
Receitas da Família Alcantara

Estas são as receitas que minha esposa, Fran, sempre traz para nossa mesa. Uma cozinheira de mão cheia, ela adora experimentar e trazer novidades. Aqui estão algumas de suas receitas favoritas, que são práticas, rápidas e deliciosas. Espero que você goste tanto quanto nós!
Nós mantínhamos estas receitas em um blog, muito antigo, que não existe mais. Mas, como são receitas que sempre fazemos, resolvemos colocar aqui, para não perdermos mais.
Pipoca Perfeita
Ingredientes
- Milho de pipoca;
- Banha de porco fresca;
- Sal a gosto.
Modo de Preparo
- Derreta a banha, apenas o suficiente para cobrir o fundo;
- Coloque 3 grãos de milho e leve ao fogo alto;
- Quando os 3 grãos estourarem, coloque o restante do milho, cobrindo apenas o fundo da panela;
- Abaixe o fogo para médio e espere 30 segundos;
- Mexa a panela e volte ao fogo alto;
- Continue mexendo até que as pipocas parem de estourar;
- Adicione sal a gosto.
Arroz à Piamontese
Esta é a receita que, muito antigamente, fazia parte do restaurante Lamole. Nem sei se este restaurante ainda existe no Rio de Janeiro. Mas, quando namorávamos, eu e a Fran, sempre íamos lá. E, sempre que pedíamos o Arroz à Piamontese, ela dizia que era o melhor arroz que já tinha comido. Depois de anos, um garçon nos ensinou a receita. E, desde então, fazemos sempre que temos um tempinho.
Ingredientes
- 2 xícaras de arroz parboilizado;
- 1 colher de sopa de manteiga;
- 1 cebola pequena bem picadinha;
- 50g de queijo parmesão ralado;
- 1/4 de xícara de vinho branco seco;
- 1 lata de creme de leite;
- 100g de champignon picado.
Modo de Preparo
- Cozinhe o arroz com pouco sal, sem óleo, reserve;
- Em uma panela aqueça a manteiga, refogue a cebola até ficar transparente;
- Coloque o champignon, refogue um pouco;
- Acrescente o vinho e espere reduzir até evaporar o álcool;
- Acrescente o creme de leite e o queijo ralado;
- Misture o arroz e mexa bem, deixando ferver por 2-3 minutos;
- Sirva bem quente.
Bolo de Banana com Aveia
Ingredientes
- 5 bananas caturras, sem casca e cortadas em rodelas;
- 4 ovos;
- 1/2 xícara de chá de óleo de milho (ou soja);
- 1/2 xícara de chá de leite;
- 1 xícara de chá de farinha de trigo;
- 1 xícara de chá de aveia;
- 2 xícaras de chá de açúcar mascavo;
- 1 colher de sopa de fermento em pó;
- Canela em pó, a gosto, para salpicar.
Modo de Preparo
- Pegue uma das bananas, coloque junto com todos os outros ingredientes no liquidificador e bata por pelo menos dois minutos;
- Acrescente o fermento e misture um pouco;
- Unte uma assadeira com furo central com óleo e farinha de trigo;
- Despeje a massa na assadeira untada e arrume as outras bananas por sobre a massa e salpique com canela a gosto;
- Asse em forno pré aquecido a 180 graus por aproximadamente uma hora;
Waffle de Massa Folhada
Ingredientes
- Massa folhada, comprada pronta;
- Goiabada;
- Queijo Catupiry.
Modo de Preparo
- Esquente a máquina de waffles;
- Pegue uma folha de massa folhada, coloque uma fatia fina de goiabada e uma fatia fina de queijo Catupiry;
- Cubra com outra fatia de massa folhada e feche com um garfo;
- Coloque na máquina de waffles até que doure;
Carne Marinada
Ingredientes
- 1kg de carne magra (patinho ou lagarto);
- 1 xícara de chá de vinagre;
- Sal, pimenta e alho desidratado a gosto;
- Uma pitada de cominho;
- Uma folha de louro;
- Água fervendo para cobrir a carne;
- Uma cebola grande.
Modo de Preparo:
- Corte a carne em pedaços grandes, tempere com sal, pimenta, alho desidratado e cominho;
- Deixe na panela de pressão, tampada, em temperatura ambiente, por uns 20 minutos;
- Coloque a panela no fogo e mexa a carne para que ela core um pouco;
- Despeje a xícara de vinagre, a folha de louro e cubra com a água fervendo;
- Deixe cozinhar, na pressão, por pelo menos uma hora;
- Depois que a carne estiver cozida, deixe esfriar e desfie, reservando a água da panela;
- Fatie a cebola, coloque na panela onde estava reservada a água do cozimento;
- Deixe ferver por uns cinco minutos, acertando o sal e a pimenta;
- Volte a carne para esta mistura e deixe ferver por mais uns 15 minutos.
Alfajor Argentino

Ingredientes
- 200g de manteiga sem sal;
- 1 xícara de chá de açúcar;
- 4 colheres de sopa de mel;
- 1 colher de chá de essência de baunilha;
- ½ colher de sopa de bicarbonato de sódio;
- 2 colheres de sopa de fermento;
- 5 xícaras de chá de farinha de trigo, peneirada;
- 2 gemas;
- 1 ovo inteiro;
- 400g de doce de leite, de consistência firme;
- 800g de chocolate meio amargo para a cobertura.
Modo de Preparo
- Comece batendo a manteiga, açúcar, gemas, ovo, essência de baunilha e mel até ficar homogêneo;
- Vá acrescentando farinha de trigo, fermento e bicarbonato até formar uma massa homogênea;
- Polvilhe farinha em uma superfície plana e lisa e abra a massa sobre essa superfície até obter meio centímetro de espessura;
- Corte em formato circular de aproximadamente 2 cm de raio (por exemplo, a tampa do pote de fermento);
- Asse em uma assadeira enfarinhada, mas não untada por aproximadamente 12 min., até ficar levemente dourado, em forno médio pré aquecido;
- Espere esfriar e junte dois biscoitos recheando com doce de leite;
- Derreta o chocolate em banho Maria (cuidado para não deixar pingar água no chocolate), e mergulhe os biscoitos recheados;
- Coloque para esfriar sobre uma folha de papel manteiga.
Porção: Faz aproximadamente 50 alfajores.
Hambúrguer Caseiro
Ingredientes
- 1kg de carne moída (peça para moer 1kg de coxão duro);
- 1 colher de chá de pimenta calabresa;
- 1 colher de sopa de mostarda do tipo Dijon;
- 1 ovo grande;
- 1 xícara de chá de migalhas de pão fresco (farinha de rosca também serve);
- 1 xícara de chá de queijo parmesão ralado grosso;
- 1 cebola grande picada;
Preparo
- Misture todos os ingredientes até formar uma massa uniforme
- Divida em pequenas esferas e achate para fazer os hambúrgueres
- Frite os hambúrgueres junto com um pedaço de bacon, na manteiga
Cebolas Caramelizadas
Ingredientes:
- 1 cebola grande cortada em fatias finas e anelada;
- 1 colher de sopa de manteiga sem sal;
- 1 colher de sopa de azeite de oliva;
- 1 colher de chá de açúcar;
- Sal e pimenta do reino, em pó, à gosto.
Preparo
- Derreta a manteiga no azeite em fogo baixo;
- Depois que a manteiga derreter coloque a cebola, o açúcar, o sal e a pimenta;
- Cozinhe em fogo baixo, mexendo a cada dois minutos até que a cebola fique dourada;
Torta Alemã
Ingredientes
- 200g de manteiga sem sal;
- 1 xícara de chá de açúcar;
- 1 lata de creme de leite sem soro;
- 1 pacote de biscoito maizena;
- 50ml de leite (para umedecer os biscoitos);
- 1 colher de chá de conhaque.
Modo de Preparo
- Bata a manteiga e o açúcar, até formar um creme branco, fofinho e uniforme;
- Misture, delicadamente o creme de leite, sem o soro, e reserve;
- Prepare uma forma redonda, com fundo removível;
- Umedeça os biscoitos no leite misturado com o conhaque e forre, com os biscoitos, tanto o fundo da forma quanto as bordas;
- Coloque metade do creme sobre a base de biscoitos, espalhando cuidadosamente;
- Faça uma farofa grossa de biscoito maizena e espalhe por cima do creme;
- Complete com o resto de creme e cubra com mais uma camada de farofa;
- Leve ao congelador por aproximadamente 3h;
- Tire do congelador e cubra com calda de chocolate.
Quindão sem Cheiro de Ovo
Ingredientes
- 10 gemas, passadas na peneira;
- 250g de coco ralado fresco (fresco mesmo);
- 450g de açúcar;
- 1 1/2 colheres de sopa de manteiga sem sal;
- 1 colher de sopa de essência de baunilha.
Modo de Preparo
- Misture o açúcar e o coco, com a mão, amassando bem, até que o açúcar seja incorporado e a massa resultante apresente uma liga;
- Derreta um pouco a manteiga e misture na massa de coco e açúcar até ficar homogêneo;
- Na peneira, fure as gemas com um garfo, sem apertar, e espere que a película transparente que cobre a gema escorra;
- Passe a gema toda pela peneira;
- Misture a gema e a baunilha na massa com movimentos suaves e contínuos;
- Coloque a massa em uma forma de buraco, e cubra com papel alumínio;
- Coloque a forma na geladeira, pré-aqueça o forno a 200ºC;
- Coloque a forma em banho-maria, com água fervendo dentro do forno;
- Asse até secar a água, retire o papel alumínio e asse mais 10 minutos.
Torta Suíça
Nos anos 80 e 90 do século passado, a Torta Suíça era uma das sobremesas mais pedidas na loja Pão & Recheio que existia no Barrashopping, e alguns outros Shoppings do Rio de Janeiro. A Norma, que fornecia as tordas de loja em loja não revelava a receita para ninguém. Uns 20 e tantos anos depois, graças a internet e meus contatos fora do Brasil a Fran conseguiu descobrir uma receita muito parecida, enviada por um amigo alemão. E, desde então, a torta suíça é uma das sobremesas mais pedidas aqui em casa. É uma torta de chocolate, com recheio de chantilly e cobertura de chocolate. Uma delícia.
Ingredientes:
- 10 claras;
- 160g de açúcar;
- 120g de chocolate em pó;
- 15g de farinha de trigo (1 colher de sopa rasa);
- 500ml de creme de leite fresco (muito fresco);
- 50g de açúcar.
Modo de Preparo
- Prepare o chantilly: bata o creme de leite gelado até formar picos, adicione o açúcar e continue batendo até os picos ficarem firmes;
- Preaqueça o forno em 160°C;
- Use duas formas de fundo removível de 22cm, forradas com papel manteiga e untadas com manteiga;
- Bata as dez claras em neve até ficarem bem firmes, acrescente o açúcar;
- Quando a mistura ficar homogênea, acrescente o chocolate e a farinha e bata manualmente;
- Divida a massa entre as duas formas e asse ao mesmo tempo;
- Deixe esfriar, monte com uma camada de massa, o recheio de chantilly e outra camada de massa;
Risoto de Camarão
Ingredientes
- 6 colheres de sopa de manteiga sem sal;
- 1 cebola média picada;
- 2 xícaras de chá de camarões médios já limpos;
- 1 colher de chá de salsa picada;
- 1 cubo de caldo de legumes;
- 1 colher de sopa de sal;
- 2 xícaras de chá de arroz arbóreo cru;
- 1 xícara de chá de vinho branco seco;
- 5 xícaras de chá de água fervente;
- 1/2 lata de creme de leite.
Modo de Preparar
- Pique a cebola e a salsinha, separe a manteiga e ferva a água;
- Lave o arroz arbóreo e reserve;
- Derreta 3 colheres de manteiga em fogo baixo, refogue as cebolas;
- Adicione os camarões e refogue até mudarem de cor (±3 minutos);
- Acrescente a salsa picada e meia colher de sal, reserve fora do fogo;
- Em outra panela, derreta as outras 3 colheres de manteiga, refogue o resto da cebola;
- Quando as cebolas estiverem transparentes, coloque o arroz e refogue por um minuto;
- Acrescente o resto do sal, o vinho branco e cozinhe por um minuto;
- Acrescente o caldo de legumes e a água fervente, aos poucos, mexendo sem parar;
- Quando o arroz estiver “al dente”, acrescente os camarões e o creme de leite.
Brownie de Ricota
Ingredientes (brownie)
- 1/2 xícara de manteiga sem sal;
- 60g de chocolate amargo, picado;
- 3 colheres de mesa de chocolate sem açúcar;
- 1 xícara de açúcar refinado;
- 2 ovos grandes a temperatura ambiente;
- 1 colher de chá de extrato de baunilha;
- 2/3 de xícara de farinha de trigo;
- 1/4 de colher de chá de sal.
Ingredientes (ricota)
- 230g de ricota integral;
- 1/3 xícara de açúcar refinado;
- 1 colher de sopa de farinha de trigo;
- 1 ovo grande em temperatura ambiente;
- 1/2 colher de chá de extrato de baunilha.
Modo de Preparo
- Pré-aqueça o forno a 220ºC e prepare uma forma pequena com papel alumínio untado;
- Derreta a manteiga e o chocolate no micro-ondas, misture bem;
- Acrescente o chocolate em pó e mexa até ficar uniforme;
- Em uma tigela maior, misture o açúcar, ovos e baunilha até ficar uniforme;
- Adicione a mistura de chocolate e continue batendo;
- Acrescente sal e farinha, batendo até ficar consistente e uniforme;
- Coloque esta massa na forma;
- Para a massa de ricota, bata a ricota com açúcar, farinha, ovo e baunilha;
- Despeje sobre a base do brownie e gentilmente espalhe;
- Com um garfo, faça espirais nas massas para que apareçam os dois sabores;
- Asse em forno alto por 35 minutos ou até não grudar na faca;
- Sirva gelado.
Medalhão de Filé Mignon
Ingredientes
- Medalhões de filé mignon;
- Tiras de bacon;
- Sal e pimenta do reino a gosto.
Modo de Preparo
- Corte a peça de filé em medalhões de aproximadamente 3cm de espessura;
- Corte o bacon em tiras finas e amarre em torno dos medalhões com barbante;
- Prepare uma frigideira com azeite e unte os medalhões dos dois lados;
- Aplique pimenta dos dois lados e frite por 2-3 minutos cada lado para selar;
- Aplique sal em cada lado antes de selar;
- Leve ao forno a 200ºC por 15 minutos.
Clafoutis de Cerejas e Amêndoas
Ingredientes
- 500g de cerejas vermelhas naturais, sem sementes e sem ramo;
- 100g de amêndoas cruas e sem sal;
- 150g de açúcar refinado;
- 15g de farinha de trigo;
- 350g de creme de leite fresco;
- 4 ovos inteiros;
- 5 gemas.
Modo de Preparo
- Toste as amêndoas ligeiramente na grelha;
- Misture o açúcar, as amêndoas e a farinha em uma tigela;
- Acrescente o creme de leite, as gemas e os ovos e misture cuidadosamente;
- Deixe descansar na geladeira;
- Pré-aqueça o forno a 180 graus e unte uma forma com manteiga;
- Salpique farinha na forma, despeje a massa e espalhe as cerejas cortadas;
- Asse até que a superfície fique dourada (±40 min);
- Polvilhe um pouco de açúcar de confeiteiro e sirva quente.
Bobó de Camarão
Ingredientes
- 1kg de camarão rosa;
- 1kg de mandioca em pedaços médios;
- 1/2 pimentão vermelho picado;
- 1/2 pimentão verde picado;
- 3 tomates sem pele e sem sementes;
- 1 cebola grande picada;
- 3 dentes de alho picados fininho;
- 1/2 xícara de chá de azeite de dendê;
- 1 colher de sopa de azeite de oliva;
- Uma garrafinha de leite de coco;
- Coentro, pimenta de cheiro e sal a gosto.
Modo de Preparo
- Descasque e limpe os camarões, ferva as cabeças e cascas em água com sal, filtre e reserve o líquido;
- Retire o fio da mandioca, corte em pedaços e cozinhe com metade de água limpa e metade da água do camarão;
- Quando a mandioca estiver macia, bata até obter um creme uniforme;
- Frite os camarões rapidamente no azeite de oliva com sal e limão, reserve;
- Na mesma panela, faça um refogado com cebola e pimentões;
- Acrescente a massa de mandioca e deixe ferver por 5 minutos;
- Misture o camarão, o refogado e o azeite de dendê;
- Acrescente o leite de coco, acerte o sal e adicione coentro e pimenta de cheiro a gosto.
Massa base para rechear feita na máquina de pão
Esta massa é um coringa que usamos aqui em casa. É rápida, simples, usa poucos ingredientes e fica deliciosa. Direto na máquina de pão, para não perder tempo.
Aqui em casa, sempre que não temos nada bem decidido para o jantar, acabamos com essa massa na máquina. Doce, recheada com goiabada e queijo Catupiry, ou salgada com presunto e queijo, acompanhada de refrigerante e pronto.
Ingredientes
- 15 g de fermento fresco (meio envelope);
- 1/2 colher de sobremesa de sal;
- 1 colher de sobremesa de açúcar;
- 1/4 de xícara de chá de óleo (usamos canola);
- 1 xícara de chá de água morna;
- 3 xícaras de chá de farinha de trigo;
- 1 colher de sopa de leite em pó.
Modo de preparo
Misture todos os ingredientes na máquina de pão e ajuste para massa. Depois que a máquina apitar, indicando que a massa está pronta, em uma superfície lisa, estique a massa com o rolo até que fique com um dedo de espessura ou menos. Enrole o recheio. Pincele gema de ovo sobre a massa e asse em forno médio por 20 minutos, 25 no máximo.
Uma opção é, antes de assar, cortar a massa em fatias. Espalhar as fatias por um tabuleiro grande e salpicar queijo ralado sobre as fatias. Já sairão do forno gratinadas.
Creme de Milho, simples, fácil e delicioso
Às vezes chegamos tarde da noite, nada há para comer, tudo demora… Nestes dias corridos, é bom ter um coringa no bolso. Aqui em casa é o creme de milho. Simples, rápido e fácil, esta receita acompanha uma carne moída bolonhesa ou um bom contrafilé na chapa.
Ingredientes
- Uma lata de milho;
- Uma lata de leite;
- 25g de queijo parmesão ralado;
- Uma colher de sopa de amido de milho;
- Uma cebola picada;
- Azeite e sal a gosto.
Modo de Preparo
- Pegue a cebola e pique bem pequenininho. E reserve.
Dica: Para picar a cebola sem chorar, corte perto da janela ou ligue um ventilador para espalhar os gases que a cebola libera e irritam os olhos, cortar a cebola debaixo da água. Por fim, você também pode usar óculos de mergulho.*
-
Coloque o milho, o queijo, o leite e o amido de milho no liquidificador e bata até que a mistura se torne um líquido homogêneo. Use a lata de milho para medir o leite.
-
Em uma panela pequena, coloque o azeite e a cebola picada e refogue até que as cebolas comecem a dourar. Nem mais nem menos, cuide para que os pedaços de cebola não queimem.
-
Quando os pedaços de cebola começarem a picar, deposite a mistura do liquidificador e mexa até que reduza e se torne um creme espeço, destes que não caem da colher.
Para servir, passe por uma peneira bem fina. E aproveite.
Dica: Lave a lata de milho antes de abir e antes de usar para medir o leite. Quando tiver aberto mais ou menos a metade da lata de milho, despeje o liquido de conserva. E, retire toda a tampa da lata. Na hora de separar o lixo para reciclar, a tampa totalmente separada é mais segura.*
O Hambúrguer da Família
Aqui em casa, andamos experimentando uma dieta completamente nova. Cada dia uma comida diferente. Na quarta é dia de Hambúrguer. Esta receita é nossa, fomos desenvolvendo, testando e provando, até chegar a esta recita que agrada a todos e faz a quarta melhor.
Ingredientes
- Hambúrguer;
- Queijo Mozzarella;
- Alface, tomate e cebola;
- Maionese, catchup;
- Molho de pimenta calabresa e molho shoyo;
- Bacon;
- Pão de Hambúrguer com gergelim.
Modo de preparo
-
Lave a alface e seque. Seque bem, não deixe nem uma gotinha de humidade. A alface seca servirá para isolar o molho e o pão evitando aqueles sanduíches molhados que vemos por ai. Reserve.
-
Corte o tomate em círculos e a cebola em anéis.
-
Em uma frigideira, coloque a cebola e molho shoyo suficiente para cobrir o fundo da frigideira. Coloque duas colheres de água e frite as cebolas até reduzir. Reserve.
-
Corte o bacon em cubos bem pequenininhos e frite na sua própria gordura. Frite até que o bacon fique com a textura de torresmo. Reserve.
-
Em um copo, coloque duas colheres de sopa de maionese, uma colher de sopa de catchup e uma colher de chá de molho de pimenta calabresa. Misture até que fique homogêneo. Reserve.
-
Coloque os hambúrgueres para fritar. E quando estiverem quase prontos, coloque o queijo para derreter sobre ele.
-
Corte o pão no meio e toste ambos os lados até que a parte de cima do miolo fique crocante. Forre um dos lados com a alface. Espalhe sobre ela o molho a gosto e, sobre o molho coloque os tomates.
-
Sobre os tomates coloque a cebola frita no shoyo. Sobre elas coloque o hambúrguer com o queijo derretido e, sobre este espalhe alguns pedaços de bacon.
Sirva no prato, ou na mão, acompanhe com vinho tinto ou refrigerante bem gelado.
Como fazer a pipoca perfeita, sem nunca queimar
Aqui em casa, pipoca é coisa séria. Já escrevemos sobre isso antes em como fazer pipoca doce. Agora é hora de contar nosso truque, um verdadeiro passo a passo, para não queimar as pipocas e estourar todos os grãos.
Preparo
- Use banha de porco fresca e manteiga;
- Derreta a banha. O suficiente para ficar uma camada que cubra o fundo da panela e fique no meio do milho;
- Coloque três grãos de milho no óleo e espere espocar;
- Quando o terceiro grão tiver espocado retire a panela do fogo e coloque o resto do milho (1/2 copo);
- Espere 30 segundos. Este é o truque;
- Volte a panela para o fogo, acrescente uma colher de manteiga e mexa;
- Espere até parar de estourar.
Proto. Corra para o fogão!
Dica: o tempo que a panela fica fora do fogo permite que todos os grãos atinjam a mesma temperatura. Observe também que a quantidade de milho vai depender do tamanho da sua panela. O ideal é que todos os grãos fiquem no fundo sem se sobrepor.
Receita de Brownies Fantásticos
Ingredientes
- 1 1/2 xícara de chá de farinha de trigo;
- 10 colheres de sopa de chocolate em pó;
- 2 xícaras de chá de açúcar;
- 1 xícara de chá de nozes picadas;
- 1 pitada de sal;
- 4 ovos grandes;
- 1/2 xícara de chá de óleo;
- 1/2 xícara de margarina derretida (sem sal);
- 1 colher de café de fermento em pó;
- 2 colheres de café de essência de baunilha.
Modo de Preparo
-
Ligue o forno em médio e comece a receita.
-
Junte todos os secos em uma tigela e misture-os. Derreta a manteiga em uma tigela separada, cuidado para não escurecer a manteiga. Bata os 4 ovos em uma tigela e bata rapidamente. Pingue a baunilha sobre os ovos e misture a manteiga derretida com os ovos e mexa. Jogue essa mistura sobre os ingredientes secos e misture bem. Muito bem.
-
Coloque a mistura em formas pequenas, separadas e asse em forno médio por 40 minutos.
Dica: troque as nozes por castanha do pará ou amendoim. No primeiro caso os brownies ficam mais pesados, no segundo mais leves.
Receita de Pipoca Doce de pipoqueiro
Ingredientes
- 1 xícara de milho de pipoca;
- 2 colheres de sopa de óleo vegetal ou banha de porco;
- 2 colheres de sopa de açúcar refinado;
- 1 colher de chá de chocolate em pó (ou achocolatado);
- canela a gosto.
Modo de preparo
- Pegue as duas colheres de açúcar, coloque em um cope e misture com o chocolate em pó. Misture bem até que fique homogêneo e reserve;
- Pegue uma panela com uns 25 cm de diâmetro e espalhe a banha, ou o óleo, no fundo. Coloque um único grão de milho de pipoca e espere pipocar;
- Depois que o primeiro grão estourar coloque o resto todo e, com uma colher de pau, mexa até que outro milho pipoque;
- Assim que o segundo milho pipocar despeje a mistura de açúcar com chocolate e continue misturando até que outro milho pipoque;
- Feche a panela. Se for uma pipoqueira, continue misturando. Se não sacuda a panela para cima e para baixo, segurando a tampa até que todos os milhos tenham estourado;
- Se queimar algum grão é por que você misturou, ou sacudiu, pouco;
- Coloque uma pitada de canela sobre as pipocas e bom filme.
Restou de Ontem - tainha!
Aqui em casa, tainha é coisa séria. O peixe é um dos mais saborosos que existem. E, quando assado, fica ainda mais gostoso. Mas, como todo peixe, não pode sobrar. O que sobrar, tem que ser aproveitado. Aqui em casa, o que sobrou da tainha assada é um prato delicioso e fácil de fazer.
Ingredientes
- Sobras da tainha assada (sem pele e espinhas);
- 1/2 lata de milho verde;
- 1/2 lata de ervilha;
- cebolinha verde picadinha.
Modo de Preparo
Desfie as sobras da tainha, coloque em uma frigideira antiaderente para aquecer. Evite mexer para não despedaçar por completo. Quando já estiver quente, acrescente o milho, a ervilha e a cebolinha. Dê uma leve mexida para que todos os ingredientes fiquem bem misturados. Tampe a frigideira, e deixe uns 3 minutos no fogo bem baixinho. Está pronta.
Bolo de Ricota e Batata
Ingredientes
- 250g de ricota amassada;
- 500g de batata;
- 2 colheres de sopa de manteiga;
- 2 cubinhos de caldo de galinha;
- 1 xícara de chá de leite fervente;
- 1/2 xícara de chá de queijo parmesão ralado;
- 3 ovos;
- noz-moscada a gosto.
Modo de Preparo
Cozinhe as batatas e passe no espremedor. Dissolva os cubinho de caldo de galinha no leite. Em uma bacia misture as batatas espremidas, manteiga, leite, ricota, queijo parmesão, gemas e a noz-moscada. Bata as claras em neve firme e incorpore delicadamente a massa. Coloque a massa em um refratário untado e polvilhado com farinha de rosca. Asse em forno médio, preaquecido, por aproximadamente 45 minutos.
Receita de Cookie
Na década de 80, Cora Ronai, uma colunista do Jornal O Globo, publicou uma receita de cookie em uma coluna de informática do jornal O Globo. Com uma história interessante sobre a receita. Eu recontei esta história no post original.
Desde então, estes cookies viraram uma tradição de natal da minha família.
Ah!, já ia esquecendo, eu tenho a folha original do jornal até hoje.
Ingredientes
- 2 xic. chá de manteiga sem sal;
- 4 ovos;
- 2 colheres de chá de bicarbonato de sódio;
- 1 xic. chá de aveia batida no liquidificador até ficar bem fininha;
- 1 xic. de chá de açúcar mascavo;
- 1 col. de chá de fermento;
- 200g de chocolate meio amargo picado;
- 1 col. de chá de essência de baunilha;
- 2 xic. de chá de farinha de trigo;
- 1 xic. de chá de açúcar;
- 500g de gotas de chocolate (eu uso garoto);
- 1 col. chá de sal;
- 3 xic de chá de nozes ou castanhas picadinha (eu uso castanha de caju).
Modo de Preparo
-
Bata na batedeira a manteiga com o açúcar mascavo e o branco até fazer um creme bem fofo e homogêneo. Acrescente os ovos e a baunilha enquanto bate.
-
Em uma bacia junte a aveia, farinha, bicabornato, fermento e o sal e misture todo.
-
Quando o creme da batedeira estiver bem fofo, despeje sobre a mistura de farinha e mexa bem até tudo estar bem incorporado.
-
Acrescente o chocolate picado, as castanhas e as gotas de chocolate. Misture tudo muito bem.
-
Forme bolinhas, coloque em um tabuleiro untado levemente, com bastante espaço entre as bolinhas, elas se desfazem com o calor e tomam a forma do cookie.
-
Pré aqueça o forno em médio (ligue o forno qdo começar a fazer a massa) e asse por 10 a 15 minutos assim que tirar do forno eles estarão molinhos, dando a impressão que não estão assados. Não se preocupe, assim que esfriarem ficarão perfeitos.
Bolo de Chocolate do Miúdo!
Nosso filho não é mais miúdo, mas o bolo de chocolate é o mesmo. Quando ele era pequeno era o que conseguíamos fazer nas festas de aniversário. Com tempo, virou a receita oficial de bolo de chocolate da casa. E, como todo bolo de chocolate, é uma delícia.

Ingredientes:
- 2 xícaras de chá de açúcar;
- 3 ovos 1/2 xícara;
- de chá de manteiga sem sal (em temperatura ambiente);
- 2 xícaras de chá de farinha de trigo;
- 1 xícara de chá de chocolate em pó (n serve achocolatado);
- 1 xícara de chá de leite;
- 1 colher de sopa de fermento em pó.
Recheio e cobertura:
- Ganache 300g de chocolate ao leite (ou meio amargo se preferir);
- 1 lata de creme de leite (300g);
Modo de Preparo
Bolo:
Acenda o forno em temperatura média; Misture a farinha de trigo com o chocolate em pó. Bata as claras em neve e reserve. Bata o açúcar, as gemas e a manteiga até formar um creme esbranquiçado e fofo. Sem parar de bater vá acrescentando a mistura de farinha alternando com o leite. Desligue a batedeira e misture delicadamente as claras e o fermento. Despeje em forma untada e enfarinhada e asse em forno médio. Espere esfriar. Desinforme e corte o bolo ao meio, para poder rechear.
Recheio:
Em banho maria, derreta o chocolate junto com o creme de leite, formando um Ganache. Separe uma parte para a cobertura. Recheie o bolo e cubra com o ganache reservado. Aí é só se deliciar. Se desejar, use brigadeiro mole para o recheio e Ganache para a cobertura.
Salame de chocolate
Ingredientes
- 1 lata de leite condensado;
- 6 colheres de sopa de achocolatado;
- 1 colher de sopa de mel;
- 1 colher de sobremesa de manteiga;
- meia xícara de chá de castanhas de caju picadas;
- 3 colheres de sopa de chocolate branco picado grosseiramente. (Opcional);
- Papel alumínio para embalar.
Modo de Preparo
Em uma panela misture o leite condensado, o achocolatado, o mel e a manteiga. Cozinhe em fogo brando, mexendo sempre até começar a desprender do fundo da panela. O ideal é tirar do fogo um pouquinho antes do ponto de enrolar o brigadeiro. Depois de desligar o fogo acrescente as castanhas até ficar bem incorporado e depois faça o mesmo com o chocolate branco. Pegue um bom pedaço de papel alumínio e despeje o brigadeiro sobre ele; Feche com se estivesse enrolado uma bala, cuidando para q fique numa forma cilíndrica. Deixe esfriar, leve a geladeira por no mínimo 2 horas. Corte fatias finas para servir; não precisa desenrolar o papel alumínio.
Opção: as castanhas podem ser substituídas por amendoim, nozes, avelãs, pistache, castanha do pará, de acordo com seu desejo.
Bom apetite!
Bombons de chocolate, rápidos e deliciosos
Use chocolate sem gordura hidrogenada, meio-amargo ou ao leite. Meio quilo basta, você fará aproximadamente 60 bombons.
Quebre a barra de chocolate em pedaços pequenos e derreta em banho maria. Lembre-se que para chocolate as panelas devem ser quase do mesmo tamanho, para que uma encaixe na outra e não permita que gotas de água caiam no chocolate. Outra coisa que você não pode esquecer é de desligar o fogo assim que a água ferver.
Uma vez que o chocolate tenha derretido, tire a panela do banho maria e coloque em dentro de um outro recipiente, desta vez com água a temperatura ambiente. E comece a temperagem. Mexa lentamente o chocolate, sempre para o mesmo lado até que ele atinja a temperatura de 29 graus centígrados. Não tem um termômetro por ai? Não se preocupe, use um palito de dentes e vá testando a temperatura no punho ou no bigode. Você vai estar no ponto certo quando sentir que o chocolate está geladinho.
Misture um copo de flocos de arroz e meio copo de castanha de caju picada no chocolate. Um de cada vez, sempre misturando bem.
Coloque nas formas, bata as formas contra uma superfície plana para assentar os bombons e coloque na geladeira por 10 minutos.
Se você tiver acertado o ponto da temperagem, eles vão ficar sólidos e não derreterão facilmente na mão, se não, assim que você pegar eles começaram a derreter.
A primeira vez você vai gastar mais de meia hora para fazer, depois fica mais simples e você vai poder incluir outros ingredientes. Que tal umas passas?
Bolinhos de Bacalhau
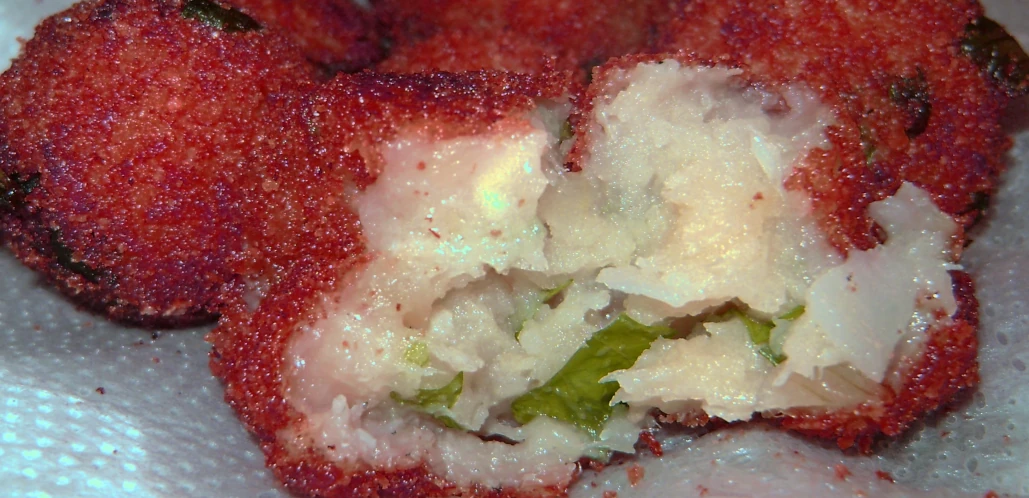
Ingredientes
- 250 g de bacalhau;
- 250 g de batata;
- 2 colheres (sopa) de farinha de trigo;
- 1 cebola, picada;
- 2 dentes de alho, picados;
- 3 colheres (sopa) de azeite;
- 1 xícara (chá) de farinha de rosca;
- ½ xícara (chá) de salsa, picada;
- 1 l de óleo;
- papel toalha, o quanto baste;
- sal e pimenta-do-reino, a gosto;
Modo de Preparo
-
Desalgue o Bacalhau - Comece dois dias antes, a noite. Coloque o bacalhau todo em uma tigela grande com aguá gelada no fundo da geladeira e deixe dormir lá. Na manhã seguinte troque toda a água por mais água gelada. Repita a troca a noite e deixe dormir novamente na geladeira. Repita todo o processo no dia seguinte e no terceiro dia seu bacalhau estará desalgado. Lembre que o sal do bacalhau é para conservar o peixe não para temperar sua comida. :)
-
Pique os Temperos - Pique o alho, a cebola e a salsinha e reserve.
-
Prepare a Batata - Descasque e corte as batatas em cubos e coloque que cozinhar. Cozinhe em pouca água. só o suficiente para cobrir as batatas, até que fiquem macias. Quando estiverem prontas, escorra a água e deixe as batatas em uma peneira para escorrer e esfriar isso vai tirar mais umidade delas.
-
Preparando o Bacalhau - Coloque o bacalhau para ferver em água suficiente para cobrir a peça deixando um cm de folga, mais ou menos. Preste atenção. Quando ferver espere 5 minutos e desligue. Deixe esfriar.
-
Juntando Tudo - Enquanto o bacalhau esfria, passe as batatas pelo espremedor para fazer um purê. Depois que o bacalhau estiver frio, desfie-o com as mãos cuidando de tirar as eventuais espinhas, toda pele e gordura que encontrar. Coloque o azeite em uma penela, acrescente a cebola e o alho e refogue por uns 4 minutos. Acrescente o bacalhau, desfiado e desalgado e misture tudo muito bem e deixe cozinhar por uns 5 minutos. Desligue o fogo e deixe esfriar. Depois de frio, misture a batata, a farinha de trigo, a salsinha, coloque sal e pimenta do reino á gosto e misture bem fazendo um purê uniforme.
-
Fritando os Bolinhos - Coloque óleo suficiente em uma panela para cobrir os bolinhos e espere que o óleo esquente. Aqui em casa usamos o truque do fósforo. Coloque um fósforo no óleo e espere ele acender. Quando acender o óleo está na temperatura certa.
-
Prepare os bolinhos enrolando-os com as mãos no formato que desejar e passando na farinha de rosca.
-
Coloque os bolinhos para fritar. Usamos uma penela pequena e temos que fritar de oito em oito. Quando colocamos os bolinhos o óleo espuma, muito. Quando a espuma do óleo baixar está na hora de olhar os bolinhos. Tente faze-los dourados.
-
Use uma escumadeira para retirá-los da panela e não esqueça de colocá-los em um papel toalha para retirar o excesso de óleo. Devem ficar secos. Crocantes por fora e macios por dentro.
Pudim de Sorvete
Ingredientes Pudim:
- 3 ovos;
- 1 lata de leite condensado integral;
- A mesma medida de leite (use a lata de leite condensado como medida);
- 1 lata de creme de leite;
- 5 gotas de essência de baunilha;
- 3 colheres de sopa de açúcar.
Ingredientes Calda
- 3 colheres de sopa de chocolate em pó;
- 6 colheres de sopa de leite;
- 2 ½ colheres de sopa de açúcar;
- 1 colher de sopa de manteiga sem sal.
Modo de Preparo
Calda
Em uma panela pequena misture todos os ingredientes, leve ao fogo mexendo sempre até engrossar. Unte uma forma de furo no meio com essa calda e reserve.
Pudim
-
No liquidificador, bata o leite condensado, o leite, a essência de baunilha e as gemas dos ovos. Passe essa mistura para uma panela e leve ao fogo médio, mexendo sempre até engrossar. Reserve até esfriar.
-
Na batedeira, bata as claras em neve vá acrescentando o açúcar, cada colher de uma vez. Bata até ficar bem firme. Desligue a batedeira e misture o creme de leite delicadamente. Depois disso (com o creme que foi cozido já frio) incorpore o creme também de modo bem delicado.
-
Despeje essa mistura na forma untada com a calda de chocolate, leve ao congelador por aproximadamente 3 horas e está pronto.
-
Para desenformar, mergulhe rapidamente o fundo da forma em água fervente.
Licor de Café
Ingredientes
- 250g de café em grão torrado;
- 1kg de açúcar;
- 1 litro de cachaça;
- 1/2 litro de água;
Modo de Preparo
Deixe de molho durante um mês, Passados os 30 dias, ferva 1/2 litro de água com 1kg de açúcar, sem que chegue ao ponto de fio. Apague o fogo, pegue um coador e passe a cachaça com os grãos de café dentro da calda. Para finalizar, coe num coador muito fino para uma garrafa.
E saúde…!
Receita de Rabanada da Família. Uma delícia de Natal
A mais antiga tradição de natal da família Alcantara. Coisa muito, muito séria e inevitável. Todo ano, no dia 24 de dezembro, a família se reúne para fazer as rabanadas. Uma tradição que vem de muito tempo e que não pode ser quebrada. A receita é simples e fácil de fazer. O resultado é uma delícia.

Ingredientes
- 1 lata de leite condensado;
- ½ litro de leite;
- 10 gotas de essência de baunilha;
- 6 ovos;
- 8 pãezinhos (pode ser francês dormido ou ciabatta);
- Açúcar (aproximadamente 1 xícara de açúcar);
- Canela em pó (o suficiente para dar sabor ao açúcar);
- Óleo para fritar (aproximadamente ¼ de litro);
- Papel toalha.
Modo de preparo
- Misture o açúcar com a canela e reserve;
- Fatie o pão em fatias finas e reserve.
- Em uma vasilha rasa misture o leite condensado, o leite e a essência de baunilha;
- Em outra vasilha rasa bata 2 ovos ligeiramente (os demais ovos você irá colocando nessa vasilha e batendo conforme for usando);
- Umedeça ligeiramente o pão no leite e em seguida no ovo batido; repita esse processo para cada fatia de pão. Cuide para que o pão não fique muito amolecido;
- Frite em óleo bem quente (ela deve ficar bem douradinha dos dois lados);
- Escorra no papel toalha e depois passe rapidamente na mistura de açúcar com canela.
Dica: para saber a temperatura correta do ponto de fritura jogue um palito de fósforo na frigideira, quando ele acender esse será o ponto certo para a fritura. Retire o palito e inicie o processo de fritar as rabanadas.
Bolo de passas e castanhas para o dia de reis

Ingredientes
- 200g de manteiga sem sal;
- 8 ovos;
- 1 xícara de chá de açúcar;
- 2 xícaras de chá de farinha de trigo;
- 2 colheres de chá de fermento em pó;
- 150g de passas sem sementes;
- 150g de castanha do Pará picadas.
Modo de Preparo
-
Bata a manteiga com o açúcar por aproximadamente 5 minutos, a partir daí vá acrescentando as gemas, uma a uma até formar um creme claro e fofo. Depois disso acrescente a farinha de trigo e fermento, misture bem, acrescente as passas e as castanhas. Por último acrescente as claras batidas em neve, misture delicadamente.
-
Coloque a massa em forma untada com manteiga.
-
Asse em forno médio, (preaquecido por 10 minutos) por aproximadamente 40 minutos.
As vezes, tudo que você quer é uma caneca de bolo!
Ingredientes
- Uma caneca grande que possa ser usada no Micro ondas;
- Uma colher para fazer a mistura;
- 4 colheres de sopa de farinha;
- 9 colheres de sopa de mistura de chocolate ou achocolatado;
- 1 ovo;
- 3 colheres de sopa de água;
- 3 colheres de sopa de óleo (arrrrgh! vou tentar com uma só…);
- um pouco de manteiga para untar.
Modo de Preparo
Unte a caneca com a manteiga/margarina, misture a farinha e o chocolate e quebre o ovo sobre eles. Misture bem. Depois adicione a água e o óleo e misture novamente. Misture muito bem e certifique-se que não ficou farinha ou chocolate preso no fundo da caneca sem misturar.
Coloque no micro-ondas por aproximadamente 3 minutos.
Frango vestido de Festa
Ingredientes
- 500g de filé de frango cortado em tirinhas;
- 1 sachê de tempero de frango;
- 1/2 lata de milho verde;
- 1 1/2 xícara de molho branco;
- Fatias de mussarela;
- Queijo parmesão ralado para polvilhar.
Para preparar o molho branco:
- 1/2 cebola bem picadinha;
- 1 pitada de noz moscada;
- 1 pitada de sal;
- 1 pitada de pimenta branca moída;
- 1 colher de sopa de manteiga;
- 1 1/2 colher de farinha de trigo;
- 2 xícaras de chá de leite.
Modo de Preparo
Tempere o frango com tempero de frango e coloque em uma forma refratária, não precisa untar, leve ao forno até estar cozido, aproximadamente 20 minutos em forno médio. Retire o frango do forno e se certifique que está cozido. Despeje sobre ele o molho branco, o milho verde, cubra com mussarela e polvilhe queijo parmesão por cima. Retorne ao forno e deixe até a mussarela estar completamente derretida.
Sirva imediatamente. Acompanhe com arroz branco e salada verde.
Para o Molho Branco:
Refogue a cebola na manteiga até ficar transparente, adicione sal, noz moscada, pimenta e a farinha de trigo; mexa muito bem e vigorosamente, vá acrescentando o leite e mexendo até dissolver todos os carocinhos e ficar bem homogêneo. Deixe ferver até ficar grosso e está pronto. Se ficar muito grosso, acrescente um pouco mais de leite até ficar na consistência desejada. Prove e acerte o sabor ao seu paladar.
Calda de Chocolate
Ingredientes:
- 2 xícaras de chá de leite;
- 1 colher de sopa de manteiga;
- 7 colheres de sopa de achocolatado ou chocolate em pó.
Se você usar achocolatado a calda vai ficar com o sabor mais suave. Se usar o chocolate em pó você obterá um sabor de chocolate meio amargo.
Modo de Preparo
Leve os ingredientes ao fogo brando por no mínimo 10 minutos. Cuide para não derramar da panela. De vez em quando dê uma mexida para conferir o ponto que deseja. Quanto mais tempo ficar no fogo mais grossa sua calda vai ficar. Se você deseja deixar a calda na geladeira, cuide para que ela não fique muito grossa, porque quando ela esfria, naturalmente ela já dá uma engrossada.
Salada de Soja
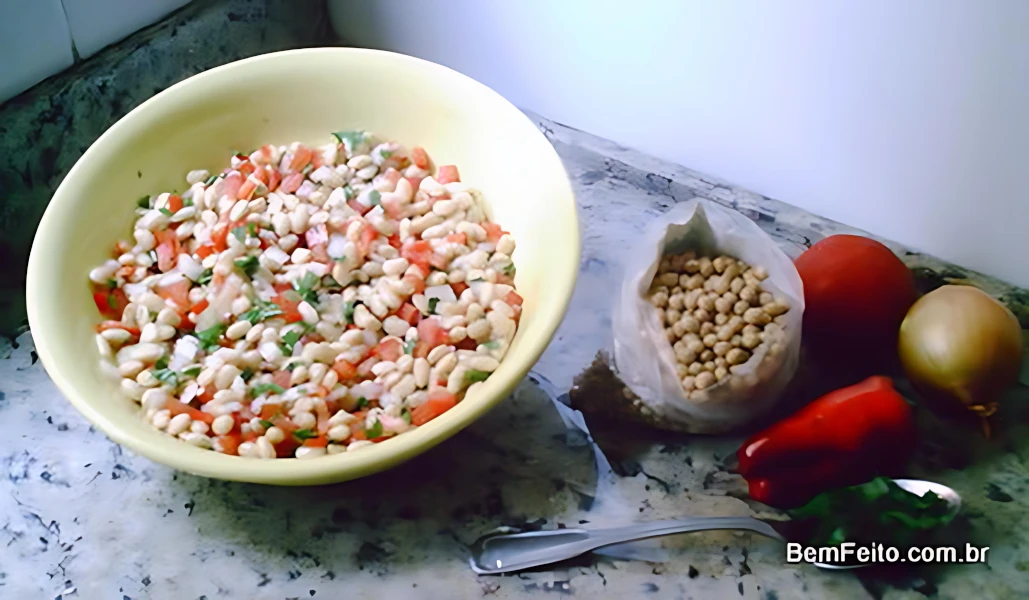
Ingredientes
- 1 xícara de chá de grãos de soja;
- 1/2 cebola picadinha;
- 1 tomate picadinho, sem sementes;
- 1 pimentão vermelho pequeno, picadinho;
- cheiro verde fresco picadinho, a gosto (eu gosto de usar coentro também);
- 2 a 3 colheres de sopa de azeite;
- sal, pimenta, noz moscada a gosto.
Modo de Preparo
Para cozinhar a soja: leve ao fogo 3 xícaras de chá de água e quando estiver fervendo acrescente 1/2 colher de café de bicarbonato de sódio; despeje a soja nessa água (não precisa lavar antes) e cozinhe em fogo baixo por 5 minutos. Escorra a água, lave a soja em água corrente. Coloque novamente uma panela com 4 xícaras de chá de água, leve ao fogo e quando ferver, acrescente 1/2 colher de café de bicarbonato de sódio, acrescente a soja (agora lavada e escorrida) e deixe cozinhar por no mínimo 20 minutos, em fogo baixo. Quanto mais tempo a soja cozinha mais macia ela fica. Para a salada, deixe o grão ao dente. Depois de cozida, escorra toda a água (vai soltar as casquinhas do grão), coloque a soja em uma bacia, misture a cebola, tomate, pimentão, cheiro verde, azeite e condimentos, misture bem e está pronta.
Torta de Chocolate
Ingredientes
- 3 ovos;
- 90g de açúcar;
- 90g de farinha de trigo peneirada;
- 100g de chocolate meio amargo;
- 300ml de creme de leite fresco;
- cerejas picadinhas;
- 2 colheres de sopa de cacau em pó;
- licor de sua preferência.
Modo de Preparo
Massa:
-
bata os ovos com o açúcar até ficar bem homogêneo e criar espumas. Acrescente a farinha de trigo delicadamente e vá mexendo até ficar novamente homogêneo.
-
Unte e enfarinhe uma forma redonda; coloque a massa e asse em forno preaquecido, de médio para baixo, por aproximadamente 15 minutos. Depois de assado leve à geladeira.
Ganache: derreta o chocolate (pode ser no microondas ou em banho-maria), quando tiver derretido o chocolate misture 100ml de creme de leite fresco.
Creme de chocolate: use os 200ml de creme de leite restante para fazer um chantilly; misture metade do chantilly ao ganache, essa mistura vai virar o creme de chocolate.
Montando a torta: corte a massa em duas partes (para obter 3 discos de massa fina). Coloque o primeiro disco de massa, regue com um pouco de licor e espalhe o creme de chocolate (deixe uma parte para cobrir a torta), cubra com outro disco de massa; novamente regue o disco com um pouco de licor, espalhe o chantilly e por cima as cerejinhas picadas; cubra com o último disco de massa. Sobre a torta montada, espalhe a outra parte do creme de chocolate, e por último polvilhe o cacau em pó.
Está pronta. Leve para gelar e depois delicie-se.
Muffins

Ingredientes
- 2 xícaras de chá de farinha de trigo;
- 1/2 xícara de chá de açúcar;
- 3/4 de xícara de chá de leite;
- 2 ovos;
- 4 colheres de sopa de manteiga sem sal, derretida;
- 10 gotas de essência de baunilha;
- 2 colheres de chá de fermento.
Modo de Preparo
-
Peneire a farinha de trigo, o açúcar e o fermento; misture-os bem e reserve. Em outra vasilha bata os ovos ligeiramente, acrescente o leite, a essência de baunilha e a manteiga derretida, misture bem. Despeje o líquido sobre os ingredientes secos, misturando rapidamente (não bata em excesso). A massa não deve ficar lisa.
-
Se desejar incrementar a massa, você pode acrescentar 1/2 xícara de chá de gotas de chocolate, ou 1 banana nanica amassada, ou 1/2 xícara de chá de castanhas, ou 1/2 de xícara de chá de frutas cristalizadas.
-
Unte forminhas e coloque massa só até a metade da altura da forma.
-
Asse em forno médio, pré-aquecido por aproximadamente 25 minutos.
Serve 12 unidades.
Dica: uma boa maneira de saber o tempo de pré-aquecer o forno é ligá-lo no momento que você começar a preparar a massa.
Aperitivos com massa de pastel
Ingredientes:
- massa de pastel em rolo (daquelas que compramos inteiras);
- manteiga;
- queijo ralado, ervas finas, orégano.
Modo de Preparo
Corte tiras da massa de pastel, de aproximadamente 2cm de largura, arrume-as em uma assadeira (não precisa untar), pincele cada tira com manteiga e polvilhe queijo ralado ou orégano ou ervas finas ou outro temperinho que dê o sabor de sua preferência. Asse em forno médio, por aproximadamente 12 minutos, ou até que as tirinhas fiquem levemente douradas e sequinhas. Agora é só saborear.
Cozido de Lentilha
Ingredientes
- 300g de lentilha;
- 2 paios pequenos cortados em cubos;
- 2 dentes de alho cortados ao meio;
- 2 folhas de louro;
- 1 sachê de caldo de carne;
- salsinha picada a gosto;
- 1 cebola picada;
- 2 tomates picados;
- 15 a 20 azeitonas sem caroços;
- 50g de bacon cortado em cubinhos.
Modo de Preparo
Cozinhe em panela de pressão a lentilha, paio, louro, alho, com 2 copos de água. Deixe cozinhar por 20 minutos depois de pegar a pressão. A parte, frite o bacon, quando estiver bem douradinho acrescente a cebola, tomates, azeitonas e o caldo de carne, refogue tudo muito bem e despeje na panela com a lentilha cozida, misture delicadamente para a lentilha não desmanchar muito; prove para sentir o sabor do sal, se necessário acrescente mais um pouco de água para formar o caldo e cozinhe por mais 5 minutos com a panela destampada.
Ganache de Limão
Ingredientes
- 1 lata de leite condensado;
- Suco de 2 a 3 limões;
Modo de Preparo
Coloque o leite condensado em uma vasilha e vá pingando o suco de limão e misturando vagarosamente. Vá provando para sentir o sabor que você deseja que fique (mais doce ou azedinho). Quanto mais suco for colocado, mais firme o creme vai ficando; a quantidade de suco de limão determina a consistência de seu Ganache. Está pronto: é só usar.
Bolo Romeu e Julieta
Ingredientes
- 1 massa de bolo branca (a que você gostar de fazer, até mesmo a mistura para bolo pronta);
- 1/2 lata de leite condensado;
- 250g de goiabada cortada em cubinhos;
- 1 xícara de chá de coco ralado;
- 1/2 xícara de chá de queijo ralado;
- Papel manteiga para forrar a forma;
- papel alumínio para cobrir a forma;
- manteiga ou margarina para untar.
Modo de Preparo
Preaqueça o forno. Prepare a massa do bolo. Use uma forma redonda sem furo no meio para assar. Forre o fundo da forma com papel manteiga, unte e enfarinhe. Despeje a massa na forma. Distribua os pedacinhos da goiabada pelo meio da massa; regue com o leite condensado. Sobre o leite condensado polvilhe o queijo ralado e por último o coco ralado. Cubra a forma com papel alumínio e leve ao forno médio por aproximadamente 25 minutos. Retire o papel alumínio e deixe dourar o bolo.
Croquete de Carne
Ingredientes
- 1 colher de sopa de óleo;
- 3 colheres de sopa de extrato de tomate (dá para ser catchup picante também);
- 500g de carne moída;
- 2 sachês de caldo de carne;
- 1 xícara de chá de leite fervente;
- 10 colheres de sopa de farinha de trigo;
- cheiro verde a gosto (salsinha, cebolinha, coentro), bem picadinho;
- 1 ovo ligeiramente batido;
- farinha de rosca suficiente para empanar os croquetes;
- óleo para fritar.
Modo de Preparo
Aqueça o óleo e refogue o extrato de tomates. Acrescente a carne moída e refogue até secar o líquido. Dissolva o caldo de carne no leite fervente e coloque sobre a carne. Adicione a farinha de trigo de uma só vez, mexendo sempre, até formar uma massa firme e que solte da panela. Apague o fogo, acrescente o cheiro verde, misture bem até ficar bem incorporado a massa. Despeje a massa em uma superfície lisa. Aguarde esfriar. Vá modelando os croquetes, passe no ovo batido e na farinha de rosca. Frite em óleo bem quente. Escorra em papel toalha.
Dica: se desejar, substitua a carne (toda ou metade dela) por PTS (proteína texturizada de soja). Não esqueça, o PTS deve ser hidratado com um pouco de água morna, depois lavado e bem escorrido e aí é só usar na receita como se fosse a carne. Em torno de 2 xícaras de de chá de PTS, será o suficiente.
Pão de Aveia e Mel
Ingredientes
- 1 xícara de chá de aveia em flocos (finos ou médio);
- 100g de manteiga (a temperatura ambiente);
- 1/2 xícara de chá de mel;
- 1 colher de sopa de sal;
- 3 tabletes de fermento para pão (45g);
- 1 ovo;
- 5 xícaras de chá de farinha de trigo;
- 1 colher de sopa de sementes de linhaça;
- gergelim para polvilhar (optativo);
- 1 xícara de chá de água quente.
Modo de Preparo
Em uma vasilha coloque a água quente, a aveia, a manteiga, o mel e o sal. Misture bem e quando estiver morninho acrescente o fermento já dissolvido em meia xícara de chá de água morna. Siga adicionando os ovos, a farinha de trigo e a linhaça. Misture tudo muito bem. Coloque a massa em uma bacia untada, feche com filme plástico e deixe dobrar de volume. Quando dobrar de volume, sove um pouco a massa (a massa fica elástica e mole). Em uma superficie enfarinhada, modele os pães. Unte a assadeira, coloque os pães, cubra com um pano e deixe dobrar de volume novamente. Antes de colocar no forno polvilhe com sementes de gergelim. Asse em forno preaquecido, médio, por cerca de 40 minutos.
Se for fazer na máquina de pão:
- Use apenas 1 1/4 de xícara de chá de água;
- Se for usar feremento seco a medida é: 1 1/2 colher de sopa;
- Polvilhei o gergelim quando estava faltando 1 hora para finalizar o pão; Levantei a tampa da máquina e joguei o gergelim;
- Usei o ciclo normal para pães de 900g.
Suflê de Cenoura com espinafre
Ingredientes
- 4 cenouras raladas;
- 1/2 maço de espinafre picado (já fervido em água quente por 5 minutos);
- 1 cubinho de caldo de frango ou legumes;
- 1 cebola ralada (pequena);
- 1 colher de sopa de fermento;
- 2 colheres de sopa de farinha de trigo;
- 3 ovos;
- 1 copo de leite de verdade, não essa água pintada que vem em caixinha;
- Queijo ralado para polvilhar;
- azeite para refogar.
Modo de Preparo
Refogue a cebola, a cenoura e o espinafre. Adicione o caldo de frango e misture bem. Reserve. Bata no liquidificador os ovos, leite, farinha de trigo, até ficar homogêneo e por último acrescente o fermento. Unte uma forma e despeje metade da massa batida no liquidificador, acrescente o refogado e o restante da massa. Polvilhe com o queijo ralado e leve ao forno preaquecido por aproximadamente 25 minutos.
Tainha no forno
Ingredientes
- 1 tainha de aproximadamente 2kg (limpa e inteira);
- 1 sachê de caldo de legumes (em pó);
- 1 cebola pequena bem picadinha;
- cheiro verde bem picadinho;
- 2 dentes de alho amassadinhos;
- 1 colher de sopa de suco de limão;
- 1/2 pimentão vermelho bem picadinho;
- Azeite para untar.
Modo de Preparo
Com a tainha bem limpinha, esfregue o caldo por todo o peixe, por dentro e por fora. Reserve. Junte todos os temperos em uma vasilha e misture-os bem. Coloque essa mistura de temperos no interior da tainha. Unte uma assadeira com azeite e coloque a tainha. Leve ao forno médio por aproximadamente 50 minutos e está pronta.
Alfajor argentino
Ingredientes:
- 200g de manteiga sem sal;
- 1 xícara de chá de açúcar;
- 4 colheres de sopa de mel;
- 1 colher de chá de essência de baunilha;
- ½ colher de sopa de bicarbonato de sódio;
- 2 colheres de sopa de fermento;
- 5 xícaras de chá de farinha de trigo, peneirada;
- 2 gemas;
- 1 ovo inteiro;
- 400g de doce de leite, de consistência firme;
- 800g de chocolate meio amargo para a cobertura.
Modo de Preparo
-
Comece batendo a manteiga, açúcar, gemas, ovo, essência de baunilha e mel até ficar homogêneo. Vá acrescentando farinha de trigo, fermento e bicarbonato até formar uma massa homogênea.
-
Polvilhe farinha em uma superfície plana e lisa e abra a massa sobre essa superfície até obter meio centímetro de espessura.
-
Corte em formato circular de aproximadamente 2 cm de raio (por exemplo, a tampa do pote de fermento).
-
Asse em uma assadeira enfarinhada, mas não untada por aproximadamente 12 min., até ficar levemente dourado, em forno médio pré aquecido.
-
Espere esfriar e junte dois biscoitos recheando com doce de leite.
-
Derreta o chocolate em banho Maria (cuidado para não deixar pingar água no chocolate), e mergulhe os biscoitos recheados.
-
Coloque para esfriar sobre uma folha de papel manteiga.
Porção: Faz aproximadamente 50 alfajores.