que a equivalência se propaga para as aplicações de funções, mantendo a consistência da equivalência.
É importante notar que a ordem em que as reduções são aplicadas não afeta o resultado\;devido à propriedade de Church-Rosser do cálculo lambda. Isso garante que, independentemente de como o termo é avaliado, se ele tem uma forma normal, a avaliação eventualmente a encontrará.
A relação $\to_\beta$ é uma relação de equivalência, o que significa que ela possui três propriedades: é uma relação Reflexiva. Ou seja, para todo termo $M$, temos que $M\to_\beta M$. O que significa que qualquer termo é equivalente a si mesmo, o que é esperado; é uma relação Simétrica. Isso significa que se $M\to_\beta N$, então $N\to_\beta M$. Se um termo $M$ pode ser transformado em $N$, então o oposto é similarmente verdade. E, finalmente, é uma relação Transitiva. Neste caso, se $M\to_\beta N$ e $N\to_\beta P$, então $M\to_\beta P$. Isso implica que, se podemos transformar $M$ em $N$ e $N$ em $P$, então podemos transformar diretamente $M$ em $P$.
A equivalência $\to_\beta$ influencia o raciocínio sobre programas em linguagens funcionais, permitindo substituições e otimizações que preservam o significado computacional. As propriedades da equivalência $\to_\beta$ garantem que podemos substituir termos equivalentes em qualquer contexto, sem alterar o significado ou o resultado da computação. Em termos de linguagens de programação, isso permite otimizações e refatorações que preservam a correção do programa.
Neste ponto, a leitora deve estar ansiosa para ver alguns exemplos de equivalência.
-
Identidade e aplicação trivial:
Exemplo 1:
\[\lambda x.(\lambda y.\;y)x \to_\beta \lambda x.\;x\]Aqui, a função interna $\lambda y.\;y$ é a função identidade, que simplesmente retorna o valor de $x$. Após a aplicação, obtemos $\lambda x.\;x$, a função identidade.
Exemplo 2:
\[\lambda z.(\lambda w.w)z \to_\beta \lambda z.\;z\]Assim como no exemplo original, a função interna $\lambda w.w$ é a função identidade. Após a aplicação, o valor de $z$ é retornado.
Exemplo 3:
\[\lambda a.(\lambda b.b)a \to_\beta \lambda a.a\]A função $\lambda b.b$ é aplicada ao valor $a$, retornando o próprio $a$. Isso demonstra mais uma aplicação da função identidade.
-
Função constante:
Exemplo 1:
\[(\lambda x.\lambda y.x)M\;N \to_\beta M\]Neste exemplo, a função $\lambda x.\lambda y.x$ retorna sempre seu primeiro argumento, ignorando o segundo. Aplicando isso a dois termos $M$ e $N$, o resultado é simplesmente $M$.
Exemplo 2:
\[(\lambda a.\lambda b.a)P Q \to_\beta P\]A função constante $\lambda a.\lambda b.a$ retorna sempre o primeiro argumento ($P$), ignorando $Q$.
Exemplo 3:
\[(\lambda u.\lambda v.u)A B \to_\beta A\]Aqui, o comportamento é o mesmo: o primeiro argumento ($A$) é retornado, enquanto o segundo ($B$) é ignorado.
-
$\eta$-redução:
Exemplo 1:
\[\lambda x.(\lambda y.M)x \to_\beta \lambda x.\;M[x/y]\]Se $x$ não ocorre livre em $M$, podemos usar a $\eta$-redução para encurtar a expressão, pois aplicar $M$ a $x$ não altera o comportamento da função. Este exemplo mostra como podemos internalizar a aplicação, eliminando a dependência desnecessária de $x$.
Exemplo 2:
\[\lambda x.(\lambda z.N)x \to_\beta \lambda x.N[x/z]\]Similarmente, se $x$ não ocorre em $N$, a $\eta$-redução simplifica a expressão para $\lambda x.N$.
Exemplo 3:
\[\lambda f.(\lambda g.P)f \to_\beta \lambda f.P[f/g]\]Aqui, a $\eta$-redução elimina a aplicação de $f$ em $P$, resultando em $\lambda f.P$.
-
Termo $\Omega$(não-terminante):
Exemplo 1:
\[(\lambda x.\;\, x\;x)(\lambda x.\;\, x\;x) \to_\beta (\lambda x.\;\, x\;x)(\lambda x.\;\, x\;x)\]Este é o famoso combinador $\Omega$, que se reduz a si mesmo indefinidamente, criando um ciclo infinito de auto-aplicações. Apesar de não ter forma normal (não termina), ele é equivalente a si mesmo por definição.
Exemplo 2:
\[(\lambda f.\;f\;f)(\lambda f.\;f\;f) \to_\beta (\lambda f.\;f\;f)(\lambda f.\;f\;f)\]Assim como o combinador $\Omega$, este termo cria um ciclo infinito de auto-aplicação.
Exemplo 3:
\[(\lambda u.\;u\;u)(\lambda u.\;u\;u) \to_\beta (\lambda u.\;u\;u)(\lambda u.\;u\;u)\]Outra variação do combinador $\Omega$, que resulta em uma redução infinita sem forma normal.
-
Composição de funções:
Exemplo 1:
\[(\lambda f.\lambda g.\lambda x.\;f\;(g\;x))\;M\;N \to_\beta \lambda x.\;M\;(N\;x)\]Neste caso, a composição de duas funções, $M$ e $N$, é expressa como uma função que aplica $N$ ao argumento $x$, e então aplica $M$ ao resultado. A redução demonstra como a composição de funções pode ser representada e simplificada no cálculo lambda.
Exemplo 2:
\[(\lambda f.\lambda g.\lambda y.\;f\;(g\;y))\;A\;B \to_\beta \lambda y.\;A\;(B\;y)\]A composição de $A$ e $B$ é aplicada ao argumento $y$, e o resultado de $By$ é então passado para $A$.
Exemplo 3:
\[(\lambda h.\lambda k.\lambda z.\;h\;(k\;z))\;P\;Q \to_\beta \lambda z.\;P\;(Q\;z)\]Similarmente, a composição de $P$ e $Q$ é aplicada ao argumento $z$, e o resultado de $Qz$ é passado para $P$.
Funções Recursivas e o Combinador Y
No cálculo lambda, uma linguagem puramente funcional, não há uma forma direta de definir funções recursivas. Isso acontece porque, ao tentar criar uma função que se refere a si mesma, como o fatorial, acabamos com uma definição circular que o cálculo lambda puro não consegue resolver. Uma tentativa ingênua de definir o fatorial seria:
\[\text{fac} = \lambda n.\;\text{if } (n = 0)\;\text{then } 1\;\text{else } n \times (\text{fac}\;(n - 1))\]Aqui, $\text{fac}$ aparece nos dois lados da equação, criando uma dependência circular. No cálculo lambda puro, não existem nomes ou atribuições; tudo se baseia em funções anônimas. Portanto, não é possível referenciar $\text{fac}$ dentro de sua própria definição.
No cálculo lambda, todas as funções são anônimas. Não existem variáveis globais ou nomes fixos para funções. As únicas formas de vincular variáveis são:
- Abstração lambda: $\lambda x.\;e$, na qual $x$ é um parâmetro e $e$ é o corpo da função.
- Aplicação de função: $(f\;a)$, na qual $f$ é uma função e $a$ é um argumento.
Não há um mecanismo para definir uma função que possa se referenciar diretamente. Na definição:
\[\text{fac} = \lambda n.\;\text{if } (n = 0)\;\text{then } 1\;\text{else } n \times (\text{fac}\;(n - 1))\]queremos que $\text{fac}$ possa chamar a si mesma. Mas no cálculo lambda puro:
-
Não há nomes persistentes: O nome $\text{fac}$ do lado esquerdo não está disponível no corpo da função à direita. Nomes em abstrações lambda são parâmetros locais.
-
Variáveis livres devem ser vinculadas: $\text{fac}$ aparece livre no corpo e não está ligada a nenhum parâmetro ou contexto. Isso viola as regras do cálculo lambda.
-
Sem referência direta a si mesmo: Não se pode referenciar uma função dentro de si mesma, pois não existe um escopo que permita isso.
Considere uma função simples no cálculo lambda:
\[\text{função} = \lambda x.\;x + 1\]Esta função está bem definida. Mas, se tentarmos algo recursivo:
\[\text{loop} = \lambda x.\;(\text{loop}\;x)\]O problema é o mesmo: $\text{loop}$ não está definido dentro do corpo da função. Não há como a função chamar a si mesma sem um mecanismo adicional.
Em linguagens de programação comuns, definimos funções recursivas porque o nome da função está disponível dentro do escopo. Em Haskell, por exemplo:
fac :: Int -> Int
fac 0 = 1
fac n = n * fac (n - 1)
Aqui, o nome fac está disponível em um dos casos da função para ser chamado recursivamente. No cálculo lambda, essa forma de vinculação não existe.
O Combinador $Y$ como Solução
Para contornar essa limitação, usamos o conceito de ponto fixo. Um ponto fixo de uma função $F$ é um valor $X$ tal que $F(X) \, = X$. No cálculo lambda, esse conceito é implementado por meio de combinadores de ponto fixo, sendo o mais conhecido o combinador $Y$, atribuído a Haskell Curry.
O combinador $Y$ é definido como:
\[Y = \lambda f. (\lambda x.\;f\;(x\;x))\;(\lambda x.\;f\;(x\;x))\]Para ilustrar o funcionamento do Y-combinator na prática, vamos implementá-lo em Haskell e usá-lo para definir a função fatorial:
-- Definição do Y-combinator
y :: (a -> a) -> a
y f = f (y f)
-- Definição da função fatorial usando o Y-combinator
factorial :: Integer -> Integer
factorial = Y \f n -> if n == 0 then 1 else n * f (n - 1)
main :: IO ()
main = do
print $ factorial 5 -- Saída: 120
print $ factorial 10 -- Saída: 3628800
Neste exemplo, o Y-combinator (y) é usado para criar uma versão recursiva da função fatorial sem a necessidade de defini-la recursivamente de forma explícita. A função factorial é criada aplicando $Y$ a uma função que descreve o comportamento do fatorial, mas sem se referir diretamente a si mesma. Podemos estender este exemplo para outras funções recursivas, como a sequência de Fibonacci:
fibonacci :: Integer -> Integer
fibonacci = y $\f n -> if n <= 1 then n else f (n - 1) + f (n - 2)
main :: IO ()
main = do
print $ map fibonacci [0..10] -- Saída: [0,1,1,2,3,5,8,13,21,34,55]
O Y-combinator, ou combinador-Y, tem uma propriedade interessante que a esforçada leitora deve entender:
\[Y\;F = F\;(Y\;F)\]Isso significa que $Y\;F$ é um ponto fixo de $F$, permitindo que definamos funções recursivas sem a necessidade de auto-referência explícita. Quando aplicamos o combinador $Y$ a uma função $F$, ele retorna uma versão recursiva de $F$.
Matematicamente, o combinador $Y$ cria a recursão ao forçar a função $F$ a se referenciar indiretamente. O processo ocorre:
-
Aplicamos o combinador $Y$ a uma função $F$.
-
O $Y$ retorna uma função que, ao ser chamada, aplica $F$ a si mesma repetidamente.
-
Essa recursão acontece até que uma condição de término, como o caso base de uma função recursiva, seja atingida.
Com o combinador $Y$, não precisamos declarar explicitamente a recursão. O ciclo de auto-aplicação é gerado automaticamente, transformando qualquer função em uma versão recursiva de si mesma.
Exemplo de Função Recursiva: Fatorial
Usando o combinador $Y$, podemos definir corretamente a função fatorial no cálculo lambda. O fatorial de um número $n$ será:
\[\text{factorial} = Y\;(\lambda f. \lambda n. \text{if}\;(\text{isZero}\;n)\;1\;(\text{mult}\;n\;(f\;(\text{pred}\;n))))\]Aqui, utilizamos funções auxiliares como $\text{isZero}$, $\text{mult}$ (multiplicação), e $\text{pred}$ (predecessor), todas definíveis no cálculo lambda. O combinador $Y$ cuida da recursão, aplicando a função a si mesma até que a condição de parada ($n = 0$) seja atendida. Vamos ver isso com mais detalhes usando o combinador $Y$ para definir $\text{fac}$
-
Defina uma função auxiliar que recebe como parâmetro a função recursiva:
\[\text{Fac} = \lambda f.\;\lambda n.\;\text{if } (n = 0)\;\text{then } 1\;\text{else } n \times (f\;(n - 1))\]Aqui, $\text{Fac}$ é uma função que, dado um função $f$, retorna outra função que calcula o fatorial usando $f$ para a chamada recursiva.
-
Aplique o combinador $Y$ a $\text{Fac}$ para obter a função recursiva:
\[\text{fac} = Y\;\text{Fac}\]
Agora, $\text{fac}$ é uma função que calcula o fatorial de forma recursiva.
O combinador $Y$ aplica $\text{Fac}$ a si mesmo para $\text{fac}$ se expande indefinidamente, permitindo as chamadas recursivas sem referência direta ao nome da função.
Exemplo 1:
Vamos calcular $\text{fac}\;2$ usando o combinador Y.
\[Y = \lambda f.\;(\lambda x.\;f\;(x\;x))\;(\lambda x.\;f\;(x\;x))\]Função Fatorial:
\[\text{fatorial} = Y\;\left (\lambda f.\;\lambda n.\;\text{if}\;(n = 0)\;1\;(n \times (f\;(n - 1))) \right)\]Expansão da Definição de $\text{fatorial}$:
Aplicamos $Y$ à função $\lambda f.\;\lambda n.\;\ldots$:
\[\text{fatorial} = Y\;(\lambda f.\;\lambda n.\;\text{if}\;(n = 0)\;1\;(n \times (f\;(n - 1))))\]Então, teremos:
\[\text{fatorial}\;2 = \left( Y\;(\lambda f.\;\lambda n.\;\ldots) \right)\;2\]Expandindo o Combinador Y:
A amável leitora deve lembrar que o Combinador $Y$ é definido como:
\[Y\;g = (\lambda x.\;g\;(x\;x))\;(\lambda x.\;g\;(x\;x))\]Aplicando $Y$ à função $g = \lambda f.\;\lambda n.\;\ldots$:
\[Y\;g = (\lambda x.\;g\;(x\;x))\;(\lambda x.\;g\;(x\;x))\]Portanto,
\[\text{fatorial} = (\lambda x.\;(\lambda f.\;\lambda n.\;\text{if}\;(n = 0)\;1\;(n \times (f\;(n - 1))))\;(x\;x))\;(\lambda x.\;(\lambda f.\;\lambda n.\;\text{if}\;(n = 0)\;1\;(n \times (f\;(n - 1))))\;(x\;x))\]Aplicando $\text{fatorial}$ a 2
\[\text{fatorial}\;2 = \left( (\lambda x.\;\ldots)\;(\lambda x.\;\ldots) \right)\;2\]Simplificando as Aplicações:
Primeira Aplicação:
\[\text{fatorial}\;2 = \left (\lambda x.\;F\;(x\;x) \right)\;\left (\lambda x.\;F\;(x\;x) \right)\;2\]Desta forma, $F = \lambda f.\;\lambda n.\;\text{if}\;(n = 0)\;1\;(n \times (f\;(n - 1)))$.
Aplicando o Primeiro: $\lambda x$
\[\left (\lambda x.\;F\;(x\;x) \right)\;\left (\lambda x.\;F\;(x\;x) \right) \, = F\;\left (\left (\lambda x.\;F\;(x\;x) \right)\;\left (\lambda x.\;F\;(x\;x) \right) \right)\]A atenta leitora deve ter notado que temos uma autorreferência:
\[M = \left (\lambda x.\;F\;(x\;x) \right)\;\left (\lambda x.\;F\;(x\;x) \right)\]Portanto,
\[\text{fatorial}\;2 = F\;M\;2\]Aplicando $F$ com $M$ e $n = 2$:
\[F\;M\;2 = (\lambda f.\;\lambda n.\;\text{if}\;(n = 0)\;1\;(n \times (f\;(n - 1))))\;M\;2\]Então,
\[\text{if}\;(2 = 0)\;1\;(2 \times (M\;(2 - 1)))\]Como $2 \ne 0$, calculamos:
\[\text{fatorial}\;2 = 2 \times (M\;1)\]Calculando $M\;1$:
Precisamos calcular $M\;1$, onde $M$ será:
\[M = \left (\lambda x.\;F\;(x\;x) \right)\;\left (\lambda x.\;F\;(x\;x) \right)\]Então,
\[M\;1 = \left (\lambda x.\;F\;(x\;x) \right)\;\left (\lambda x.\;F\;(x\;x) \right)\;1 = F\;M\;1\]Novamente, temos:
\[\text{fatorial}\;2 = 2 \times (F\;M\;1)\]Aplicando $F$ com $M$ e $n = 1$:
\[F\;M\;1 = (\lambda f.\;\lambda n.\;\text{if}\;(n = 0)\;1\;(n \times (f\;(n - 1))))\;M\;1\]Então,
\[\text{if}\;(1 = 0)\;1\;(1 \times (M\;(1 - 1)))\]Como $1 \ne 0$, temos:
\[F\;M\;1 = 1 \times (M\;0)\]Calculando $M\;0$:
\[M\;0 = \left (\lambda x.\;F\;(x\;x) \right)\;\left (\lambda x.\;F\;(x\;x) \right)\;0 = F\;M\;0\]Aplicando $F$ com $n = 0$:
\[F\;M\;0 = (\lambda f.\;\lambda n.\;\text{if}\;(n = 0)\;1\;(n \times (f\;(n - 1))))\;M\;0\]Como $0 = 0$, temos:
\[F\;M\;0 = 1\]Concluindo os Cálculos:
\[M\;0 = 1\] \[F\;M\;1 = 1 \times 1 = 1\] \[\text{fatorial}\;2 = 2 \times 1 = 2\]Portanto, o cálculo do fatorial de 2 será:
\[\text{fatorial}\;2 = 2\]Exemplo 2:
Agora, vamos verificar o cálculo de $\text{fatorial}\;3$ seguindo o mesmo procedimento.
Aplicando $\text{fatorial}$ a 3:
\[\text{fatorial}\;3 = F\;M\;3\]Onde $F$ e $M$ são como definidos anteriormente.
Aplicando $F$ com $n = 3$:
\[\text{if}\;(3 = 0)\;1\;(3 \times (M\;(3 - 1)))\]Como $3 \ne 0$, temos:
\[\text{fatorial}\;3 = 3 \times (M\;2)\]Calculando $M\;2$:
Seguindo o mesmo processo, teremos:
\[M\;2 = F\;M\;2\] \[F\;M\;2 = 2 \times (M\;1)\] \[M\;1 = F\;M\;1\] \[F\;M\;1 = 1 \times (M\;0)\] \[M\;0 = F\;M\;0 = 1\]Calculando os Valores:
\[M\;0 = 1\] \[F\;M\;1 = 1 \times 1 = 1\] \[M\;1 = 1\] \[F\;M\;2 = 2 \times 1 = 2\] \[M\;2 = 2\] \[\text{fatorial}\;3 = 3 \times 2 = 6\]Portanto, o cálculo do fatorial de 3 será:
\[\text{fatorial}\;3 = 6\]Representação da Lógica Proposicional no Cálculo Lambda
O cálculo lambda oferece uma representação formal para lógica proposicional, similar aos números de Church para os números naturais. Neste cenário é possível codificar valores verdade e operações lógicas como termos lambda. Essa abordagem permite que operações booleanas sejam realizadas através de expressões funcionais.
Para entender o impacto desta representação podemos começar com os dois valores verdade, True (Verdadeiro) e False (Falso), que podem ser representados na forma de funções de ordem superior como:
Verdadeiro: $\text{True} = \lambda x. \lambda y.\;x$
Falso: $\text{False} = \lambda x. \lambda y.\;y$
Aqui, True é uma função que quando aplicada a dois argumentos, retorna o primeiro, enquanto False aplicada aos mesmos dois argumentos retornará o segundo. Tendo definido os termos para verdadeiro e falso, todas as operações lógicas podem ser construídas.
A esperta leitora deve concordar que é interessante, para nossos propósitos, começar definindo as operações estruturais da lógica proposicional: negação (NOT), conjunção (AND), disjunção (OR) e completar com a disjunção exclusiva (XOR) e a condicional (IF-THEN-ELSE).
Negação
A operação de negação, NOT ou $\lnot$ inverte o valor de uma proposição lógica atendendo a Tabela Verdade 19.1.1.A:
| $A$ | $\text{Not } A$ |
|---|---|
| True | False |
| False | True |
Tabela Verdade 19.1.1.A. Operação de negação.
Utilizando o cálculo lambda a operação de negação pode ser definida como a seguinte função de ordem superior nomeada:
\[\text{Not} = \lambda b.\;b\;\text{False}\;\text{True}\]A função $\text{Not}$ recebe um argumento booleano $b$ e se $b$ for True, $\text{Not}$ False; caso contrário, retorna True. Para ver isso acontecer com funções nomeadas podemos avaliar $\text{Not}\;\text{True}$:
\[\begin{align*} \text{Not}\;\text{True} &= (\lambda b.\; b\; \text{False}\; \text{True})\; \text{True} \\ &\to_\beta \text{True}\; \text{False}\; \text{True} \\ &= (\lambda x.\; \lambda y.\; x)\; \text{False}\; \text{True} \\ &\to_\beta (\lambda y.\; \text{False})\; \text{True} \\ &\to_\beta \text{False} \end{align*}\]A persistente leitora irá apreciar esta mesma avaliação sem usar qualquer função nomeada, ou seja cálculo lambda puro:
\[\begin{align*} &(\lambda b.\; b\; (\lambda x.\; \lambda y.\; y)\; (\lambda x.\; \lambda y.\; x))\; (\lambda x.\; \lambda y.\; x) \\ &\to_\beta (\lambda x.\; \lambda y.\; x)\; (\lambda x.\; \lambda y.\; y)\; (\lambda x.\; \lambda y.\; x) \\ &\to_\beta (\lambda y.\; (\lambda x.\; \lambda y.\; y))\; (\lambda x.\; \lambda y.\; x) \\ &\to_\beta (\lambda x.\; \lambda y.\; y) \\ &\to_\beta \lambda x.\; \lambda y.\; y \end{align*}\]Conjunção
A operação de conjunção é uma operação binária que retorna True unicamente se ambos os operandos forem True obedecendo a Tabela Verdade 19.1.1.B.
| $A$ | $B$ | $A \land B$ |
|---|---|---|
| True | True | True |
| True | False | False |
| False | True | False |
| False | False | False |
Tabela Verdade 19.1.1.B. Operação conjunção.
No cálculo lambda, a operação de conjunção pode ser expresso por:
\[\text{And} = \lambda x. \lambda y.\;x\;y\;\text{False}\]Vamos avaliar uma conjunção aplicada a dois verdadeiros, usando funções nomeadas $\text{And}\;\text{True}\;\text{False}$ passo a passo:
\[\begin{align*} &\text{And}\;\text{True}\;\text{False} \\ &= (\lambda x. \lambda y.\;x\;y\;\text{False})\;\text{True}\;\text{False} \\ \\ &\text{Substituímos $\text{True}$, $\text{False}$ e $\text{And}$ por suas definições em cálculo lambda:} \\ &= (\lambda x. \lambda y.\;x\;y\;(\lambda x. \lambda y.\;y))\;(\lambda x. \lambda y.\;x)\;(\lambda x. \lambda y.\;y) \\ \\ &\text{Aplicamos a primeira redução beta, substituindo $x$ por $(\lambda x. \lambda y.\;x)$ na função $\text{And}$:} \\ &\to_\beta (\lambda y.\;(\lambda x. \lambda y.\;x)\;y\;(\lambda x. \lambda y.\;y))\;(\lambda x. \lambda y.\;y) \\ \\ &\text{Nesta etapa, a substituição de $x$ por $(\lambda x. \lambda y.\;x)$ resulta em uma nova função que depende de $y$. A expressão interna aplica $\text{True}$($\lambda x. \lambda y.\;x$) ao argumento $y$ e ao $\text{False}$($\lambda x. \lambda y.\;y$).} \\ \\ &\text{Agora, aplicamos a segunda redução beta, substituindo $y$ por $(\lambda x. \lambda y.\;y)$:} \\ &\to_\beta (\lambda x. \lambda y.\;x)\;(\lambda x. \lambda y.\;y)\;(\lambda x. \lambda y.\;y) \\ \\ &\text{A substituição de $y$ por $\text{False}$ resulta na expressão acima. Aqui, $\text{True}$ é aplicada ao primeiro argumento $\text{False}$, ignorando o segundo argumento.} \\ \\ &\text{Aplicamos a próxima redução beta, aplicando $\lambda x. \lambda y.\;x$ ao primeiro argumento $(\lambda x. \lambda y.\;y)$:} \\ &\to_\beta \lambda y.\;(\lambda x. \lambda y.\;y) \\ \\ &\text{Neste ponto, temos uma função que, quando aplicada a $y$, sempre retorna $\text{False}$, já que $\lambda x. \lambda y.\;x$ retorna o primeiro argumento.} \\ \\ &\text{Finalmente, aplicamos a última redução beta, que ignora o argumento de $\lambda y$ e retorna diretamente $\text{False}$:} \\ &\to_\beta \lambda x. \lambda y.\;y \\ \\ &\text{Esta é exatamente a definição de $\text{False}$ no cálculo lambda.} \\ \\ &\text{Portanto, o resultado será:} \\ &= \text{False} \end{align*}\]Esta aplicação fica mais simples se usarmos funções nomeadas:
\[\begin{align*} \text{And}\;\text{True}\;\text{False} &= (\lambda x. \lambda y.\;x\;y\;\text{False})\;\text{True}\;\text{False} \\ &\to_\beta (\lambda y.\;\text{True}\;y\;\text{False})\;\text{False} \\ &\to_\beta \text{True}\;\text{False}\;\text{False} \\ &= (\lambda x. \lambda y.\;x)\;\text{False}\;\text{False} \\ &\to_\beta (\lambda y.\;\text{False})\;\text{False} \\ &\to_\beta \text{False} \end{align*}\]A insistente leitora pode avaliar a conjunção usando unicamente o cálculo lambda puro, sem nenhuma função nomeada.
\[\begin{align*} &\text{And}\;\text{True}\;\text{False} \\ &= (\lambda x.\; \lambda y.\; x\; y\; (\lambda x.\; \lambda y.\; y))\; (\lambda x.\; \lambda y.\; x)\; (\lambda x.\; \lambda y.\; y) \\ \\ &\text{Aplicamos a primeira redução beta, substituindo $x$ por $\text{True}$ $(\lambda x.\; \lambda y.\; x)$:} \\ &\to_\beta (\lambda y.\; (\lambda x.\; \lambda y.\; x)\; y\; (\lambda x.\; \lambda y.\; y))\; (\lambda x.\; \lambda y.\; y) \\ \\ &\text{Aplicamos a segunda redução beta, substituindo $y$ por $\text{False}$ $(\lambda x.\; \lambda y.\; y)$:} \\ &\to_\beta (\lambda x.\; \lambda y.\; x)\; (\lambda x.\; \lambda y.\; y)\; (\lambda x.\; \lambda y.\; y) \\ \\ &\text{Agora, aplicamos a terceira redução beta, aplicando $\text{True}$ ao primeiro argumento $\text{False}$:} \\ &\to_\beta \lambda y.\; (\lambda x.\; \lambda y.\; y) \\ \\ &\text{Neste ponto, temos uma função que sempre retorna $\text{False}$, já que $\text{True}$ ignora o segundo argumento.} \\ \\ &\text{Aplicamos a última redução beta, que retorna diretamente $\text{False}$:} \\ &\to_\beta \lambda x.\; \lambda y.\; y \\ \\ &\text{Esta é exatamente a definição de $\text{False}$ no cálculo lambda.} \\ \\ &\text{Portanto, o resultado será:} \\ &= \text{False} \end{align*}\]Disjunção
A operação de disjunção retorna True se pelo menos um dos operandos for True em obediência a Tabela Verdade 19.1.1.C.
| $A$ | $B$ | $A \lor B$ |
|---|---|---|
| True | True | True |
| True | False | True |
| False | True | True |
| False | False | False |
Tabela Verdade 19.1.1.C. Operação disjunção.
Em cálculo lambda puro a operação de disjunção pode ser definida por:
\[\text{Or} = \lambda x. \lambda y.\;x\;\text{True}\;y\]Vamos avaliar $\text{Or}\;\text{True}\;\text{False}$ usando somente funções nomeadas:
\[\begin{align*} \text{Or}\;\text{True}\;\text{False} &= (\lambda x. \lambda y.\;x\;\text{True}\;y)\;\text{True}\;\text{False} \\ &\to_\beta (\lambda y.\;\text{True}\;\text{True}\;y)\;\text{False} \\ &\to_\beta \text{True}\;\text{True}\;\text{False} \\ &= (\lambda x. \lambda y.\;x)\;\text{True}\;\text{False} \\ &\to_\beta (\lambda y.\;\text{True})\;\text{False} \\ &\to_\beta \text{True} \end{align*}\]Vamos refazer esta mesma aplicação, porém em cálculo lambda puro:
\[\begin{align*} \text{And}\;\text{True}\;\text{False} &= (\lambda x.\; \lambda y.\; x\; y\; (\lambda x.\; \lambda y.\; y))\; (\lambda x.\; \lambda y.\; x)\; (\lambda x.\; \lambda y.\; y) \\ \\ &\text{Substituímos $\text{True}$, $\text{False}$ e $\text{And}$ por suas definições em cálculo lambda:} \\ &= (\lambda x.\; \lambda y.\; x\; y\; (\lambda x.\; \lambda y.\; y))\; (\lambda x.\; \lambda y.\; x)\; (\lambda x.\; \lambda y.\; y) \\ \\ &\text{Aplicamos a primeira redução beta, substituindo $x$ por $(\lambda x.\; \lambda y.\; x)$:} \\ &\to_\beta (\lambda y.\; (\lambda x.\; \lambda y.\; x)\; y\; (\lambda x.\; \lambda y.\; y))\; (\lambda x.\; \lambda y.\; y) \\ \\ &\text{Aplicamos a segunda redução beta, substituindo $y$ por $(\lambda x.\; \lambda y.\; y)$:} \\ &\to_\beta (\lambda x.\; \lambda y.\; x)\; (\lambda x.\; \lambda y.\; y)\; (\lambda x.\; \lambda y.\; y) \\ \\ &\text{Aplicamos a terceira redução beta, aplicando $\lambda x.\; \lambda y.\; x$ ao primeiro argumento $\text{False}$:} \\ &\to_\beta \lambda y.\; (\lambda x.\; \lambda y.\; y) \\ \\ &\text{Neste ponto, a função resultante é $\lambda y.\; y$, que é a definição de $\text{False}$.} \\ \\ &\text{Portanto, o resultado será:} \\ &= \text{False} \end{align*}\]Disjunção Exclusiva
A operação Xor (ou disjunção exclusiva) retorna True se um, e somente um, dos operandos for True e obedece a Tabela Verdade 19.1.1.D.
| $A$ | $B$ | $A \oplus B$ |
|---|---|---|
| True | True | False |
| True | False | True |
| False | True | True |
| False | False | False |
Tabela Verdade 19.1.1.D. Operação disjunção exclusiva
Sua definição no cálculo lambda é dada por:
\[\text{Xor} = \lambda b. \lambda c. b\;(\text{Not}\;c)\;c\]Para entender, podemos, novamente, avaliar $\text{Xor}\;\text{True}\;\text{False}$ usando funções nomeadas:
\[\begin{align*} \text{Xor}\;\text{True}\;\text{False} &= (\lambda b. \lambda c. b\;(\text{Not}\;c)\;c)\;\text{True}\;\text{False} \\ &\to_\beta (\lambda c. \text{True}\;(\text{Not}\;c)\;c)\;\text{False} \\ &\to_\beta \text{True}\;(\text{Not}\;\text{False})\;\text{False} \\ &\to_\beta \text{True}\;\text{True}\;\text{False} \\ &= (\lambda x. \lambda y.\;x)\;\text{True}\;\text{False} \\ &\to_\beta (\lambda y.\;\text{True})\;\text{False} \\ &\to_\beta \text{True} \end{align*}\]Para manter a tradição, vamos ver esta aplicação em cálculo lambda puro:
\[\begin{align*} \text{Xor}\;\text{True}\;\text{False} &= (\lambda b.\; \lambda c.\; b\; (\text{Not}\; c)\; c)\; (\lambda x.\; \lambda y.\; x)\; (\lambda x.\; \lambda y.\; y) \\ \\ &\text{Substituímos $\text{True}$, $\text{False}$, $\text{Not}$ e $\text{Xor}$ por suas definições em cálculo lambda:} \\ &= (\lambda b.\; \lambda c.\; b\; ((\lambda b.\; b\; (\lambda x.\; \lambda y.\; y)\; (\lambda x.\; \lambda y.\; x))\; c)\; c)\; (\lambda x.\; \lambda y.\; x)\; (\lambda x.\; \lambda y.\; y) \\ \\ &\text{Aplicamos a primeira redução beta, substituindo $b$ por $\text{True}$ $(\lambda x.\; \lambda y.\; x)$:} \\ &\to_\beta (\lambda c.\; (\lambda x.\; \lambda y.\; x)\; ((\lambda b.\; b\; (\lambda x.\; \lambda y.\; y)\; (\lambda x.\; \lambda y.\; x))\; c)\; c)\; (\lambda x.\; \lambda y.\; y) \\ \\ &\text{Aplicamos a segunda redução beta, substituindo $c$ por $\text{False}$ $(\lambda x.\; \lambda y.\; y)$:} \\ &\to_\beta (\lambda x.\; \lambda y.\; x)\; ((\lambda b.\; b\; (\lambda x.\; \lambda y.\; y)\; (\lambda x.\; \lambda y.\; x))\; (\lambda x.\; \lambda y.\; y))\; (\lambda x.\; \lambda y.\; y) \\ \\ &\text{Aplicamos a próxima redução beta na expressão $\text{Not False}$, que é $(\lambda b.\; b\; \text{False}\; \text{True})\; \text{False}$:} \\ &= (\lambda x.\; \lambda y.\; x)\; (\lambda x.\; \lambda y.\; x)\; (\lambda x.\; \lambda y.\; y) \\ \\ &\text{Aplicamos a quarta redução beta, aplicando $\text{True}$ $(\lambda x.\; \lambda y.\; x)$ ao primeiro argumento:} \\ &\to_\beta (\lambda y.\; \lambda x.\; x)\; (\lambda x.\; \lambda y.\; y) \\ \\ &\text{Finalmente, aplicamos a última redução beta, que retorna $\text{True}$ $(\lambda x.\; \lambda y.\; x)$:} \\ &= \lambda x.\; \lambda y.\; x \\ \\ &\text{Portanto, o resultado é $\text{True}$.} \end{align*}\]Questão de Prova 1: A operação $XNOR$ ($Not XOR$) retorna verdadeiro se as duas entradas forem iguais (ambas verdadeiras ou ambas falsas), e falso caso contrário. Crie uma função lambda que represente a operação $XNOR$ em cálculo lambda puro e aplique a $True$ e $False$.
Definições:
True: Representa a escolha do primeiro argumento.
\[\text{True} = \lambda x.\; \lambda y.\; x\]False: Representa a escolha do segundo argumento.
\[\text{False} = \lambda x.\; \lambda y.\; y\]Not: Inverte a entrada (de True para False e vice-versa).
\[\text{Not} = \lambda b.\; b\; \text{False}\; \text{True}\]Xor: Retorna $True$ se uma e somente uma das entradas for $True$.
\[\text{Xor} = \lambda b.\; \lambda c.\; b\; (\text{Not}\; c)\; c\]Agora que temos $True$, $False$, $Not$, e $XOR$, podemos definir $Not XOR$ ($XNOR$). Como $XNOR$ é o inverso de $XOR$, podemos usar a operação $Not$ aplicada ao resultado de $XOR$.
\[\text{XNOR} = \lambda b.\; \lambda c.\; (\text{Not}\; (\text{Xor}\; b\; c))\]Em lambda puro precisaremos substitui r $XOR$ e $Not$ por suas definições lambda, para transformar tudo em uma expressão pura.
\[\text{XNOR} = \lambda b.\; \lambda c.\; (\lambda b.\; b\; \text{False}\; \text{True}) ((\lambda b.\; \lambda c.\; b\; (\lambda b.\; b\; \text{False}\; \text{True})\; c)\; b\; c)\]Aplicação de $XNOR$ a $True$ e $False$
\[(\lambda b.\lambda c.(\lambda b.b(\lambda x.\lambda y.y)(\lambda x.\lambda y.x)) ((\lambda b.\lambda c.b(\lambda b.b(\lambda x.\lambda y.y)(\lambda x.\lambda y.x))c)bc)) (\lambda x.\lambda y.x)(\lambda x.\lambda y.y)\] \[(\lambda c.(\lambda b.b(\lambda x.\lambda y.y)(\lambda x.\lambda y.x)) ((\lambda b.\lambda c.b(\lambda b.b(\lambda x.\lambda y.y)(\lambda x.\lambda y.x))c) (\lambda x.\lambda y.x)c))(\lambda x.\lambda y.y)\] \[(\lambda b.b(\lambda x.\lambda y.y)(\lambda x.\lambda y.x)) ((\lambda b.\lambda c.b(\lambda b.b(\lambda x.\lambda y.y)(\lambda x.\lambda y.x))c) (\lambda x.\lambda y.x)(\lambda x.\lambda y.y))\] \[(\lambda b.b(\lambda x.\lambda y.y)(\lambda x.\lambda y.x))(\lambda x.\lambda y.x)\] \[\lambda x.\lambda y.y\]O resultado é False ($\lambda x.\lambda y.y$), que é o valor esperado para XNOR True False.
Implicação, ou condicional
A operação implicação ou condicional, retorna True ou False, conforme a Tabela Verdade 19.1.1.E. A implicação é verdadeira quando a premissa é falsa ou quando tanto a premissa quanto a conclusão são verdadeiras.
| $A$ | $B$ | $A \to B$ |
|---|---|---|
| True | True | True |
| True | False | False |
| False | True | True |
| False | False | True |
Tabela Verdade 19.1.1.E. Operação de implicação.
A operação de implicação pode ser definida no cálculo lambda como:
\[\lambda a.\; \lambda b.\; a\; b\; \text{True}\]Essa definição de implicação retorna False sempre que a premissa ($a$) é True e a conclusão ($b$) é False. Nos demais casos, retorna True.
Novamente podemos ver uma aplicação da implicação usando funções nomeadas:
\[\begin{align*} \text{Implicação}\;\text{True}\;\text{False} &= (\lambda a.\; \lambda b.\; a\; b\; \text{True})\; (\lambda x.\; \lambda y.\; x)\; (\lambda x.\; \lambda y.\; y) \\ \\ &\text{Substituímos $\text{True}$, $\text{False}$ e $\text{Implicação}$ por suas definições:} \\ &= (\lambda a.\; \lambda b.\; a\; b\; (\lambda x.\; \lambda y.\; x))\; (\lambda x.\; \lambda y.\; x)\; (\lambda x.\; \lambda y.\; y) \\ \\ &\text{Aplicamos a primeira redução beta, substituindo $a$ por $\text{True}$ $(\lambda x.\; \lambda y.\; x)$:} \\ &\to_\beta (\lambda b.\; (\lambda x.\; \lambda y.\; x)\; b\; (\lambda x.\; \lambda y.\; x))\; (\lambda x.\; \lambda y.\; y) \\ \\ &\text{Aplicamos a segunda redução beta, substituindo $b$ por $\text{False}$ $(\lambda x.\; \lambda y.\; y)$:} \\ &\to_\beta (\lambda x.\; \lambda y.\; x)\; (\lambda x.\; \lambda y.\; y)\; (\lambda x.\; \lambda y.\; x) \\ \\ &\text{Aplicamos a próxima redução beta, aplicando $\text{True}$ $(\lambda x.\; \lambda y.\; x)$ ao primeiro argumento:} \\ &\to_\beta \lambda y.\; (\lambda x.\; \lambda y.\; y) \\ \\ &\text{Neste ponto, o resultado é $\text{False}$ $(\lambda x.\; \lambda y.\; y)$.} \\ \\ &\text{Portanto, o resultado será:} \\ &= \text{False} \end{align*}\]E, ainda mantendo a tradição, vamos ver a mesma aplicação em cálculo lambda puro:
\[\begin{align*} \text{Implicação}\;\text{True}\;\text{False} &= (\lambda a.\; \lambda b.\; a\; b\; \text{True})\; (\lambda x.\; \lambda y.\; x)\; (\lambda x.\; \lambda y.\; y) \\ \\ &\text{Substituímos $\text{True}$, $\text{False}$ e $\text{Implicação}$ por suas definições em cálculo lambda:} \\ &= (\lambda a.\; \lambda b.\; a\; b\; (\lambda x.\; \lambda y.\; x))\; (\lambda x.\; \lambda y.\; x)\; (\lambda x.\; \lambda y.\; y) \\ \\ &\text{Aplicamos a primeira redução beta, substituindo $a$ por $\text{True}$ $(\lambda x.\; \lambda y.\; x)$:} \\ &\to_\beta (\lambda b.\; (\lambda x.\; \lambda y.\; x)\; b\; (\lambda x.\; \lambda y.\; x))\; (\lambda x.\; \lambda y.\; y) \\ \\ &\text{Aplicamos a segunda redução beta, substituindo $b$ por $\text{False}$ $(\lambda x.\; \lambda y.\; y)$:} \\ &\to_\beta (\lambda x.\; \lambda y.\; x)\; (\lambda x.\; \lambda y.\; y)\; (\lambda x.\; \lambda y.\; x) \\ \\ &\text{Aplicamos a terceira redução beta, aplicando $\lambda x.\; \lambda y.\; x$ ao primeiro argumento $(\lambda x.\; \lambda y.\; y)$:} \\ &\to_\beta \lambda y.\; (\lambda x.\; \lambda y.\; y) \\ \\ &\text{Aplicamos a última redução beta, resultando em $\text{False}$ $(\lambda x.\; \lambda y.\; y)$:} \\ &\to_\beta \lambda x.\; \lambda y.\; y \\ \\ &\text{Portanto, o resultado será:} \\ &= \text{False} \end{align*}\]Operação IF-THEN-ELSE
A operação IF-THEN-ELSE não é uma das operações da lógica proposicional. IF-THEN-ELSE é, provavelmente, a mais popular estrutura de controle de fluxo em linguagens de programação. Em cálculo lambda podemos expressar esta operação por:
\[\lambda b.\; \lambda x.\; \lambda y.\; b\; x\; y\]Nesta definição: $b$ representa a condição booleana (True ou False), $b$ representa o operador condicional do IF-THAN-ELSE. O $x$ representa o valor retornado se $b$ for True e $y$ representa o valor retornado se $b$ for False.
Vamos aplicar a estrutura condicional para a expressão em dois casos distintos:
-
Aplicação de IF-THEN-ELSE a True $x$ $y$
\[\begin{align*} \text{IF-THEN-ELSE}\;\text{True}\;x\;y &= (\lambda b.\; \lambda x.\; \lambda y.\; b\; x\; y)\; (\lambda x.\; \lambda y.\; x)\; x\; y \\ \\ &\text{Substituímos $\text{True}$ e $\text{IF-THEN-ELSE}$ por suas definições em cálculo lambda:} \\ &= (\lambda b.\; \lambda x.\; \lambda y.\; b\; x\; y)\; (\lambda x.\; \lambda y.\; x)\; x\; y \\ \\ &\text{Aplicamos a primeira redução beta, substituindo $b$ por $\text{True}$ $(\lambda x.\; \lambda y.\; x)$:} \\ &\to_\beta (\lambda x.\; \lambda y.\; (\lambda x.\; \lambda y.\; x)\; x\; y) \\ \\ &\text{Aplicamos a segunda redução beta, aplicando $\text{True}$ $(\lambda x.\; \lambda y.\; x)$ ao argumento $x$:} \\ &\to_\beta (\lambda y.\; x) \\ \\ &\text{Finalmente, aplicamos a última redução beta, retornando $x$:} \\ &\to_\beta x \end{align*}\]Outra vez, para não perder o hábito, vamos ver esta mesma aplicação em Cálculo Lambda Puro:
\[\begin{align*} \text{IF-THEN-ELSE}\;\text{True}\;x\;y &= (\lambda b.\; \lambda x.\; \lambda y.\; b\; x\; y)\; (\lambda x.\; \lambda y.\; x)\; x\; y \\ \\ &\text{Substituímos $\text{True}$ e $\text{IF-THEN-ELSE}$ por suas definições:} \\ &= (\lambda b.\; \lambda x.\; \lambda y.\; b\; x\; y)\; (\lambda x.\; \lambda y.\; x)\; x\; y \\ \\ &\text{Aplicamos a primeira redução beta, substituindo $b$ por $\text{True}$ $(\lambda x.\; \lambda y.\; x)$:} \\ &\to_\beta (\lambda x.\; \lambda y.\; (\lambda x.\; \lambda y.\; x)\; x\; y) \\ \\ &\text{Aplicamos a segunda redução beta, aplicando $\text{True}$ ao argumento $x$:} \\ &\to_\beta (\lambda y.\; x) \\ \\ &\text{Finalmente, aplicamos a última redução beta, retornando $x$:} \\ &\to_\beta x \end{align*}\] -
Aplicação de IF-THEN-ELSE a False $x$ $y$
\[\begin{align*} \text{IF-THEN-ELSE}\;\text{False}\;x\;y &= (\lambda b.\; \lambda x.\; \lambda y.\; b\; x\; y)\; (\lambda x.\; \lambda y.\; y)\; x\; y \\ \\ &\text{Substituímos $\text{False}$ e $\text{IF-THEN-ELSE}$ por suas definições em cálculo lambda:} \\ &= (\lambda b.\; \lambda x.\; \lambda y.\; b\; x\; y)\; (\lambda x.\; \lambda y.\; y)\; x\; y \\ \\ &\text{Aplicamos a primeira redução beta, substituindo $b$ por $\text{False}$ $(\lambda x.\; \lambda y.\; y)$:} \\ &\to_\beta (\lambda x.\; \lambda y.\; (\lambda x.\; \lambda y.\; y)\; x\; y) \\ \\ &\text{Aplicamos a segunda redução beta, aplicando $\text{False}$ $(\lambda x.\; \lambda y.\; y)$ ao argumento $y$:} \\ &\to_\beta (\lambda y.\; y) \\ \\ &\text{Finalmente, aplicamos a última redução beta, retornando $y$:} \\ &\to_\beta y \end{align*}\]Eu sei que a amável leitora não esperava por essa. Mas, eu vou refazer esta aplicação em cálculo lambda puro.
\[\begin{align*} \text{IF-THEN-ELSE}\;\text{False}\;x\;y &= (\lambda b.\; \lambda x.\; \lambda y.\; b\; x\; y)\; (\lambda x.\; \lambda y.\; y)\; x\; y \\ \\ &\text{Substituímos $\text{False}$ e $\text{IF-THEN-ELSE}$ por suas definições:} \\ &= (\lambda b.\; \lambda x.\; \lambda y.\; b\; x\; y)\; (\lambda x.\; \lambda y.\; y)\; x\; y \\ \\ &\text{Aplicamos a primeira redução beta, substituindo $b$ por $\text{False}$ $(\lambda x.\; \lambda y.\; y)$:} \\ &\to_\beta (\lambda x.\; \lambda y.\; (\lambda x.\; \lambda y.\; y)\; x\; y) \\ \\ &\text{Aplicamos a segunda redução beta, aplicando $\text{False}$ ao argumento $y$:} \\ &\to_\beta (\lambda y.\; y) \\ \\ &\text{Finalmente, aplicamos a última redução beta, retornando $y$:} \\ &\to_\beta y \end{align*}\]
No cálculo lambda, o controle de fluxo é feito inteiramente através de funções e substituições. A estrutura IF-THEN-ELSE introduz decisões condicionais a este sistema lógico. Permitindo escolher entre dois resultados diferentes com base em uma condição booleana.
Afirmamos anteriormente que o cálculo lambda é um modelo de computação completo, capaz de expressar qualquer computação que uma máquina de Turing pode executar. Para alcançar essa completude, é necessário ser capaz de tomar decisões. A função IF-THEN-ELSE é uma forma direta de conseguir esta funcionalidade.
Estruturas de Dados Compostas
Embora o cálculo lambda puro não possua estruturas de dados nativas, podemos representá-las usando funções. Um exemplo clássico é a codificação de listas no estilo de Church, que nos permite aplicar recursão a essas estruturas.
Como a amável leitora deve lembrar, O cálculo lambda é um sistema formal para expressar computação baseada em abstração e aplicação de funções. Sendo Turing completo, o cálculo lambda pode expressar qualquer computação, ou estrutura de dados, realizável. Podemos representar estas estruturas usando funções. Esta seção explora como listas e tuplas são representadas e manipuladas no cálculo lambda puro.
Para nos mantermos na mesma linha de raciocínio, vamos lembrar que:
-
Listas: Representam coleções ordenadas de elementos, potencialmente infinitas.
-
Tuplas: Representam coleções finitas e heterogêneas de elementos. Nesta seção, tuplas representarão pares ordenados.
No cálculo lambda, estas estruturas são representadas usando funções de ordem superior. Por exemplo, uma lista $[1, 2, 3]$ em cálculo lambda puro é representada como:
\[\text{cons}\;1\;(\text{cons}\;2\;(\text{cons}\;3\;\text{nil}))\]Uma tupla $(3, 4)$ é representada como:
\[\lambda f.\;f\;3\;4\]Listas
Para definirmos uma lista precisamos do conceito de lista vazia, que aqui será representado por $\text{nil}$ e uma função de construção de listas, $\text{cons}$:
-
Lista vazia ($\text{nil}$):
\[\text{nil} = \lambda c.\,\lambda n.\;n\]Esta função ignora o primeiro argumento e retorna o segundo representando a lista vazia.
-
Construtor de lista ($\text{cons}$):
\[\text{cons} = \lambda h. \lambda t. \lambda c. \, \lambda n.\;c\;h\;(t\;c\;n)\]O construtor recebe um elemento $h$ e uma lista $t$, e cria uma nova lista com $h$ na frente de $t$.
O termo $\text{cons}$ é, uma função de ordem superior e, como tal, não faz parte do cálculo lambda puro. Porém, facilita a visualização dos processos de aplicação e substituição e, consequentemente seu entendimento. Com $\text{nil}$ e $\text{cons}$, podemos criar e manipular listas. Por exemplo, a lista $[1, 2, 3]$ será representada como:
\[\text{cons}\;1\;(\text{cons}\;2\;(\text{cons}\;3\;\text{nil}))\]Esta lista está diagramada na Figura 20.1.B:
 Figura 6.1.B: Diagrama de uma lista em cálculo lambda
Figura 6.1.B: Diagrama de uma lista em cálculo lambda
Quando a leitora olha para o diagrama e para a função que representa a lista $[1,2,3]$ em cálculo lambda imagina que existe um abismo entre a sua ideia de lista e a função que encontramos. Não perca as esperanças, não é tão complicado quanto parece. Só trabalhoso. Chegamos a esta função começando com a lista vazia:
\[\text{nil} = \lambda c. \,\lambda n.\;n\]Adicionamos o elemento 3:
\[\text{cons}\;3\;\text{nil} = (\lambda h. \lambda t. \lambda c. \, \lambda n.\;c\;h\;(t\;c\;n))\;3\;(\lambda c. \, \lambda n.\;n)\]Após a redução-$beta$, temos:
\[\lambda c. \, \lambda n.\;c\;3\;((\lambda c. \, \lambda n.\;n)\;c\;n)\]Adicionamos o elemento 2:
\[\text{cons}\;2\;(\text{cons}\;3\;\text{nil}) \, = (\lambda h. \lambda t. \lambda c. \, \lambda n.\;c\;h\;(t\;c\;n))\;2\;(\lambda c. \, \lambda n.\;c\;3\;((\lambda c. \, \lambda n.\;n)\;c\;n))\]Após a redução-$beta$, obtemos:
\[\lambda c. \, \lambda n.\;c\;2\;((\lambda c. \, \lambda n.\;c\;3\;((\lambda c. \, \lambda n.\;n)\;c\;n))\;c\;n)\]Finalmente, adicionamos o elemento 1:
\[\text{cons}\;1\;(\text{cons}\;2\;(\text{cons}\;3\;\text{nil})) \, = (\lambda h. \lambda t. \lambda c. \, \lambda n.\;c\;h\;(t\;c\;n))\;1\;(\lambda c. \, \lambda n.\;c\;2\;((\lambda c. \, \lambda n.\;c\;3\;((\lambda c. \, \lambda n.\;n)\;c\;n))\;c\;n))\]Após a redução-$beta$, a representação final será:
\[\lambda c. \, \lambda n.\;c\;1\;((\lambda c. \, \lambda n.\;c\;2\;((\lambda c. \, \lambda n.\;c\;3\;((\lambda c. \, \lambda n.\;n)\;c\;n))\;c\;n))\;c\;n)\]Esta é a representação completa da lista $[1, 2, 3]$ em cálculo lambda puro. Esta representação permite operações recursivas sobre listas, como mapear funções ou calcular comprimentos. A curiosa leitora pode matar a curiosidade vendo a definição de uma de duas funções em cálculo lambda puro para lidar com listas:
Função Comprimento de lista (Length)
Vamos criar uma função para calcular o comprimento de uma lista usando o combinador $Y$:
\[\text{length} = Y\;(\lambda f. \lambda l. l\;(\lambda h. \lambda t. \text{succ}\;(f\;t))\;0)\]Aqui, $\text{succ}$ é a função que retorna o sucessor de um número, e o corpo da função aplica-se recursivamente até que a lista seja esvaziada.
Exemplo 1: Vamos calcular o Comprimento da Lista $[1, 2, 3]$ em Cálculo Lambda Puro, usando $\text{length}$:
Definição de $\text{length}$:
\[\text{length} = Y\;(\lambda f. \lambda l. l\;(\lambda h. \lambda t. \text{succ}\;(f\;t))\;0)\]Representação da lista $[1, 2, 3]$:
\[[1, 2, 3] = \lambda c. \, \lambda n.\;c\;1\;(c\;2\;(c\;3\;n))\]Aplicamos $\text{length}$ à lista:
\[\text{length}\;[1, 2, 3] = Y\;(\lambda f. \lambda l. l\;(\lambda h. \lambda t. \text{succ}\;(f\;t))\;0)\;(\lambda c. \, \lambda n.\;c\;1\;(c\;2\;(c\;3\;n)))\]O combinador $Y$ permite a recursão. Após aplicá-lo, obtemos:
\[(\lambda l. l\;(\lambda h. \lambda t. \text{succ}\;(\text{length}\;t))\;0)\;(\lambda c. \, \lambda n.\;c\;1\;(c\;2\;(c\;3\;n)))\]Aplicamos a função à lista:
\[(\lambda c. \, \lambda n.\;c\;1\;(c\;2\;(c\;3\;n)))\;(\lambda h. \lambda t. \text{succ}\;(\text{length}\;t))\;0\]Reduzimos, aplicando $c$ e $n$:
\[(\lambda h. \lambda t. \text{succ}\;(\text{length}\;t))\;1\;((\lambda h. \lambda t. \text{succ}\;(\text{length}\;t))\;2\;((\lambda h. \lambda t. \text{succ}\;(\text{length}\;t))\;3\;0))\]Reduzimos cada aplicação de $(\lambda h. \lambda t. \text{succ}\;(\text{length}\;t))$:
\[\text{succ}\;(\text{succ}\;(\text{succ}\;(\text{length}\;\text{nil})))\]Sabemos que $\text{length}\;\text{nil} = 0$, então:
\[\text{succ}\;(\text{succ}\;(\text{succ}\;0))\]Cada $\text{succ}$ incrementa o número por 1, então o resultado é 3.
Portanto, $\text{length}\;[1, 2, 3] = 3$ em cálculo lambda puro.
Funções Head e Tail em Cálculo Lambda Puro
As funções Head e Tail são funções uteis na manipulação de listas, principalmente em linguagens funcionais. Vamos definir estas funções em cálculo lambda puro. Começando pela função $\text{head}$:
\[\text{head} = \lambda l.\;l\;(\lambda h. \lambda t.\;h)\;(\lambda x.\;x)\]Em seguida, temos a função $\text{tail}$:
\[\text{tail} = \lambda l. l\;(\lambda h. \lambda t. t)\;(\lambda x.\;x)\]Exemplo 1: Aplicação à lista [1, 2, 3]
Aplicação de Head: Aplicamos Head à lista:
\[\text{head}\;[1, 2, 3] = (\lambda l. l\;(\lambda h. \lambda t. h)\;(\lambda x.\;x))\;(\lambda c. \, \lambda n.\;c\;1\;(c\;2\;(c\;3\;n)))\]Reduzimos:
\[(\lambda c. \, \lambda n.\;c\;1\;(c\;2\;(c\;3\;n)))\;(\lambda h. \lambda t. h)\;(\lambda x.\;x)\]Aplicamos $c$ e $n$:
\[(\lambda h. \lambda t. h)\;1\;((\lambda h. \lambda t. h)\;2\;((\lambda h. \lambda t. h)\;3\;(\lambda x.\;x)))\]Reduzimos:
\[1\]Portanto, $\text{head}\;[1, 2, 3] = 1$.
Aplicação de Tail:
Seja o estado após a aplicação de $c$ e $n$:
\[(\lambda h. \lambda t. t)\;1\;((\lambda h. \lambda t. t)\;2\;((\lambda h. \lambda t. t)\;3\;(\lambda x.\;x)))\]Avaliamos de dentro para fora. Começando com a expressão mais interna:
\[(\lambda h. \lambda t. t)\;3\;(\lambda x.\;x)\]Aplicando $h = 3$:
\[(\lambda t. t)\;(\lambda x.\;x)\]Aplicando $t = (\lambda x.\;x)$:
\[\lambda x.\;x\]Agora a expressão intermediária:
\[(\lambda h. \lambda t. t)\;2\;(\lambda x.\;x)\]Aplicando $h = 2$:
\[(\lambda t. t)\;(\lambda x.\;x)\]Aplicando $t = (\lambda x.\;x)$:
\[\lambda x.\;x\]Por fim, a expressão mais externa:
\[(\lambda h. \lambda t. t)\;1\;(\lambda x.\;x)\]Aplicando $h = 1$:
\[(\lambda t. t)\;(\lambda x.\;x)\]Aplicando $t = (\lambda x.\;x)$:
\[\lambda x.\;x\]Após todas estas reduções, a lista resultante é construída usando o construtor de lista padrão:
\[\lambda c. \, \lambda n.\;c\;2\;(c\;3\;n)\]Que representa a lista $[2, 3]$.
Listas são um tipo de dado composto útil para a maior parte das linguagens de programação. Não poderíamos deixar de definir listas em cálculo lambda puro para exemplificar a possibilidade da criação de algoritmos em cálculo lambda. Outra estrutura indispensável são as tuplas.
Tuplas em Cálculo Lambda Puro
Definimos uma tupla de dois elementos, que pode representar um par ordenado, como:
\[(x, y) \, = \lambda f.\;F\;x\;y\]A tupla $(3,4)$ é representada assim:
\[(3, 4) \, = \lambda f.\;F\;3\;4\]Para que uma tupla seja útil, precisamos ser capazes de trabalhar com seus elementos individualmente. Para isso, podemos definir duas funções: $\text{first}$ e $\text{follow}$.
Função First
A função First retorna o primeiro elemento da tupla:
\[\text{first} = \lambda p. p\;(\lambda x. \lambda y.\;x)\]Exemplo: Aplicação a $(3,4)$:
\[\text{first}\;(3, 4) \, = (\lambda p. p\;(\lambda x. \lambda y.\;x))\;(\lambda f.\;F\;3\;4)\]Redução:
\[(\lambda f.\;F\;3\;4)\;(\lambda x. \lambda y.\;x)\] \[(\lambda x. \lambda y.\;x)\;3\;4\] \[3\]Função Last
A função Last retorna o último elemento da tupla:
\[\text{last} = \lambda p. p\;(\lambda x. \lambda y.\;y)\]Exemplo 2: Aplicação a $(3,4)$:
\[\text{last}\;(3, 4) \, = (\lambda p. p\;(\lambda x. \lambda y.\;y))\;(\lambda f.\;F\;3\;4)\]Redução:
\[(\lambda f.\;F\;3\;4)\;(\lambda x. \lambda y.\;y)\] \[(\lambda x. \lambda y.\;y)\;3\;4\] \[4\]Questão de Prova 1: usando cálculo lambda puro crie uma tupla para o par $(3,5)$ e aplique a ela as funções $first$ e $last$.
O par $(x, y)$ pode ser definido no cálculo lambda utilizando a seguinte expressão de pares de Church:
\[(x, y) = \lambda f.\;f\;x\;y\]Queremos criar a tupla $(3, 5)$. Primeiro, precisamos representar os números $3$ e $5$ usando a notação lambda de números naturais (também conhecidos como números de Church).
Representação de $3$:
\[3 = \lambda s.\;\lambda z.\;s\;(s\;(s\;z))\]Representação de $5$:
\[5 = \lambda s.\;\lambda z.\;s\;(s\;(s\;(s\;(s\;z))))\]Agora podemos criar a tupla $(3, 5)$ usando a definição de pares:
\[\text{pair} = (\lambda f.\;f\;3\;5)\]Funções
firstelast: as funçõesfirstelastsão responsáveis por extrair o primeiro e o segundo elemento do par, respectivamente. Elas são definidas como:\[\text{first} = \lambda p.\;p\;(\lambda x.\;\lambda y.\;x)\]
first:\[\text{last} = \lambda p.\;p\;(\lambda x.\;\lambda y.\;y)\]
last:Aplicação das Funções
firstelastà Tupla: vamos aplicar as funçõesfirstelastà tupla $(3, 5)$.Para
\[\text{first}\;(\text{pair}) = (\lambda p.\;p\;(\lambda x.\;\lambda y.\;x))\;(\lambda f.\;f\;3\;5)\]first, aplicamos a tupla à função que retorna o primeiro elemento:Para
\[\text{last}\;(\text{pair}) = (\lambda p.\;p\;(\lambda x.\;\lambda y.\;y))\;(\lambda f.\;f\;3\;5)\]last, aplicamos a tupla à função que retorna o segundo elemento:Em resumo temos:
\[3 = \lambda s.\; \lambda z.\; s\; (s\; (s\; z))\] \[5 = \lambda s.\; \lambda z.\; s\; (s\; (s\; (s\; (s\; z))))\]Criação da Tupla (3, 5):
\[\text{pair} = \lambda f.\; f\; 3\; 5\]Função
\[\text{first} = \lambda p.\; p\; (\lambda x.\; \lambda y.\; x)\] \[\text{first}\; (\text{pair}) = (\lambda p.\; p\; (\lambda x.\; \lambda y.\; x))\; (\lambda f.\; f\; 3\; 5)\]firste Aplicação à Tupla:Substituindo $\text{pair}$:
\[= (\lambda f.\; f\; 3\; 5)\; (\lambda x.\; \lambda y.\; x)\]Aplicando a função:
\[= (\lambda x.\; \lambda y.\; x)\; 3\; 5\]Avaliando a aplicação:
\[= 3\]Função
\[\text{last} = \lambda p.\; p\; (\lambda x.\; \lambda y.\; y)\]laste Aplicação à TuplaAplicação:
\[\text{last}\; (\text{pair}) = (\lambda p.\; p\; (\lambda x.\; \lambda y.\; y))\; (\lambda f.\; f\; 3\; 5)\]Substituindo $\text{pair}$:
\[= (\lambda f.\; f\; 3\; 5)\; (\lambda x.\; \lambda y.\; y)\]Aplicando a função:
\[= (\lambda x.\; \lambda y.\; y)\; 3\; 5\]Avaliando a aplicação:
\[= 5\]
-
Alonzo Church and J.B. Rosser. Some properties of conversion. Transactions of the American Mathematical Society, 39(3):472–482, May 1936. https://www.ams.org/journals/tran/1936-039-03/S0002-9947-1936-1501858-0/S0002-9947-1936-1501858-0.pdf ↩
-
Alonzo Church and J.B. Rosser. Some properties of conversion. Transactions of the American Mathematical Society, 39(3):472–482, May 1936. https://www.ams.org/journals/tran/1936-039-03/S0002-9947-1936-1501858-0/S0002-9947-1936-1501858-0.pdf ↩
-
BARENDREGT, H. P. (1984). The Lambda Calculus: Its Syntax and Semantics. North-Holland. ↩