
Sistemas Operacionais - Fundamentos, Evolução e Arquitetura

Desvendando o Invisível: Uma Introdução aos Sistemas Operacionais
Em cada computador, smartphone ou dispositivo inteligente que utilizamos diariamente, existe um software fundamental que orquestra silenciosamente todas as operações: o sistema operacional, que como um maestro dirige uma orquestra sinfônica, coordenando cada instrumento para criar uma harmonia perfeita, coordena os sistemas de hardware e software criando um ambiente computacional funcional e eficiente. Contudo, ao contrário do maestro, cuja presença é evidente, a natureza ubíqua dos sistemas operacionais torna-os quase invisíveis para a maioria dos usuários. Quando a cuidadosa leitora salva um arquivo, executa um programa ou conecta à internet, o faz sem se dar conta dos mecanismos complexos que tornam essas ações possíveis. Ainda assim, por trás dessa aparente simplicidade, reside uma das criações mais sofisticadas e interessantes da engenharia de software: um sistema capaz de gerenciar recursos limitados, coordenar atividades concorrentes, garantir segurança e fornecer uma interface amigável, simultânea e eficientemente.
Compreender os sistemas operacionais não é apenas uma questão de curiosidade acadêmica, mas uma necessidade fundamental para qualquer profissional que deseje trabalhar com tecnologia de forma competente. Maximize esta necessidade em tempos de crescente complexidade tecnológica, nos quais as novas ferramentas e tecnologias de inteligência artificial, computação em nuvem e dispositivos móveis estão integradas em nossas vidas diárias.
Os sistemas operacionais formam as pontes entre o hardware bruto e as aplicações que utilizamos, definindo como os recursos computacionais são utilizados e como as tarefas destes sistemas são executadas. Neste ponto, a atenta leitora deve ter percebido que este conhecimento é essencial para o desenvolvimento de softwares eficientes, a resolução de problemas de desempenho e a compreensão das limitações e possibilidades dos sistemas computacionais. Se a tecnologia avança, também avançam os sistemas operacionais.
Neste texto, iremos percorrer uma jornada por meio da evolução histórica dos sistemas operacionais, desde as primeiras máquinas programáveis até os sistemas modernos que gerenciam data centers inteiros. Exploraremos as funções fundamentais que todos os sistemas operacionais devem realizar, as diferentes perspectivas por meio das quais podemos compreendê-los, e os princípios arquiteturais que orientam seu design. Nossa meta é construir uma compreensão sólida que sirva como fundação para estudos mais avançados em ciência da computação e engenharia de software.
Escrevo com a esperança, e ambição, que este seja apenas o primeiro porto que visitaremos e que, ao final desta jornada, você não apenas compreenda os sistemas operacionais, mas que seja capaz de utilizar esse conhecimento para resolver problemas práticos, otimizar sistemas e contribuir para o avanço da tecnologia. Que o céu esteja azul e que os ventos sejam justos!
A Jornada por meio do Tempo: Evolução Histórica dos Sistemas Operacionais
A história dos sistemas operacionais foi impulsionada pela constante evolução do hardware, pelas crescentes demandas dos usuários e, principalmente pela criatividade aplicada a solução de novos problemas ou a busca de novos recursos. A linha do tempo apresentada na Figura 1 divide e ilustra as principais eras da evolução dos sistemas operacionais de forma simples e intuitiva.
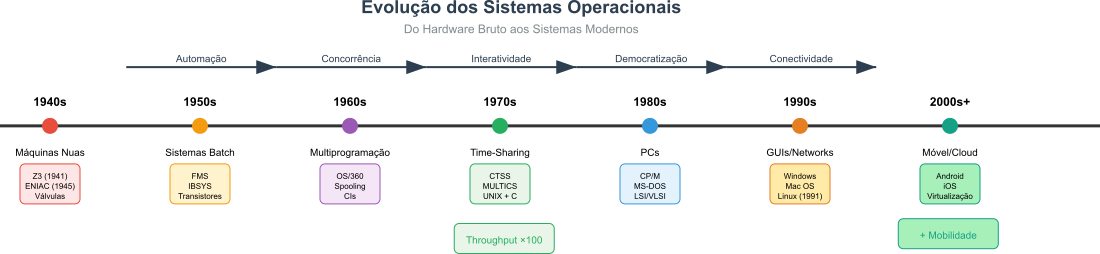 Figura 1: Linha de tempo da evolução dos sistemas operacionais
Figura 1: Linha de tempo da evolução dos sistemas operacionais
A evolução dos sistemas operacionais pode ser dividida em várias eras, cada uma marcada por inovações tecnológicas e mudanças nas necessidades dos usuários. A seguir, apresentamos um resumo das principais eras e marcos na evolução dos sistemas operacionais:
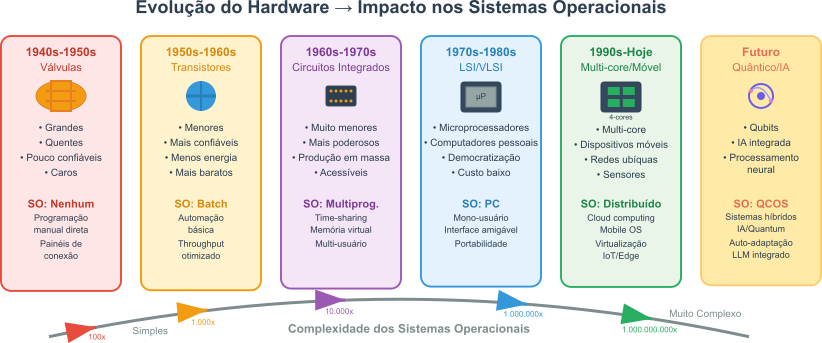 Figura 2: Evolução do Hardware → Impacto nos Sistemas Operacionais
Figura 2: Evolução do Hardware → Impacto nos Sistemas Operacionais
O tempo, e os momentos que o marcam, resumem os conceitos e avanços fundamentais mas não são suficientes. Talvez seja necessário um pouco mais de contexto para compreender como chegamos até aqui e antever até aonde podemos ir.
O Estágio Nascente: Máquinas Nuas e Programação Direta (1940s - início dos 1950s)
Os primórdios da computação, a era do bit lascado, foram caracterizados por máquinas colossais que utilizavam válvulas termiônicas e painéis de conexão (plugboards), operando sem qualquer forma de sistema operacional. Estas máquinas primitivas eram verdadeiras “máquinas nuas” (bare machines), nas quais os programadores interagiam diretamente com o hardware. Cada instrução era codificada manualmente em formato binário. Além disso, as funções que a máquina deveria executar eram controladas por meio da fiação física dos painéis de conexão. As máquina precisavam ser montadas, fisicamente configuradas, para cada tarefa específica. Muitos programadores eram especialistas em eletrônica, capazes de entender e manipular o hardware diretamente.
Como a atenta leitora deve estar imaginando, esse modo de operação era ineficiente, cansativo e tedioso. Os programadores precisavam se inscrever em listas para obter tempo de máquina, e a configuração era um processo demorado e propenso a erros. A introdução dos cartões perfurados representou uma melhoria na entrada de dados, mas a operação continuava predominantemente manual. Um computador desse período, que poderia levar dias ou até semanas para ser configurado e programado para uma tarefa específica, pode ser visto na Figura 2.
 Figura 3: O ENIAC, um dos primeiros computadores programáveis, com painéis de conexão e cartões perfurados. Artificialmente colorizada.( WIKIMEDIA COMMONS, 2025)
Figura 3: O ENIAC, um dos primeiros computadores programáveis, com painéis de conexão e cartões perfurados. Artificialmente colorizada.( WIKIMEDIA COMMONS, 2025)
ENIAC
O ENIAC (Electronic Numerical Integrator and Computer) é considerado um dos primeiro computador digital eletrônico de grande escala. Este equipamento foi desenvolvido durante a Segunda Guerra Mundial e concluído em 1945. Projetado por John Presper Eckert e John William Mauchly na Universidade da Pensilvânia, o ENIAC foi criado para calcular trajetórias balísticas para o Exército dos Estados Unidos. No entanto, sua utilidade transcendeu esse propósito inicial, marcando o início da era dos computadores eletrônicos. O ENIAC era uma máquina colossal, ocupando uma área de aproximadamente 167 metros quadrados e pesando cerca de 30 toneladas. Apesar de seu tamanho e complexidade, o ENIAC era capaz de realizar cálculos em uma velocidade sem precedentes para a época, revolucionando a forma como problemas complexos podiam ser resolvidos.
Tecnologia Inovadora para a Época
O ENIAC utilizava uma tecnologia revolucionária para a época, baseada em válvulas termiônicas (ou tubos de vácuo) em vez de componentes mecânicos. Com aproximadamente 17.468 válvulas, 7.200 diodos de cristal, 1.500 relés, 70.000 resistores e 10.000 capacitores, o ENIAC era uma maravilha da engenharia eletrônica. Esses componentes permitiam que o ENIAC realizasse cálculos a uma velocidade muito maior do que qualquer máquina anterior. A programação do ENIAC era feita por meio de painéis de conexão (no inglês: plugboards) e chaves manuais, um processo complexo e demorado que exigia conhecimento especializado. Apesar de suas limitações, como a falta de um sistema operacional moderno e a necessidade de reprogramação manual para cada nova tarefa, o ENIAC estabeleceu as bases para o desenvolvimento de computadores mais avançados e acessíveis, pavimentando o caminho para a revolução digital que viria a seguir.
O ENIAC, é um marco importante na história da computação. Mas, não foi o primeiro computador, nem o único. Outros computadores notáveis dessa era incluem o Colossus, usado para decifrar códigos durante a Segunda Guerra Mundial, e o EDVAC, que introduziu o conceito de armazenar programas na memória. E, graças aos problemas da segunda guerra mundial, ficou esquecido. Relegado a poeira do preconceito e medo.
O processo de redescoberta e reconhecimento da relevância do Z3 começou a ganhar força na década de 1990. Um marco importante ocorreu após a morte de Konrad Zuse, em 1995, quando houve um renovado interesse em seu trabalho, reacendendo debates sobre qual foi o primeiro computador da história. Além disso, em 1998, foi demonstrado que o Z3 era, em princípio, Turing-completo, ou seja, capaz de realizar qualquer cálculo que um computador moderno poderia fazer, desde que devidamente programado. Essa demonstração solidificou a posição do Z3 como um avanço fundamental na evolução da computação.
O Zuse Z3
O Zuse Z3, criado pelo engenheiro alemão Konrad Zuse em 1941, é reconhecido como o primeiro computador programável e totalmente automático do mundo. Desenvolvido em Berlim, o Z3 foi uma inovação significativa na computação, utilizando relés eletromecânicos para realizar cálculos complexos. Zuse construiu o Z3 para resolver problemas de engenharia, e a máquina foi usada para cálculos estruturais e aerodinâmicos. Embora o Z3 tenha sido destruído durante um bombardeio aliado em 1943, sua arquitetura e conceitos pioneiros influenciaram profundamente o desenvolvimento subsequente dos computadores. O Z3 era capaz de realizar operações de ponto flutuante mas possuía uma memória limitada. Ainda assim, suficiente para as tarefas da época. A máquina era programada por meio de fitas perfuradas, o que permitia uma certa flexibilidade na execução de diferentes tarefas.
Tecnologia e Legado do Zuse Z3
O Z3 utilizava cerca de 2.600 relés eletromecânicos para realizar suas operações lógicas e aritméticas, uma tecnologia avançada para a época, mas limitada em comparação com os computadores eletrônicos que surgiriam posteriormente. A máquina operava com uma frequência de clock de aproximadamente 5 Hz, o que, embora lento pelos padrões atuais, era uma conquista notável para a tecnologia da época. O Z3 também introduziu conceitos fundamentais de computação, como a separação entre programa e dados, e a capacidade de executar operações condicionais. Apesar de suas limitações, o Z3 demonstrou a viabilidade de computadores programáveis e automáticos, abrindo caminho para desenvolvimentos futuros. O trabalho de Konrad Zuse é considerado pioneiro e visionário, e seu legado continua a ser celebrado na história da computação.
Observe, atenta leitora, que o Eniac usava válvulas termiônicas, enquanto o Z3 utilizava relés eletromecânicos. Isto parece implicar que o ENIAC era muito mais rápido. Contudo, o Z3 era programado por fitas perfuradas, enquanto o ENIAC utilizava painéis de conexão. O que significa que o Z3 era mais flexível e fácil de programar. Ou seja, este pobre autor acredita que o tempo entre a definição do problema e a solução do mesmo era menor no Z3 do que no ENIAC. O que, em última análise, é o que importa.
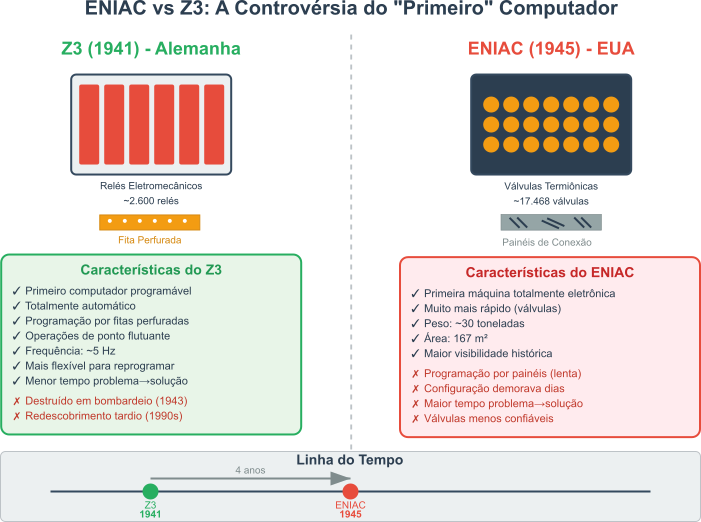 Figura 4: Comparação entre o ENIAC e o Z3, destacando as diferenças em tecnologia, programação e velocidade.
Figura 4: Comparação entre o ENIAC e o Z3, destacando as diferenças em tecnologia, programação e velocidade.
Para vértices, nesta jornada, o mais importante é compreender que, mesmo sem sistemas operacionais, os computadores já eram capazes de realizar tarefas complexas. No entanto, a falta de abstração e automação tornava o processo trabalhoso, dolorosamente tedioso e propenso a erros. Nesse ponto da história começa a surgir a necessidade de camada extra de tecnologia que permitisse automatizar as tarefas necessárias para resolver problemas computacionais, sem a necessidade de intervenção manual constante.
A Revolução Batch: Automatizando o Throughput (final dos 1950s - meados dos 1960s)
Throughput é uma palavra horrível A palavra “throughput” da língua inglesa, não tem uma tradução direta para o português. Pode ser entendida como vazão, taxa de transferência ou capacidade de processamento. No contexto de sistemas operacionais, refere-se à quantidade de trabalho que um sistema pode realizar em um determinado período de tempo. É uma métrica importante para avaliar a eficiência e o desempenho de um sistema, especialmente em ambientes de computação nos quais múltiplas tarefas são executadas simultaneamente.
Eu vou usar throughput, na esperança que Cecília Meireles e Fernando Pessoa me perdoem o estrangeirismo.
Conceito Fundamental: Throughput vs Latência
Throughput é frequentemente confundido com velocidade, mas representa algo mais sutil:
Analogia da Fábrica:
- Throughput: Quantos carros a fábrica produz por dia
- Latência: Quanto tempo leva para um carro específico ser completado
No Contexto dos Sistemas Batch:
Antes (Operação Manual): Job 1: ████████ (8h total, 2h CPU) Job 2: ████████ (8h total, 2h CPU) Throughput: 2 jobs/16h = 0.125 jobs/hora Depois (Sistema Batch): Job 1: ██ (2h CPU) Job 2: ██ (2h CPU) Job 3: ██ (2h CPU) Throughput: 3 jobs/6h = 0.5 jobs/horaResultado: 4x mais throughput com o mesmo hardware!
A substituição das válvulas por transistores tornou os computadores menores, mais confiáveis, rápidos e práticos. Contudo, e apesar disso, as máquinas da época eram extremamente caras e gerenciados centralmente. Estas grandes máquinas centralizadas ficaram conhecidas como mainframes. Elas eram operadas por equipes de especialistas e utilizadas principalmente para tarefas críticas em grandes organizações, como bancos e universidades. E enfrentavam um problema significativo: a subutilização da unidade central de processamento. A unidade central de processamento, que ficou conhecida como CPU, ficava ociosa enquanto esperava por operações de Entrada/Saída (E/S) ou pela conclusão de outros processos, resultando em desperdício de recursos.
A solução emergiu na forma de Sistemas Batch.
Os sistemas batch, uma palavra do inglês que pode ser traduzida por lote, apresentavam características distintas que os diferenciavam das abordagens anteriores de computação. Uma das principais inovações era a capacidade de agrupar tarefas com necessidades similares, formando lotes, ou batchs, que eram executados de maneira sequencial, permitindo uma utilização mais eficiente dos recursos computacionais. Esses sistemas contavam com um monitor residente, um componente precursor dos sistemas operacionais modernos, que tinha a função de automatizar o sequenciamento dos trabalhos, eliminando a necessidade de intervenção manual entre a execução de cada tarefa. Para controlar esse processo, foi desenvolvida a Job Control Language (JCL), uma linguagem específica que permitia instruir o monitor sobre como processar os trabalhos (do inglês, jobs), definindo parâmetros e sequências de execução. Além disso, os sistemas batch introduziram o conceito de processamento offline, no qual a saída dos trabalhos era direcionada para fitas magnéticas, permitindo que a impressão dos resultados fosse realizada posteriormente, sem ocupar o valioso tempo de processamento da unidade central de processamento. Essa abordagem representou um avanço significativo na automação da operação dos computadores, aumentando consideravelmente a utilização da CPU e o throughput dos sistemas.
Sistemas influentes desta era:
-
FMS (Fortran Monitor System): um dos primeiros sistemas de monitoramento para programas FORTRAN. O FMS foi um dos primeiros sistemas de monitoramento desenvolvido especificamente para programas escritos em FORTRAN (do inglês: FORmula TRANslation), uma das primeiras linguagens de programação, utilizada para aplicações científicas e de engenharia de alto desempenho ainda hoje. O FMS permitia que múltiplos programas FORTRAN fossem executados em sequência sem a necessidade de intervenção manual entre cada execução. O FMS introduziu os conceitos básicos de gerenciamento de tarefas e alocação de recursos, que se tornariam fundamentais para os sistemas operacionais. Além disso, o FMS facilitava a compilação e execução de programas FORTRAN, tornando o processo de desenvolvimento mais eficiente e menos propenso a erros.
-
IBSYS: sistema batch para o IBM 7094, que estabeleceu alguns conceitos importantes até hoje. O IBSYS introduziu técnicas sofisticadas de gerenciamento de memória e escalonamento de tarefas, permitindo que múltiplos trabalhos fossem processados de maneira mais eficiente. O IBSYS também implementou mecanismos de proteção de memória, garantindo que um programa não interferisse na execução de outros, um conceito importante para a estabilidade e confiabilidade dos sistemas computacionais. Além disso, o IBSYS oferecia suporte a dispositivos de entrada e saída diversos, incluindo leitores de cartões, impressoras e unidades de fita magnética, permitindo uma maior flexibilidade na manipulação de dados.
O objetivo principal dos sistemas Batch era maximizar a utilização da CPU e o throughput. Deve voltar a definição de throughput, só por via das dúvidas. A atenta leitora deve registrar que esta era marcou o primeiro passo na automação da operação do computador e impulsionou o conceito de abstração da máquina.
Malabarismo de Recursos: O Advento da Multiprocessamento (meados dos 1960s - 1970s)
A introdução dos Circuitos Integrados (CIs) marcou um avanço significativo, resultando em computadores ainda mais poderosos, compactos e acessíveis. No entanto, mesmo com a eficiência aprimorada dos sistemas batch, um problema persistia: a CPU permanecia ociosa durante as operações de entrada e saída de dados (E/S). O gargalo residia no fato de que as operações de E/S são ordens de magnitude mais lentas do que a execução de instruções pela CPU.
Nesse contexto surgiu a Multiprocessamento. Essa técnica revolucionária propunha manter múltiplos processos na memória principal simultaneamente. A ideia era simples, mas transformadora: se um processo em execução precisasse realizar uma operação de E/S, um sistema de gestão poderia rapidamente comutar a CPU para outro processo que estivesse pronto para executar, em vez de esperar o término da lenta operação de E/S. Essa abordagem aumentou drasticamente a utilização da CPU, reduziu o tempo ocioso e revolucionou a forma como os recursos computacionais são gerenciados.
A eficácia da Multiprocessamento pode ser modelada matematicamente. Se um processo gasta uma fração $p$ do seu tempo esperando por operações de E/S, a probabilidade de $n$ processos, todos residentes na memória, estarem simultaneamente esperando por E/S é $ p^n $. A CPU só estará ociosa se todos os processos estiverem esperando. Portanto, a utilização da CPU é a probabilidade de que pelo menos um processo não esteja esperando por E/S, o que pode ser expresso pela fórmula:
\[\text{Utilização da CPU} = 1 - p^n\]Nesta equação:
- $p$ representa a fração de tempo que um processo gasta em operações de E/S.
- $n$ é o número total de processos mantidos na memória.
Demonstração Prática: O Poder da Multiprocessamento
A fórmula $\text{Utilização da CPU} = 1 - p^n$ pode parecer abstrata, mas seus resultados são impressionantes:
Cenário: Processos gastam 50% do tempo em I/O ($p = 0.5$)
Processos (n) $p^n$ Utilização da CPU Melhoria 1 0.5 50% - 2 0.25 75% +50% 4 0.0625 93.75% +87.5% 8 0.0039 99.61% +99.2% Observação Importante: com apenas 4 processos na memória, obtemos quase 94% de utilização da CPU, mesmo quando cada processo passa metade do tempo esperando I/O!
Limitação Prática: Esta análise assume que sempre há pelo menos um processo pronto para executar e não considera o custo computacional da troca de contexto.
Como a esperta leitora deve observar que, mesmo com um valor de $p$ relativamente alto (por exemplo, 0.5, significando que os processos passam metade do tempo em E/S), aumentar o número de processos $n$ na memória faz com que o termo $p^n$ diminua exponencialmente, levando a utilização da CPU para perto de 100%.
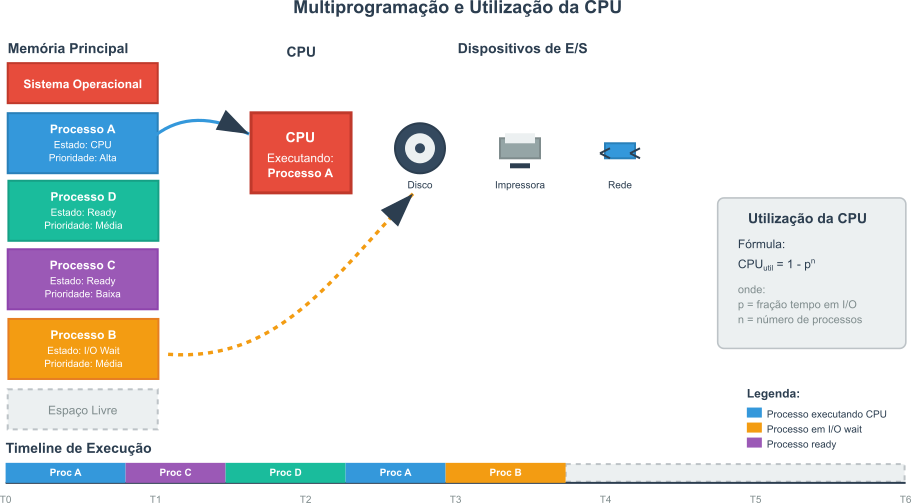 Figura 5: Representação da alocação de processos em memória.
Figura 5: Representação da alocação de processos em memória.
Em resumo, a Multiprocessamento introduziu conceitos fundamentais que moldaram a construção dos sistemas operacionais. Entre eles, destacam-se:
- Múltiplos jobs na memória: permitia que vários trabalhos fossem mantidos simultaneamente na memória principal;
- Comutação de contexto: quando um job necessitava realizar operações de E/S, o sistema de gestão rapidamente transferia a CPU para outro job pronto para execução;
- Gerenciamento de memória: surgia a necessidade de alocar espaço para múltiplos trabalhos de forma eficiente;
- Escalonamento de CPU: eram desenvolvidos algoritmos para decidir qual job seria executado em seguida, otimizando o uso da CPU.
jobs: o termo “job” refere-se a uma tarefa ou trabalho que um sistema operacional deve executar. Em sistemas batch, um job é um conjunto de instruções e dados que são processados em sequência, sem interação do usuário durante a execução. Os jobs são frequentemente agrupados com base em suas características ou requisitos de recursos, permitindo que o sistema operacional otimize o uso da CPU e minimize o tempo de espera. O equivalente atual do job é o processo, que é uma instância de um programa em execução, incluindo seu estado, dados e recursos alocados.
Outro avanço significativo foi o Spooling (Simultaneous Peripheral Operation On-Line), uma técnica que utilizava o disco como buffer intermediário para operações de E/S. Isso permitia que a CPU e os dispositivos de E/S operassem de forma mais concorrente, melhorando a eficiência geral do sistema. Um exemplo marcante dessa era é o OS/360 da IBM, em 7 de abril de 1964, um sistema de Multiprocessamento que estabeleceu muitos dos conceitos ainda utilizados nos sistemas operacionais modernos. O termo OS/360 refere-se a uma família de sistemas operacionais desenvolvidos pela IBM para sua linha de mainframes System/360, que introduziu a Multiprocessamento como um recurso central. O OS/360 foi projetado para suportar uma ampla gama de aplicações, desde processamento de dados até computação científica, e estabeleceu padrões que influenciaram profundamente o desenvolvimento de sistemas operacionais subsequentes.
Spooling vem do inglês Simultaneous Peripheral Operations On-Line e refere-se ao processo de gerenciamento de dados para operações de entrada e saída (E/S). Ele permite que dispositivos periféricos, como impressoras, operem de forma eficiente, armazenando temporariamente os dados em uma área de buffer, uma área de memória temporária ou fila, sem interromper o processamento principal da CPU.
buffer é um destes termos em inglês que chegaram na computação, em inglês, de uma forma pouco ortodoxa. Talvez, algum pesquisador tenha se lembrado de algo da infância, ou de alguma outra área do vida e trouxe para a computação. O termo “buffer” deriva do verbo em inglês antigo “buff”, que significava golpear ou amortecer um golpe. Esse sentido inicial estava ligado à ideia de suavizar ou absorver um impacto físico, como uma pancada. Na física, um “buffer” é um dispositivo ou mecanismo que reduz o impacto ou choque, como os amortecedores usados em trens ou carros para suavizar colisões. Também pode se referir a algo ou alguém que funciona como uma barreira protetora. Em computação Um “buffer” é uma área de armazenamento temporário para dados, usada enquanto eles estão sendo transferidos entre dois lugares, ou processos, distintos. Por exemplo, um buffer pode guardar informações de um dispositivo rápido, como um processador, antes de enviá-las para um dispositivo mais lento, como uma impressora, ajudando a equilibrar diferenças de velocidade1.
Novamente: o poetas mortos da língua portuguesa perdoai este pobre autor pelos crimes que comete!
A IBM não criou o termo sistema operacional, mas foi fundamental em sua popularização. O termo já existia na comunidade de computação antes do lançamento do OS/360 pela IBM em 1964. Por exemplo, sistemas como o GM-NAA I/O, desenvolvido em 1956, e o CTSS, descrito em 1962, já eram chamados de sistemas operacionais em contextos acadêmicos e de pesquisa. No entanto, o OS/360, marcou um ponto de virada na história da computação. Deste ponto em diante, podemos usar o termo sistema operacional para nos referirmos a um software que gerencia recursos de hardware e fornece serviços essenciais para programas de aplicação. A Multiprocessamento e o spooling foram marcos importantes na evolução dos sistemas operacionais, estabelecendo as bases para a abstração de hardware e a automação do gerenciamento de recursos.
Era da Interatividade: Sistemas de Tempo Compartilhado (final dos 1960s - 1980s)
Os sistemas de tempo compartilhado, do inglês time-sharing, representaram uma evolução natural da Multiprocessamento, com um foco especial na experiência do usuário além eficiência no uso da CPU. Esses sistemas revolucionaram a computação ao dividir o tempo da CPU entre múltiplos usuários interativos simultaneamente, criando um ambiente no qual cada usuário tinha a impressão de estar utilizando um computador dedicado exclusivamente a ele.
A abordagem de time-sharing marcou uma mudança significativa de paradigma nos sistemas computacionais. Essa transição foi possível graças à implementação do time slicing. Nome em inglês para uma técnica na qual cada processo recebe uma pequena fatia de tempo da CPU, que podemos chamar de quantum para aproveitar os tempos atuais e o conceito da física, antes de ser temporariamente suspenso para permitir que outros processos sejam executados. Essa abordagem cria a ilusão de que cada usuário tem acesso exclusivo aos recursos do computador, melhorando significativamente a interatividade e a experiência geral do usuário.
O uso dos conceitos de time slicing, inglês para fatiamento de tempo, permitiram que múltiplos usuários trabalhassem simultaneamente no mesmo sistema, cada um com a impressão de estar utilizando um computador dedicado, enquanto na realidade os recursos eram compartilhados de maneira eficiente e transparente.
Sistemas Influentes:
Entre os sistemas de tempo compartilhado mais influentes da história da computação, destacam-se três que deixaram um legado significativo.
-
CTSS (Compatible Time-Sharing System): desenvolvido no Massachusetts Institute of Technology (MIT). Este sistema foi pioneiro no uso de fatiamento de tempo com interrupções, uma técnica que permitia a múltiplos usuários compartilharem os recursos de um computador de maneira eficiente. O CTSS estabeleceu muitos dos conceitos fundamentais que ainda hoje são a base dos sistemas interativos modernos, incluindo mecanismos de alocação de recursos e gerenciamento de processos que garantiam uma experiência de usuário mais responsiva e interativa.
-
MULTICS (Multiplexed Information and Computing Service): resultado de um projeto colaborativo entre o MIT, a General Electric e os Bell Labs. O MULTICS introduziu uma série de conceitos revolucionários que mudaram para sempre a computação. Entre essas inovações estavam a memória de nível único, que simplificava o gerenciamento de memória, a ligação dinâmica de código, que permitia maior flexibilidade na execução de programas, e um sistema de arquivos hierárquico, que organizava os dados de maneira mais intuitiva. Além disso, o MULTICS tinha um forte foco em segurança, introduzindo mecanismos avançados de proteção de dados e controle de acesso. Embora o MULTICS tenha tido um sucesso comercial limitado, sua influência no desenvolvimento de sistemas operacionais subsequentes foi imensa, estabelecendo padrões que ainda são seguidos hoje.
-
UNIX, desenvolvido nos Bell Labs por Ken Thompson e Dennis Ritchie, merece destaque especial. Inspirado pelo MULTICS, o UNIX foi criado com uma filosofia de simplicidade e elegância que o tornou extremamente popular. Diferente de seu predecessor, o UNIX foi escrito predominantemente na Linguagem C, o que lhe conferiu uma portabilidade notável, permitindo que fosse executado em uma variedade de plataformas de hardware. O UNIX também se destacou por seu ambiente multiusuário e multitarefa, que permitia que múltiplos usuários trabalhassem simultaneamente no mesmo sistema, cada um executando várias tarefas ao mesmo tempo. Os sistemas UNIX de 1993 apresentavam pilhas TCP/IP maduras (sockets BSD desde 1983), memória virtual sofisticada com paginação por demanda (4.3BSD), sistemas de arquivos avançados e capacidades de computação distribuída por meio de NFS e RPC.Além disso, o UNIX introduziu um sistema de arquivos hierárquico e um shell de comando poderoso, que oferecia aos usuários uma interface flexível e eficiente para interagir com o sistema.
O nome “UNIX” é uma brincadeira derivada de “Multics”, um sistema operacional anterior no qual seus criadores trabalharam. O Multics era um projeto ambicioso, mas complexo e pesado. Quando Ken Thompson e Dennis Ritchie começaram a desenvolver um sistema mais simples e eficiente, chamaram-no de UNIX como um trocadilho, sugerindo algo mais unitário e simplificado em contraste com o Multics. O nome também pode ser interpretado como uma abreviação de “UNIpleXed Information and Computing Service”, embora isso seja mais uma explicação retroativa do que a intenção original.
A Linguagem C foi criada por Dennis Ritchie na Bell Labs entre 1972 e 1973, sendo desenvolvida especificamente para facilitar o desenvolvimento do sistema operacional UNIX. Dennis Ritchie descreveu o C como “uma linguagem de implementação de sistema para o nascente sistema operacional UNIX”. Cronologicamente temos:
**UNIX inicial (1969-1971): **UNIX foi originalmente escrito em assembly language para o computador PDP-7
Desenvolvimento da linguagem B: Ken Thompson primeiro criou a linguagem B, uma versão simplificada do BCPL, para desenvolver utilitários para o UNIX
Evolução para **C (1971-1973)**: Em 1971, Ritchie começou a melhorar a linguagem B para aproveitar recursos do PDP-11 mais poderoso, adicionando tipos de dados como caracteres. Esta versão foi chamada “New B” (NB) e posteriormente evoluiu para C
Reescrita do **UNIX em C (1973): Na versão 4 do **UNIX, lançada em novembro de 1973, o kernel do UNIX foi extensivamente reimplementado em C
A Linguagem C foi projetada para ser uma linguagem de programação de sistemas, com foco em eficiência, portabilidade e expressividade. Ela permitiu que o UNIX fosse reescrito de forma mais concisa e legível, facilitando a manutenção e evolução do sistema. Conforme mais do sistema operacional foi reescrito em C, a portabilidade também aumentou, permitindo que o UNIX rodasse em diferentes arquiteturas de computador. Além disso, a Linguagem C tinha o objetivo de mover o código do kernel UNIX do assembly para uma linguagem de alto nível, que realizaria as mesmas tarefas com menos linhas de código. Finalmente, Dennis Ritchie construiu a Linguagem C sobre a linguagem B, herdando a sintaxe concisa de Thompson que tinha uma poderosa mistura de funcionalidades de alto nível com os recursos detalhados necessários para programar um sistema operacional que fosse portável entre diferentes plataformas de hardware.
O desenvolvimento do UNIX ilustra um princípio importante no design de sistemas: soluções pragmáticas e focadas muitas vezes ganham maior adoção do que aquelas excessivamente ambiciosas e complexas. A portabilidade do UNIX, facilitada pela Linguagem C, foi um divisor de águas, permitindo sua disseminação por uma vasta gama de plataformas de hardware.
Kernel vs Sistema Operacional
Chamamos de kernel o componente central e mais crítico do sistema operacional. Esta será a primeira parte do sistema operacional que será carregada na memória durante o boot. O Kernel contém as funções necessárias para atuar como uma ponte direta entre hardware e software. O Kernel opera no nível mais baixo do sistema, gerenciando recursos fundamentais como processos, decidindo qual programa usa a CPU e por quanto tempo, memória RAM, controlando alocação e proteção entre programas, dispositivos de hardware, por meio de drivers, e fornecendo interfaces para que aplicações solicitem serviços do sistema. O kernel é essencialmente invisível ao usuário comum, operando em modo privilegiado para garantir estabilidade e segurança do sistema.
O sistema operacional, por sua vez, é o conjunto completo de software que inclui o kernel mais todos os componentes que tornam o computador utilizável para o usuário final. Além do kernel, um Sistema Operacional engloba interfaces de usuário, ambientee para interpretação de comandos (shell), sistema de arquivos para organização de dados, utilitários de sistema como gerenciadores de arquivos e painéis de controle, e bibliotecas de sistema que fornecem APIs para desenvolvimento de aplicações. Estes componentes trabalham em conjunto para criar uma experiência coesa e funcional.
Pessoas mais inteligentes que eu, dizem que a tecnologia, e a civilização, avançam em rampas e degraus. De tempos em tempos, uma inovação ou descoberta significativa ocorre, criando um salto qualitativo na capacidade tecnológica. O par UNIX e C é, claramente, um destes degraus.
A Democratização da Computação: Era dos Computadores Pessoais (final dos 1970s - presente)
A invenção e popularização dos microprocessadores, impulsionadas pelos avanços em LSI (Large Scale Integration) integração em larga escala em inglês e em VLSI (Very Large Scale Integration), integração em escala muito grande em inglês, levaram ao surgimento de computadores pessoais acessíveis. A curiosa leitora precisa saber que no final dos anos 1980, no Brasil, era mais fácil comprar um computador pessoal importado, que um telefone.
As novas tecnologias de microprocessadores permitiram a miniaturização e a redução de custos, tornando possível a criação de computadores que poderiam ser adquiridos por indivíduos e pequenas empresas. Esses computadores pessoais, ou PCs, eram significativamente mais baratos do que os mainframes e minicomputadores da época, tornando a computação acessível a um público muito mais amplo.
Esta era representou uma mudança drástica do modelo de computação centralizada para sistemas de usuário individual.
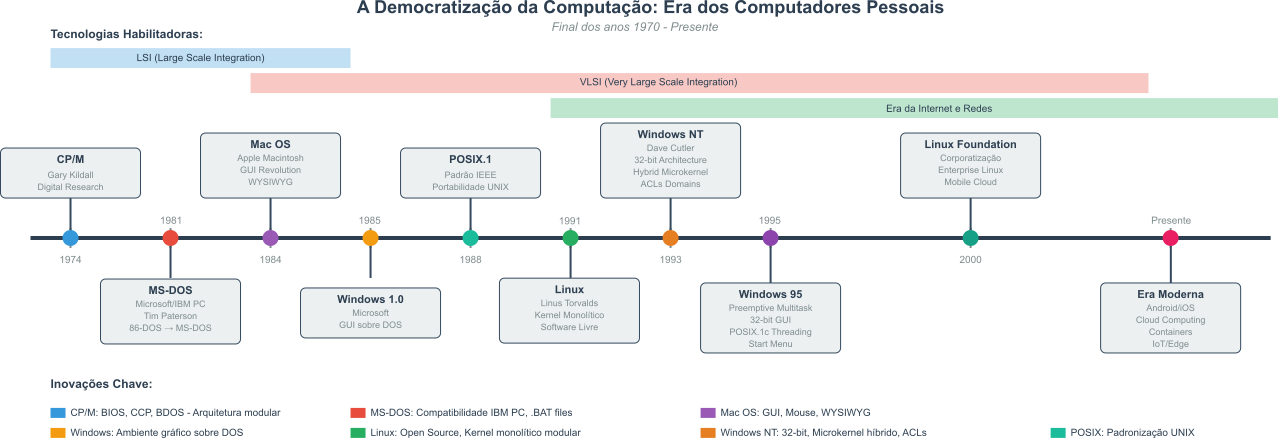 Figura 6: Linha do tempo da evolução dos sistemas operacionais para computadores pessoais.
Figura 6: Linha do tempo da evolução dos sistemas operacionais para computadores pessoais.
Sistemas Influentes:
- CP/M (Control Program for Microcomputers) - Desenvolvido por Gary Kildall na Digital Research em 1974, o CP/M foi um marco fundamental na evolução dos sistemas operacionais para microcomputadores. Este sistema estabeleceu convenções duradouras para a organização de arquivos e comandos que influenciariam profundamente o desenvolvimento posterior de sistemas como o MS-DOS. O CP/M introduziu o conceito de Basic Input/Output System (BIOS), uma camada de abstração entre o hardware e o sistema operacional que permitia maior portabilidade entre diferentes microcomputadores baseados no processador Intel 8080 e Zilog Z80. Sua estrutura modular, com Command Console Processor (CCP), Basic Disk Operating System (BDOS) e BIOS, tornou-se um modelo arquitetônico para sistemas posteriores. Durante o final dos anos 1970 e início dos 1980, o CP/M dominou o mercado de microcomputadores comerciais, estabelecendo padrões para nomenclatura de drives (A:, B:, C:) e comandos básicos que persistem até hoje2.
- MS-DOS (Microsoft Disk Operating System) - Originado como uma adaptação do 86-DOS (QDOS - Quick and Dirty Operating System) desenvolvido por Tim Paterson na Seattle Computer Products, o MS-DOS foi adquirido pela Microsoft em 1981 para atender à demanda da IBM por um sistema operacional para seu novo Personal Computer. O sistema mantinha compatibilidade conceitual com o CP/M, facilitando a migração de aplicações, mas foi otimizado para o processador Intel 8086/8088. Sua interface de linha de comando, embora aparentemente simples, oferecia recursos poderosos como redirecionamento de entrada/saída, processamento em lote por meio de arquivos .BAT, e suporte a dispositivos por meio de drivers carregáveis. O MS-DOS evoluiu significativamente ao longo de suas versões, introduzindo suporte a discos rígidos (versão 2.0), estruturas de diretórios hierárquicas, e eventualmente suporte limitado à memória estendida. Sua natureza monotarefa e arquitetura de 16 bits, embora limitantes, proporcionaram estabilidade e previsibilidade que contribuíram para o estabelecimento do padrão IBM PC como plataforma dominante na computação pessoal por mais de uma década3.
-
Apple Macintosh OS (Classic Mac OS) - Lançado em 1984, o Sistema Operacional do Macintosh representou uma revolução paradigmática na interação humano-computador, popularizando conceitos que hoje consideramos fundamentais na computação moderna. Inspirado no trabalho pioneiro realizado nos Laboratórios Xerox Alto e Star, o Mac OS implementou de forma comercialmente viável a metáfora da área de trabalho. Nesta metáfora arquivos eram representados como documentos físicos e pastas como contêineres organizacionais. O sistema aproveitou as ideias dos Laboratórios da Xerox e introduziu o mouse como dispositivo primário de navegação, implementou o conceito de WYSIWYG, abreviatura do What You See Is What You Get, na edição de documentos, e estabeleceu padrões de interface como menus suspensos, caixas de diálogo modais, e manipulação direta de objetos gráficos. Tecnicamente, o Mac OS original baseava-se em um núcleo de processamento cooperativo que, embora não oferecesse proteção robusta de memória ou multitarefa preemptiva, proporcionava uma experiência de usuário fluida e intuitiva. Sua arquitetura de recursos, no inglês: resource fork, permitia a incorporação de elementos gráficos, sonoros e de interface diretamente nos arquivos executáveis, facilitando a localização e personalização de aplicações.
-
Microsoft Windows - Iniciado em 1985 como um ambiente gráfico executado sobre o MS-DOS, o Windows passou por três fases distintas de desenvolvimento. As versões 1.0 a 3.1 funcionavam essencialmente como ambientes gráficos, oferecendo uma interface visual para o MS-DOS subjacente, mas mantendo as limitações fundamentais de um sistema de 16 bits. O Windows 95 marcou um ponto de inflexão na evolução dos sistemas operacionais, introduzindo multitarefa preemptiva de 32 bits, um sistema de arquivos mais robusto, e uma interface redesenhada que incorporava elementos como a barra de tarefas e o menu Iniciar. Paralelamente, a linha Windows NT, iniciada em 1993 sob a liderança de Dave Cutler, representou uma abordagem completamente nova: um sistema operacional construído desde o foundation com arquitetura de 32 bits, microkernel híbrido, e recursos avançados de segurança baseados em Access Control Lists (ACLs) e domínios. O NT introduziu conceitos importados do padrão POSIX, como threading avançado, proteção de memória robusta, e suporte nativo a redes, estabelecendo as bases arquitetônicas que persistem nas versões modernas do Windows.
O Windows NT e o Padrão POSIX O Windows NT representou uma adaptação sofisticada de princípios estabelecidos da ciência da computação que já estavam padronizados ou implementados em sistemas UNIX. O POSIX.1 foi ratificado em 1988 precisamente quando Dave Cutler iniciou o desenvolvimento do NT na Microsoft, criando uma convergência histórica única. O POSIX.1b-1993, publicado apenas meses antes do lançamento do NT em julho de 1993, já havia padronizado extensões avançadas de tempo real incluindo escalonamento de prioridade, travamento de memória, objetos de memória compartilhada, filas de mensagens e temporizadores de alta resolução - capacidades que o subsistema POSIX mínimo do NT ignorou completamente.
Em 1993, os padrões POSIX definiam capacidades sofisticadas de multiprocessamento com escalonamento de prioridade de 32 níveis, arquivos mapeados em memória, semáforos e sinais de tempo real. O Windows NT implementou apenas a revisão básica POSIX.1-1990 para conformidade com contratos governamentais.
A o uso de threading é particularmente reveladora da influência do POSIX: enquanto o NT foi lançado com threading nativo em 1993, o Mach havia introduzido threads em sistemas semelhantes ao UNIX em 1985, oito anos antes. Os padrões de threading POSIX estavam em desenvolvimento durante a criação do NT e foram publicados como POSIX.1c em 1995.
O POSIX.1b-1993 especificou interfaces de travamento de memória, arquivos mapeados em memória, escalonamento preemptivo de prioridade fixa com mínimo de 32 níveis de prioridade, semáforos nomeados e não-nomeados, filas de mensagens e temporizadores de precisão de nanossegundos** - tudo antes do lançamento do NT.
A implementação POSIX real do NT foi deliberadamente mínima - suportando apenas chamadas de sistema básicas sem utilitários de shell, interfaces de threading ou extensões de tempo real. O subsistema POSIX da Microsoft era uma caixa de seleção para conformidade, não um esforço sério de compatibilidade UNIX.
As inovações genuínas do NT foram integração arquitetônica ao invés de avanços fundamentais. O design de microkernel híbrido suportando múltiplas personalidades de Sistema Operacional (Win32, POSIX, OS/2) simultaneamente foi arquitetonicamente inovador. A implementação abrangente da Camada de Abstração de Hardware excedeu as abordagens de portabilidade contemporâneas. A arquitetura de segurança integrada com controle de acesso baseado em capacidades representou um avanço genuíno sobre o modelo mais simples usuário/grupo/outros do UNIX.
A vantagem arquitetônica do NT residia em seu design unificado para multiprocessamento desde o início, enquanto os sistemas UNIX estavam gradualmente adaptando suporte SMP. O escalonador centrado em threads do NT e a preempção integrada do kernel representaram engenharia superior de conceitos estabelecidos ao invés de inovação.
No entanto, o UNIX mantinha vantagens significativas: os sockets BSD tiveram uma década de refinamento até 1993, fornecendo interfaces de programação de rede maduras e comprovadas. Os sistemas UNIX ofereciam ambientes de desenvolvimento sofisticados, estabilidade comprovada por meio de implantação em produção e serviços de rede abrangentes como NFS e frameworks de computação distribuída.
A comunidade técnica avaliou o NT como “VMS para hardware de PC” - uma caracterização precisa dado que Cutler transferiu diretamente conceitos de sua experiência com VMS. Alegações persistem de que o NT incorporou código do sistema operacional PRISM cancelado da DEC, apoiando ainda mais a narrativa de adaptação ao invés de inovação.
-
Linux - Concebido em 1991 por Linus Torvalds como um hobby pessoal para criar um sistema semelhante ao MINIX para computadores 386, o Linux evoluiu para se tornar um dos projetos de software livre mais bem-sucedidos da história. Sua arquitetura monolítica modular permite a incorporação dinâmica de funcionalidades por meio de módulos carregáveis, oferecendo flexibilidade sem comprometer performance. O desenvolvimento do Linux seguiu um modelo colaborativo distribuído sem precedentes, conhecido como “bazar” segundo Eric Raymond. Nesse modelo milhares de desenvolvedores contribuem simultaneamente para diferentes aspectos do sistema. Tecnicamente, o Linux implementa recursos avançados como gerenciamento de memória virtual, multiprocessamento simétrico (SMP), agendamento de tarefas em tempo real, e suporte extensivo a sistemas de arquivos diversos (ext4, Btrfs, ZFS). Sua natureza de código aberto, e a linguagem C, permitiram adaptações para uma variedade extraordinária de plataformas, desde supercomputadores até dispositivos embarcados, smartphones (Android), e sistemas de tempo real.
A Linux Foundation, criada em 2000, desempenhou um papel fundamental na promoção e suporte ao desenvolvimento do Linux, garantindo sua sustentabilidade e evolução contínua. O Linux não é apenas um sistema operacional; é uma plataforma que impulsiona a inovação em diversas áreas, desde servidores web até dispositivos móveis, e continua a ser um pilar fundamental da infraestrutura de TI moderna. Porém, do ponto de vista do desenvolvimento de sistemas operacionais dizemos que o Linux é o Kernel, ou núcleo, de um sistema operacional. Neste caso, um Kernel monolítico.
 Figura 7: Lista dos Maiores Doadores da Linux Foundation.
Figura 7: Lista dos Maiores Doadores da Linux Foundation.
A era do PC inicialmente levou a uma simplificação de alguns recursos do Sistema Operacional em comparação com os Sistemas Operacionais de mainframe, mas gradualmente reintroduziu sofisticação conforme o hardware se tornava mais poderoso.
Fronteiras Modernas
As últimas décadas foram marcadas por uma proliferação sem precedentes de novas plataformas e paradigmas computacionais. Esta evolução transformou não apenas a forma como os seres humanos interagem com a tecnologia, mas também expandiu as capacidades de processamento, armazenamento e comunicação de dados. Desde os dispositivos móveis que se tornaram extensões de nossas vidas cotidianas, quase como órteses, até as vastas infraestruturas de computação em nuvem e os complexos sistemas distribuídos que sustentam a economia digital global, cada avanço representa um novo horizonte de possibilidades e tem impacto profundo nas tecnologias que usamos para desenvolver os sistemas operacionais.
Tecnologias como computação móvel, sistemas distribuídos, computação em nuvem e, mais recentemente, computação quântica e inteligência artificial estão moldando os sistemas operacionais modernos. Ao mesmo tempo em que só podem ser criadas graças a existência destes sistemas em uma laço de realimentação. Entre estas inovações, destacamos que a convergência entre Modelos de Linguagem de Grande Escala (LLMs) e computação quântica está força a criação urgente de uma nova geração de sistemas operacionais que combinará processamento de linguagem natural avançado com capacidades computacionais quânticas.
Sistemas Operacionais Embarcados e IoT: Conectando o Mundo Físico
Com o avanço da Internet das Coisas (IoT) e a proliferação de dispositivos conectados, os sistemas operacionais embarcados tornaram-se pilares fundamentais da infraestrutura tecnológica em 2025. Esses sistemas são projetados para operar em hardware com recursos limitados, como microcontroladores e sensores, garantindo eficiência, confiabilidade e, frequentemente, operação em tempo real. Diferentemente dos sistemas operacionais para desktops ou servidores, os sistemas embarcados priorizam baixo consumo de energia, tamanho reduzido de código e resposta determinística a eventos externos.
Características e Desafios dos Sistemas Operacionais Embarcados
Os sistemas operacionais embarcados, criados para ambientes restritos em recursos, como dispositivos portáteis, ou para ambientes de uso específico, como máquinas e robôs, ou ainda para aviônica e guerra, possuem características distintas dos sistemas operacionais genéricos tradicionais. Em 2025, as principais características incluem:
- Eficiência energética: algoritmos de gerenciamento de energia, como dynamic voltage and frequency scaling (DVFS), permitem que o sistema ajuste o consumo com base na carga de trabalho, essencial para dispositivos alimentados por bateria, como sensores IoT.
- Tamanho compacto: o código é otimizado para ocupar poucos kilobytes, adequando-se a microcontroladores com memória limitada (ex.: 32 KB de RAM).
- Tempo real: muitos sistemas embarcados são classificados como Real-Time Operating Systems (RTOS), garantindo respostas dentro de prazos estritos, como em dispositivos médicos ou controladores automotivos. Sistemas que analisaremos em uma seção posterior
- Conectividade: suporte a protocolos de rede leves, como MQTT e CoAP, permite comunicação eficiente em redes IoT, mesmo com largura de banda limitada.
- Segurança: Mecanismos como inicialização segura (secure boot), criptografia embarcada e atualizações over-the-air (OTA) protegem dispositivos contra ataques cibernéticos, um desafio crescente em dispositivos criados para integração com a internet e ubiquidade.
Os sistemas embarcados enfrentam desafios únicos característicos de ambientes com restrições de recursos e requisitos específicos de desempenho. Como não existem padrões universais de hardware nestes dispositivos os sistemas operacionais embarcados enfrentam um problema de fragmentação. Cada dispositivo pode ter diferentes microcontroladores, sensores e protocolos de comunicação, exigindo que os sistemas operacionais sejam altamente adaptáveis e modulares. Além disso, a segurança é uma preocupação crítica, pois a vulnerabilidade de um único dispositivo pode comprometer toda a rede IoT. A integração com inteligência artificial, especialmente com modelos leves como TinyML, está se tornando comum para permitir processamento local em dispositivos embarcados, aumentando a capacidade computacional necessária.
Além da fragmentação dos dispositivos, os sistemas embarcados que operam em dispositivos conectados à internet, IOT, enfrentam os problemas de Segurança em escala: Com bilhões de dispositivos IoT conectados, vulnerabilidades em um único dispositivo podem comprometer redes inteiras.
Recentemente, a Integração com sistemas de Inteligência Artificial, por meio da inclusão de modelos de Inteligência Artificial leves, uma demanda do mercado de dispositivos integrados a internet, levou a novos desafios. Maximize este problema considerando a existência de dispositivos militares, ou de aeronáutica, que exigem alta confiabilidade e segurança. A integração de modelos de IA em sistemas embarcados requer otimização cuidadosa para garantir que os dispositivos possam processar dados localmente sem comprometer o desempenho ou a segurança. Além disso, a necessidade de atualizações regulares de software para corrigir vulnerabilidades e melhorar funcionalidades é um desafio constante, especialmente em dispositivos implantados remotamente.
A curiosa leitora irá encontrar sistemas operacionais embarcados transformando setores como saúde (ex.: monitores cardiovasculares conectados), transporte (ex.: veículos autônomos), e indústria (ex.: robôs de montagem, manutenção e diagnóstico). Finalmente, a persistente leitora não deve deixar de notar que o design desses sistemas exige um equilíbrio delicado entre inovação tecnológica e responsabilidade social.
Exemplos de Sistemas Operacionais Embarcados
-
FreeRTOS: desenvolvido pela Amazon, o FreeRTOStext é um RTOS de código aberto amplamente utilizado em dispositivos IoT e embarcados. Sua arquitetura modular suporta microcontroladores de baixa potência, como os da família ARM Cortex-M. O FreeRTOS oferece escalonamento preemptivo, comunicação inter-tarefa via filas e semáforos, e integração com o AWS IoT Core para conectividade em nuvem. Em 2025, é comum em dispositivos como termostatos inteligentes e sensores industriais.
-
Zephyr: mantido pela Linux Foundation, o Zephyr um RTOS projetado para IoT, com suporte a uma ampla gama de arquiteturas (ARM, RISC-V, x86). Ele se destaca por sua escalabilidade, permitindo uso em dispositivos com apenas 8 KB de RAM, e por sua pilha de rede completa, incluindo Bluetooth Low Energy (BLE) e Thread. O Zephyr é usado em wearables, como smartwatches, e em redes de sensores para cidades inteligentes.
-
QNX: o QNX é um RTOS comercial baseado em microkernel, amplamente adotado em sistemas críticos, como automóveis e dispositivos médicos. Sua arquitetura modular e certificações de segurança (ex.: ISO 26262 para automotivos) o tornam ideal para aplicações onde falhas não são toleráveis. Em 2025, o QNX é usado em sistemas de assistência ao motorista (ADAS) e em dispositivos IoT industriais.
-
RIOT: o RIOT é um sistema operacional de código aberto voltado para dispositivos IoT de baixa potência. Ele suporta múltiplos protocolos de rede (ex.: 6LoWPAN, RPL) e é compatível com microcontroladores de 8 e 32 bits. Sua comunidade ativa e foco em interoperabilidade o tornam popular em projetos de pesquisa e protótipos de IoT, como redes de sensores ambientais.
Sistemas Operacionais Móveis
A ascensão dos dispositivos móveis, como smartphones e tablets, redefiniu a computação pessoal e impulsionou a necessidade de sistemas operacionais altamente especializados. Diferentemente dos sistemas para desktops, os sistemas operacionais móveis são projetados para operar em hardware com recursos inerentemente limitados em termos de capacidade de processamento, memória e autonomia de bateria.
Desde o iPhone (2005), o foco no design dos sistemas operacionais móveis centrou-se em interfaces de toque intuitivas, com a introdução de gestos multitoque como swiping e pinch-to-zoom, que se tornaram padrão e transformaram a experiência do usuário em um diferencial competitivo fundamental. Com impacto direto na criação de novos conceitos para o desenvolvimento dde sistemas operacionais, como a introdução de widgets e notificações interativas, que permitiram uma interação mais dinâmica e personalizada com o usuário. Além disso, a integração de sensores como acelerômetros, giroscópios e GPS ampliou as possibilidades de interação e personalização, permitindo que os dispositivos móveis se tornassem não apenas ferramentas de comunicação, mas também plataformas multifuncionais para uma variedade de aplicações, desde navegação até monitoramento de saúde.
As duas plataformas predominantes no mercado de sistemas operacionais móveis são o Android, desenvolvido pelo Google, e o iOS, da Apple. O Android é baseado no kernel Linux e adota um modelo de código aberto, o que permite aos fabricantes uma ampla customização e adaptação aos seus dispositivos, embora essa flexibilidade também contribua para a fragmentação do ecossistema. O Android utiliza o SQLite para armazenamento de dados estruturados e, historicamente, a máquina virtual Dalvik, posteriormente substituída pela Android Runtime - ART, para a execução de aplicativos desenvolvidos primariamente em Java ou Kotlin. O Android oferece suporte extensivo a uma vasta gama de tecnologias de conectividade, incluindo GSM/EDGE, CDMA, EV-DO, UMTS, LTE, 5G, Bluetooth, Wi-Fi e WiMAX.
O iOS é derivado do macOS e opera em um modelo de plataforma fechada, com uma integração vertical forte entre hardware e software, o que frequentemente resulta em alto desempenho e otimização de recursos. Sua arquitetura é organizada em camadas distintas: Core OS, que inclui o kernel do sistema operacional, gerenciamento de energia e segurança, Core Services, responsável por serviços como acesso a arquivos, rede e banco de dados SQLite, Media, para áudio, vídeo e gráficos, e *Cocoa Touch, que gerencia as interações do usuário, incluindo gestos multitoque e acesso a sensores.
A conectividade é uma das pedras angulares dos sistemas operacionais móveis, com suporte essencial para um amplo espectro de tecnologias de rede, incluindo Wi-Fi, redes celulares (3G, 4G e, cada vez mais, 5G) e Bluetooth, garantindo comunicação constante e acesso a serviços online. A chegada do 5G, com suas promessas de velocidades significativamente mais altas e latência ultrabaixa, impõe novas demandas aos sistemas operacionais móveis para gerenciar essas capacidades e habilitar novas classes de aplicações, como realidade aumentada (AR) e interações em tempo real mais ricas.
Segurança e privacidade são preocupações primordiais no design de sistemas operacionais móveis. Eles implementam modelos de permissão granulares, exigindo consentimento explícito do usuário para que aplicativos acessem recursos sensíveis como câmera, microfone, dados de localização e contatos. O sandboxing de aplicativos é uma técnica comum, isolando os processos e dados de cada aplicativo para prevenir interferências maliciosas e limitar o impacto de possíveis vulnerabilidades. A criptografia de dados, tanto em repouso no dispositivo quanto em trânsito pela rede, é amplamente utilizada para proteger informações sensíveis. Apesar desses mecanismos, os sistemas operacionais móveis enfrentam desafios contínuos devido à evolução constante de ameaças cibernéticas sofisticadas e à complexidade do ecossistema de aplicativos.
Sandboxing: Protegendo Sistemas Móveis
O sandboxing é uma técnica de segurança que isola aplicativos em ambientes restritos, mencionada nos sistemas operacionais móveis como Android e iOS. Cada aplicativo opera em um sandbox, com acesso limitado a recursos do sistema (como câmera ou contatos) e dados de outros aplicativos. Isso minimiza o impacto de vulnerabilidades, pois um aplicativo comprometido não pode afetar o sistema ou outros processos. Por exemplo, no iOS, o sandboxing é implementado via restrições do kernel, garantindo privacidade e estabilidade.
A amável leitora deve ter usado um destes sistemas operacionais móveis e percebido que ambos colocam uma ênfase significativa em segurança e privacidade, incorporando recursos como autenticação biométrica e criptografia de ponta a ponta para comunicações. No entanto, o gerenciamento eficiente de energia é, talvez, o desafio mais importante para os sistemas operacionais móveis, dada a dependência de baterias com capacidade finita. Para enfrentar essa questão, os sistemas operacionais móveis empregam estratégias sofisticadas. Estas estratégias incluem o gerenciamento dinâmico de estados de energia dos componentes de hardware, como a CPU, que pode operar em modos de baixo consumo ou ser colocada em estados de sleep durante períodos de inatividade. Isso só é possível graças a relação simbiótica entre o sistema operacional e o hardware, nesta relação, o sistema operacional é responsável por monitorar a atividade do usuário e ajustar dinamicamente o desempenho da CPU e outros componentes para otimizar o consumo de energia. Novamente em um laço de realimentação: há uma necessidade, cria-se um hardware que atenda a esta necessidade, o sistema operacional é adaptado para tirar proveito deste hardware, e assim por diante.
O Android, por exemplo, implementa seu próprio sistema de gerenciamento de energia sobre o Linux Power Management, utilizando wake locks para permitir que aplicações requisitem recursos da CPU apenas quando necessário, garantindo que a CPU não consuma energia desnecessariamente se não houver aplicações ou serviços ativos demandando processamento.
É possível que a observadora leitora tenha notado, nos últimos anos, a evolução das técnicas de gerenciamento de energia, transcendendo os modos manuais de economia para sistemas adaptativos e preditivos baseados em inteligência artificial. O Android introduziu recursos como Adaptive Battery, que aprende os padrões de uso do usuário para otimizar o consumo de energia, gerenciando o desempenho e a eficiência em segundo plano.Similarmente, o iOS, a partir da versão 19, deve introduzir otimizações de bateria baseadas em inteligência artificial, que aprendem os hábitos de uso de aplicativos, limitam atividades em segundo plano de forma inteligente e preveem necessidades de recarga, com todo o processamento ocorrendo no dispositivo para preservar a privacidade do usuário.
A atenta leitora deve ter em mente que esta transição para uma gestão energética proativa, na qual o Sistema Operacional antecipa e se adapta às necessidades do usuário de forma quase invisível, usando inteligência artificial, representa uma mudança fundamental, aliviando o usuário da carga cognitiva de gerenciar manualmente essas configurações. Tirando relação entre hardware e software do mundo determinístico da computação imperativa para o mundo probabilístico, mais fluido e adaptativo da inteligência artificial. Neste admirável mundo novo o sistema aprenderá e se ajustará continuamente às necessidades do usuário.
A crescente sofisticação da IA no gerenciamento de energia e na personalização da experiência do usuário, embora traga benefícios evidentes em termos de usabilidade e eficiência, também levanta questões importantes sobre a privacidade dos dados de uso do dispositivo. Mesmo com o processamento ocorrendo localmente no dispositivo, como destacado para o iOS, a coleta e análise detalhada de hábitos de uso – quais aplicativos são usados, em que horários, possivelmente inferindo locais e rotinas – são inerentemente sensíveis. Surge um dilema entre a conveniência da automação inteligente, que torna o gerenciamento de recursos “invisível e contínuo”, e a manutenção da transparência e do controle por parte do usuário sobre as operações do seu dispositivo. Enquanto algumas plataformas, como a One UI da Samsung, buscam oferecer “controles granulares”, a tendência geral da IA é para uma adaptação cada vez mais autônoma. Este equilíbrio delicado entre personalização avançada, privacidade e controle do usuário continuará a ser um campo de debate e desenvolvimento para os futuros sistemas operacionais móveis, podendo influenciar as preferências dos consumidores e até mesmo levar a novas regulamentações sobre os dados utilizados por IAs embarcadas.
A tabela a seguir apresenta um comparativo entre as duas principais plataformas de sistemas operacionais móveis, Android e iOS, destacando suas características fundamentais e abordagens recentes, especialmente no que tange ao gerenciamento de energia.
| Característica | Android | iOS |
|---|---|---|
| Arquitetura Base | Kernel Linux | Derivado do macOS, arquitetura em camadas (Core OS, Core Services, Media, Cocoa Touch) |
| Modelo de Distribuição | Código aberto, customizável por fabricantes | Plataforma fechada, proprietária da Apple |
| Interface Predominante | Interfaces de toque, alta customização da UI pelos fabricantes | Interfaces de toque (multitoque, gestos), design de UI consistente e controlado pela Apple |
| Gerenciamento de Energia | Android Power Management, wake locks, Adaptive Battery, controles granulares (One UI) | Gerenciamento de energia integrado, otimização de bateria baseada em IA (a partir do iOS 19) |
| Conectividade | Amplo suporte: GSM/EDGE, CDMA, EV-DO, UMTS, LTE, 5G, Bluetooth, Wi-Fi, WiMAX | Amplo suporte: GSM/EDGE, CDMA, EV-DO, UMTS, LTE, 5G, Bluetooth, Wi-Fi |
| Segurança | Sandboxing de apps, modelo de permissões, criptografia, Google Play Protect | Sandboxing de apps, modelo de permissões, criptografia forte, Face ID/Touch ID, Secure Enclave |
| Ecossistema de Aplicativos | Google Play Store, permite sideloading (instalação de apps de fora da loja oficial) | Apple App Store, política restrita de distribuição de apps |
Tabela 1: Comparativo entre Android e iOS, destacando suas características fundamentais e abordagens recentes, especialmente no que tange ao gerenciamento de energia.
A atenta leitora deve observar que esta comparação evidencia as filosofias distintas de design e as abordagens para desafios comuns, como o gerenciamento de energia, na qual ambas as plataformas estão convergindo para soluções mais inteligentes e adaptativas.
Sistemas Distribuídos
Um sistema distribuído é conceitualmente definido como uma coleção de computadores autônomos que se comunicam e cooperam por meio de uma rede, mas que se apresentam aos seus usuários como um único sistema coerente e unificado. Os principais objetivos para a construção de sistemas distribuídos são: o compartilhamento eficiente de recursos, hardware, software ou dados; o aumento de desempenho por meio do processamento paralelo; e a obtenção de maior confiabilidade e disponibilidade.
Para que um sistema distribuído funcione efetivamente e seja percebido como uma entidade única, ele deve exibir algumas características. Entre elas, destaca-se a transparência como uma das mais importantes. Neste caso, usamos a palavra transparência para fazer referência à capacidade do sistema de ocultar a separação e a distribuição de seus componentes dos usuários e dos programadores de aplicação. Existem diversas formas de transparência, sendo a transparência de localização e a transparência de acesso particularmente comuns.
A transparência de localização garante que usuários e aplicações não precisem conhecer a localização física dos recursos, enquanto a transparência de acesso assegura que recursos locais e remotos sejam acessados utilizando operações idênticas, abstraindo os detalhes de como o acesso é realizado. Mas, estas não são as únicas formas de transparência de Sistemas Operacionais Distribuídos. Outras formas incluem as transparências de replicação, falha, concorrência e migração, todas contribuindo para a ilusão de um sistema único.
A escalabilidade é outra característica importante. Neste caso, a escalabilidade denota a capacidade do sistema operar de forma eficaz e eficiente em diferentes escalas, ou seja, de se adaptar ao aumento da demanda por recursos sem que haja uma degradação significativa no desempenho ou a necessidade de alterar fundamentalmente o software ou as aplicações existentes. Em um mundo ideal, o processamento deve ser independente do tamanho da rede. No entanto, a escalabilidade pode ser limitada por gargalos como algoritmos centralizados, dados centralizados ou serviços centralizados que atendem a todos os usuários e que não possam ser distribuídos por limitações técnicas, econômicas ou de segurança.
Finalmente, a tolerância a falhas é a propriedade que permite a um sistema distribuído continuar operando corretamente, possivelmente com desempenho degradado, mesmo quando alguns de seus componentes falham. Isso é tipicamente alcançado por meio da redundância de hardware, software e dados, combinada com um design de software que permite a recuperação do estado consistente após a detecção de uma falha. As falhas podem ser classificadas como transientes, ocorrem uma vez e desaparecem, intermitentes, ocorrem esporadicamente, ou permanentes, persistem até serem reparadas. Intimamente relacionada à tolerância a falhas está a disponibilidade, que em sistemas distribuídos implica que a falha de um componente geralmente afeta apenas a parte do sistema que utiliza diretamente aquele componente, permitindo que o restante continue funcional.
Atualmente, uma das tendências mais significativas no desenvolvimento de sistemas distribuídos, com impacto direto na criação de sistemas operacionais, é a adoção da arquitetura de microserviços, que propõe a decomposição de aplicações monolíticas complexas em um conjunto de serviços menores, independentes e fracamente acoplados. Cada microserviço executa seu próprio processo e se comunica com outros serviços por meio de APIs (Interface de Programação de Aplicações) leves, frequentemente baseadas em HTTP/REST. Esta abordagem oferece benefícios como implantação independente de cada serviço, escalabilidade granular, permitindo que apenas os serviços mais demandados sejam escalados, e a possibilidade de usar diferentes tecnologias para diferentes serviços. A integração de microserviços com tecnologias de conteinerização, como Docker, e orquestradores, como Kubernetes, tem se mostrado particularmente eficaz para aumentar a tolerância a falhas e a resiliência, pois falhas em um microserviço podem ser isoladas sem derrubar toda a aplicação.
Outra tendência proeminente é a arquitetura orientada a eventos (Event-Driven Architecture - EDA). Em sistemas EDA, os componentes reagem a eventos, notificações assíncronas que representam ocorrências significativas, promovendo um baixo acoplamento entre eles e facilitando a escalabilidade. Por exemplo, em um sistema de comércio eletrônico, a conclusão de uma compra pode gerar um evento que é consumido por outros serviços, como o de faturamento, o de notificação ao cliente e o de expedição, sem que o serviço de compra precise conhecer diretamente esses outros serviços. O uso de servidores de mensagens, como Apache Kafka, é comum em EDAs para mediar a comunicação assíncrona.
O modelo distribuído AKKA, implementado por um toolkit e runtime para construir aplicações concorrentes, distribuídas e resilientes na JVM, Java Virtual Machine, baseado no modelo de atores, também ganhou tração para a construção de sistemas concorrentes e distribuídos resilientes e escaláveis. Os atores são entidades computacionais leves que se comunicam exclusivamente por meio da troca de mensagens assíncronas, embora padrões síncronos como “ask” possam ser implementados sobre a comunicação assíncrona “tell”. Estes atores podem ser distribuídos em um cluster de máquinas, permitindo que aplicações complexas sejam construídas a partir da composição de múltiplos atores colaborando para um objetivo comum. Aqui há uma relação interessante entre sistemas operacionais, sistemas distribuídos, máquinas virtuais e linguagens de programação. O AKKA é uma implementação do modelo de atores, que foi proposto por Carl Hewitt em 1973, e que foi inspirado no conceito de processos concorrentes do Lisp. O AKKA foi escrito em Scala, uma linguagem funcional que roda na JVM, e que permite a criação de aplicações distribuídas e reativas com alta performance e baixa latência.
A esperta leitora deve considerar que as novas tendências arquitetônicas, como microserviços e EDA, não surgem isoladamente, mas como respostas evolutivas diretas aos desafios de concretizar as características fundamentais de escalabilidade e tolerância a falhas em sistemas que se tornam progressivamente mais complexos e com demandas crescentes. Aplicações monolíticas tradicionais, por exemplo, enfrentam dificuldades intrínsecas para escalar componentes individuais de forma granular ou para isolar falhas eficazmente; uma falha em um módulo pode comprometer todo o sistema. Em contraste, a arquitetura de microserviços, ao decompor a aplicação em unidades menores e independentes, permite que cada serviço seja escalado conforme sua necessidade específica e que falhas sejam contidas dentro do serviço afetado, preservando a funcionalidade do restante do sistema. Similarmente, a EDA, ao promover o desacoplamento por meio da comunicação assíncrona baseada em eventos, aumenta a resiliência, os serviços não dependem diretamente da disponibilidade imediata uns dos outros< e a escalabilidade, os produtores de eventos podem operar independentemente dos consumidores.
A proliferação de componentes distribuídos, sejam eles microserviços, atores, ou os inúmeros dispositivos de borda em um sistema de IoT, acarreta um aumento exponencial na complexidade do gerenciamento do sistema como um todo. Manter a coerência, a eficiência, o monitoramento e a depuração em um ambiente com milhares ou milhões de partes móveis é um desafio formidável que deve ser enfrentado pelos Sistemas Operacionais. Isso aponta para uma possível evolução em direção a sistemas operacionais distribuídos, ou camadas de gerenciamento de sistema equivalentes, que incorporem níveis mais elevados de inteligência artificial e aprendizado de máquina. Tais sistemas poderiam realizar auto-configuração, auto-otimização, auto-reparação e gerenciamento proativo de recursos de forma mais autônoma, uma trajetória análoga à observada nos sistemas operacionais móveis com suas capacidades adaptativas de gerenciamento de energia.
A tabela a seguir resume as propriedades essenciais dos sistemas distribuídos e como as tendências arquitetônicas modernas se alinham e aprimoram essas propriedades.
| Paradigma/Característica | Descrição | Tecnologias/Exemplos Chave | Benefícios Principais |
|---|---|---|---|
| Transparência (Localização, Acesso) | Ocultar a distribuição dos componentes, permitindo acesso uniforme a recursos locais/remotos. | Middleware, RPC, Nomes de Serviço. | Simplificação do desenvolvimento, percepção de sistema único. |
| Escalabilidade | Capacidade de operar eficientemente em diferentes escalas, adaptando-se ao aumento da demanda. | Balanceamento de Carga, Replicação, Particionamento de Dados. | Suporte ao crescimento, desempenho consistente. |
| Tolerância a Falhas | Continuar operando corretamente mesmo com falhas em componentes, por meio de redundância e recuperação. | Replicação de Dados/Serviços, Checkpointing, Transações Distribuídas. | Alta disponibilidade, resiliência. |
| Arquitetura de Microserviços | Decomposição da aplicação em pequenos serviços independentes e fracamente acoplados. | Docker, Kubernetes, APIs REST/gRPC. | Implantação independente, escalabilidade granular, diversidade tecnológica, resiliência. |
| Arquitetura Orientada a Eventos (EDA) | Sistemas reagem a eventos assíncronos, promovendo baixo acoplamento e escalabilidade. | Apache Kafka, RabbitMQ, Filas de Mensagens. | Desacoplamento, escalabilidade, resiliência, capacidade de resposta em tempo real. |
| Computação de Borda/Névoa | Processamento de dados mais próximo da origem, reduzindo latência e uso de banda. | Dispositivos IoT, Gateways de Borda, Edge AI, Plataformas de Fog Computing. | Baixa latência, economia de banda, processamento em tempo real, privacidade aprimorada. |
Tabela 2: Propriedades essenciais dos sistemas distribuídos e como as tendências arquitetônicas modernas se alinham e aprimoram essas propriedades.
Esta visão panorâmica conecta os conceitos teóricos fundamentais dos sistemas distribuídos com as implementações práticas e as tendências que estão moldando ativamente este campo vital da computação.
Computação em Nuvem
A computação em nuvem teve, e tem, um impacto importante no projeto, desenvolvimento e suporte de sistemas operacionais. Este impacto pode ser analisado por meio de algumas das características deste sistema computacional.
O autoatendimento sob demanda, característico da nuvem, requer que sistemas operacionais suportem provisionamento automático de recursos por meio de APIs, eliminando a necessidade de configuração manual e exigindo mecanismos robustos de automação. Da mesma forma, o amplo acesso à rede, também muito importante na nuvem, demanda que sistemas operacionais sejam otimizados para plataformas e dispositivos diversos, necessitando de adaptabilidade e eficiência em ambientes heterogêneos de rede.
O agrupamento de recursos em modelos multilocatários impõe requisitos extras de isolamento e segurança aos sistemas operacionais. Os sistemas operacionais devem garantir que recursos físicos e virtuais sejam dinamicamente alocados entre múltiplos usuários sem comprometer a privacidade ou performance. Esta característica da nuvem exige mecanismos sofisticados de virtualização e controle de acesso.
A elasticidade, característica que permite os sistemas em nuvem de ajustar os recursos disponíveis de acordo com a demanda, representa o desafio mais significativo para sistemas operacionais. Sistemas operacionais devem ser capazes de ajustar dinamicamente recursos como CPU, memória e armazenamento em tempo real, respondendo a flutuações de demanda sem degradação de performance. Isso requer arquiteturas que suportem escalonamento horizontal e vertical automático, gerenciamento dinâmico de memória e otimização contínua de recursos.
O serviço mensurado, indispensável para a engenharia econômica dos sistemas em nuvem, exige que sistemas operacionais implementem capacidades extensivas de monitoramento e métricas, coletando dados detalhados sobre utilização de recursos para facilitar modelos de cobrança por uso e otimização de performance.
O provisionamento sob demanda, a criação de recursos computacionais, requer que sistemas operacionais suportem inicialização rápida, configuração automática e integração com interfaces de programação, permitindo que recursos sejam disponibilizados instantaneamente por meio de portais web ou APIs.
A multilocação, a arquitetura na qual uma solução de software atende múltiplos clientes, chamados de locatários, impõe requisitos fundamentais de segurança e isolamento aos sistemas operacionais. Estes devem garantir que múltiplos locatários compartilhem a mesma infraestrutura física mantendo completa separação de dados, processos e recursos, exigindo implementações robustas de virtualização e controle de acesso.
Além das características destacadas, os modelos de serviço populares na distribuição de computação em nuvem também influenciam o design de sistemas operacionais:
Software como Serviço (SaaS) requer sistemas operacionais otimizados para hospedar aplicações multi-usuário com alta disponibilidade e performance consistente. O sistema operacional deve ser transparente ao usuário final, focando na eficiência de execução de aplicações.
Plataforma como Serviço (PaaS) demanda sistemas operacionais que suportem múltiplas linguagens de programação, bibliotecas e frameworks, com capacidades de isolamento entre aplicações e gerenciamento automático de recursos de desenvolvimento.
Infraestrutura como Serviço (IaaS) requer sistemas operacionais que funcionem eficientemente como hosts de virtualização, suportando a criação e gerenciamento de múltiplas instâncias de sistemas operacionais convidados com performance próxima ao hardware nativo.
Esses requisitos transformam fundamentalmente como sistemas operacionais são projetados, exigindo arquiteturas mais modulares, eficientes em recursos, e capazes de operação autônoma em ambientes distribuídos e dinâmicos.
Inteligência Artificial e Modelos de Linguagem de Grande Escala (LLMs)
Os LLMs, como o GPT-4 ou modelos similares, são exemplos excelentes para avaliação dos impactos que as tecnologias de inteligência artificial terão sobre os sistemas operacionais. Os LLMs requerem recursos computacionais significativos, geralmente executados em sistemas de computação de alto desempenho equipados com GPUs, TPUs ou LPUs. Esses modelos possuem bilhões de parâmetros, exigindo processamento paralelo eficiente. Neste caso, a criativa leitora deve considerar que os sistemas operacionais deverão enfrentar os seguintes desafios:
- Alta Demanda Computacional: a execução de LLMs sobrecarrega a CPU, GPU e memória, exigindo sistemas operacionais que otimizem a alocação de recursos;
- Consumo de Energia: o treinamento e a inferência de LLMs consomem grandes quantidades de energia, com estimativas de até 1.287.000 kWh para treinamento, gerando preocupações ambientais com emissões de carbono de cerca de $552$ toneladas;
- Gestão de Memória: sistemas operacionais precisam gerenciar eficientemente grandes quantidades de memória para suportar os modelos, especialmente em dispositivos de borda com recursos limitados.
Existem também preocupações de segurança associadas ao uso de LLMs. Os LLMs podem ser explorados para gerar conteúdo malicioso, como e-mails de phishing ou código malicioso, representando riscos de segurança. Os sistemas operacionais precisam se adaptar para mitigar esses problemas atuando na Detecção de Conteúdo Malicioso, os sistemas operacionais podem e devem incorporar ferramentas de segurança avançadas para identificar e bloquear conteúdo gerado por LLMs que possa comprometer a segurança. Os sistemas operacionais também devem implementar medidas de Proteção de Dados, sistemas como os LLMs frequentemente requerem acesso a grandes quantidades de dados do usuário, os sistemas operacionais precisam implementar medidas robustas de proteção de dados para evitar vazamentos.
Integração de LLMs em Sistemas Operacionais
Os LLMs estão sendo integrados aos sistemas operacionais de maneiras inovadoras, por uma tecnologia conhecida como Large LLMOS Revolution (LLMOS) transformando a interação entre usuários e dispositivos. Esta integração pode ser vista em várias frentes:
- Embutidos no Núcleo do Sistema: LLMs podem ser incorporados diretamente no sistema operacional, funcionando como um “kernel” para interações em linguagem natural. Parte desta tecnologia pode ser vista no LLMO, um sistema operacional que utiliza LLMs para fornecer uma interface de usuário baseada em linguagem natural, permitindo que os usuários interajam com o sistema de forma mais intuitiva e eficiente.
- APIs e Plugins: assistentes inteligentes, como o Windows Copilot, utilizam APIs para integrar capacidades de LLMs, permitindo comandos simplificados e algum nível de automação.
- Aplicações Especializadas: aplicativos que aproveitam LLMs, como ferramentas de geração de texto ou análise de dados, dependem de sistemas operacionais para gerenciar suas operações.
A integração de LLMs em sistemas operacionais tem impacto positivo na experiência do usuário por meio de interfaces mais intuitivas e inteligentes. Os assistentes de voz evoluem para compreender contexto, nuances linguísticas e intenções implícitas, permitindo conversas naturais que transcendem comandos rígidos e pré-definidos. Esta capacidade estende-se ao processamento de comandos complexos expressos em linguagem natural, na qual usuários podem descrever tarefas multifacetadas sem conhecer sintaxes específicas ou sequências de operações técnicas.
A capacidade de busca e integração semântica representa uma transformação paradigmática. A perspicaz leitora pode quantizar este impacto focando no sistema de arquivos. Considere que a integração semântica irá permitir que sistemas operacionais compreendam intenções de busca independentemente de palavras-chave exatas. Usuários podem localizar arquivos, aplicações e informações por meio de descrições conceituais, relacionamentos semânticos e associações contextuais, integrando busca multimodal que correlaciona texto, imagens, áudio e vídeo de forma unificada e inteligente.
A implementação de LLMs em sistemas operacionais apresenta limitações técnicas e operacionais que afetam sua integração prática. O consumo de recursos computacionais é substancial, com modelos requerendo quantidades específicas de memória e capacidade de processamento que podem impactar a performance global do sistema, particularmente em dispositivos com recursos limitados como smartphones, tablets e sistemas embarcados. Esta demanda computacional exigirá um balanceamento entre funcionalidade e capacidade computacional um pouco mais delicada do que as escolhas que já existem nos sistemas puramente determinísticos.
As considerações de privacidade envolvem coleta, processamento e armazenamento de dados pessoais necessários para operação dos LLMs. Os modelos requerem acesso a padrões de uso, preferências comportamentais e dados contextuais para funcionalidade efetiva, criando requisitos específicos para conformidade regulatória, gestão de consentimento e proteção de dados.
A confiabilidade dos LLMs apresenta características operacionais específicas, incluindo variabilidade nas respostas geradas, potencial para produzir saídas imprecisas ou contextualmente inadequadas, e dependência de dados de treinamento que podem conter vieses. Esta variabilidade requer implementação de mecanismos de validação, monitoramento de saídas e sistemas de verificação para operação consistente do sistema operacional.
| Aspecto | Desafio | Efeito no Sistema Operacional |
|---|---|---|
| Recursos Computacionais | Alta demanda por GPUs/TPUs e memória | Necessidade de otimização de alocação de recursos |
| Consumo de Energia | Uso intensivo de energia durante treinamento e inferência | Gestão de energia eficiente para reduzir custos e impacto ambiental |
| Segurança | Geração de conteúdo malicioso | Implementação de ferramentas de detecção e mitigação |
| Privacidade | Acesso a grandes quantidades de dados do usuário | Medidas robustas de proteção de dados |
| Confiabilidade | Saídas imprevisíveis ou tendenciosas | Validação e monitoramento contínuos |
Tabela 3: Desafios da Integração de LLMs em Sistemas Operacionais e seus Efeitos
O Impacto da Computação Quântica em Sistemas Operacionais
A computação quântica representa uma mudança de paradigma fundamental, utilizando como elemento fundamental os qubits que podem existir em superposição, $0$, $1$ ou combinação de ambos, e emaranhamento entre múltiplos qubits. Essas propriedades permitem explorar um espaço computacional vastamente maior e realizar certos cálculos exponencialmente mais rápidos que computadores clássicos, com potencial para resolver problemas NP-difíceis em otimização, simulação molecular, criptografia e aprendizado de máquina.
Problemas NP-difíceis são uma classe de problemas computacionais extremamente desafiadores que não possuem algoritmos conhecidos capazes de resolvê-los em tempo polinomial (ou seja, de forma eficiente) em computadores clássicos. Exemplos incluem o problema do caixeiro viajante, fatoração de números grandes e otimização de rotas complexas. Estes problemas são fundamentais em criptografia, logística e simulação científica. A computação quântica oferece potencial para resolver alguns destes problemas exponencialmente mais rápido que métodos clássicos, representando uma das principais motivações para o desenvolvimento de tecnologias quânticas.
Atualmente, a computação quântica encontra-se na era NISQ (Noisy Intermediate-Scale Quantum), com qubits limitados e suscetíveis a ruído e decoerência, restringindo a profundidade dos circuitos executáveis. Essas limitações tornam necessários os Sistemas Operacionais Quânticos (QCOS).
Um QCOS é uma camada de software especializada que gerencia hardware quântico, coordena alocação de recursos quânticos e facilita a execução de algoritmos quânticos em QPUs, unidades de processamento quânticas. Enquanto sistemas operacionais clássicos gerenciam CPU, memória e I/O, um QCOS deve lidar com desafios únicos como gerenciamento de emaranhamento, manutenção de coerência de qubits e correção de erros quânticos. As funções primárias de um QCOS incluem: o Gerenciamento de Recursos Quânticos, a manipulação cuidadosa de qubits, garantindo inicialização correta, emaranhamento conforme necessário e medição precisa; a Correção de Erros Quânticos e Mitigação de Ruído, caracterizada pela aplicação de algoritmos de correção de erros quânticos (QEC) ou técnicas de mitigação de erros na era NISQ para aumentar a fidelidade dos resultados; o Escalonamento e Otimização de Algoritmos Quânticos, para o escalonamento eficiente de operações quânticas, otimizando execução para reduzir tempo e maximizar utilização de recursos por meio de compiladores e runtime que gerenciam execução em múltiplas QPUs; e, finalmente, a Abstração e Interface, o fornecimento de camada de abstração sobre complexidade do hardware quântico, como a abstração Qernel que expõe APIs transparentes para execução de jobs quânticos.
Qernel: Interface para Hardware Quântico
O termo Qernel, mencionado nos sistemas operacionais quânticos (QCOS), refere-se a uma camada de abstração que simplifica a interação com hardware quântico. Semelhante a um kernel clássico, o Qernel gerencia qubits, operações quânticas e medições, oferecendo APIs para programadores. Ele oculta complexidades como decoerência e conectividade de qubits, permitindo o desenvolvimento de algoritmos quânticos sem conhecimento detalhado do hardware. Plataformas como Qiskit e Cirq utilizam conceitos similares para facilitar a programação quântica.
A esperta leitora não deve se assustar. Contudo, o desenvolvimento de QCOS enfrenta desafios significativos característicos dos fenômenos físicos envolvidos: decoerência e ruído exigem mecanismos sofisticados de mitigação; escalabilidade torna-se exponencialmente difícil com aumento de qubits; integração com sistemas clássicos é fundamental para modelos híbridos; e a confiabilidade do próprio QCOS deve ser extremamente alta.
As arquiteturas de computação híbrida quântica-clássica estão emergindo como abordagem promissora, nas quais computadores clássicos trabalham com QPUs. O QPU atua como acelerador especializado para partes de software que podem ser beneficiadas com o uso da computação quântica, enquanto o sistema clássico lida com conversão de código entre paradigmas, orquestração, preparação de dados e pós-processamento. Nestes sistemas, hardware especializado como GPUs e FPGAs/RFSoCs desempenha as funções de controle e medição de qubits.
O sistema operacional em ambiente híbrido orquestra tarefas entre componentes clássicos e quânticos, gerenciando fluxo de dados e sincronização, abstraindo complexidade do hardware quântico e facilitando algoritmos híbridos como VQE e QAOA.
| Componente/Função do QCOS | Descrição da Função | Desafios Associados | Tecnologias/Abordagens Relevantes |
|---|---|---|---|
| Gerenciamento de Qubits | Inicialização, manipulação de estados quânticos (superposição, emaranhamento), medição precisa de qubits. | Manter a coerência dos qubits, controle preciso de operações quânticas, escalabilidade para grande número de qubits. | Pulsos de micro-ondas/laser, armadilhas de íons, qubits supercondutores, hardware de controle (FPGAs, RFSoCs). |
| Correção de Erros Quânticos/Mitigação de Ruído | Identificar e corrigir/mitigar erros devido à decoerência e ruído para manter a integridade da computação. | Fragilidade dos estados quânticos, overhead de qubits e operações para QEC, complexidade dos códigos corretores. | Códigos de correção de erros quânticos (e.g., código de superfície), técnicas de mitigação de erros (e.g., Zero Noise Extrapolation). |
| Escalonamento e Otimização de Circuitos | Agendar operações quânticas eficientemente, otimizar circuitos para reduzir profundidade/contagem de portas. | Limitações de conectividade entre qubits, tempos de coerência finitos, heterogeneidade de QPUs. | Compiladores quânticos, algoritmos de roteamento e mapeamento de qubits, técnicas de otimização de circuitos, multi-programação. |
| Interface/Abstração de Hardware (e.g., Qernel) | Fornecer uma interface de alto nível para programadores, abstraindo a complexidade do hardware quântico. | Diversidade de arquiteturas de hardware quântico, ocultar a natureza ruidosa do hardware. | APIs de programação quântica (e.g., Qiskit, Cirq), linguagens de descrição de circuitos, abstração Qernel. |
| Suporte a Modelos Híbridos | Orquestrar a execução entre processadores clássicos e quânticos, gerenciar fluxo de dados e sincronização. | Latência na comunicação clássico-quântica, sincronização eficiente, desenvolvimento de algoritmos híbridos. | Algoritmos variacionais (VQE, QAOA), plataformas de computação híbrida (Ex.: Azure Quantum). |
Exemplos de Sistemas Operacionais Quânticos
Um QCOS gerencia recursos quânticos, como qubits, portas quânticas e circuitos, de forma análoga a como um sistema operacional clássico gerencia CPU, memória e E/S. O Qernel, componente central, orquestra a alocação de qubits, o escalonamento de operações quânticas e a mitigação de erros causados por decoerência e ruído, desafios inerentes aos processadores quânticos atuais. Ainda que eles se distinguam dos sistemas operacionais clássicos, podemos citar:
-
Qiskit Runtime (IBM) O Qiskit Runtime é uma plataforma que atua como uma camada de abstração para gerenciar computação quântica em hardware da IBM, como o IBM Quantum Eagle (127 qubits). Ele fornece uma interface para escalonar circuitos quânticos, otimizar alocação de qubits e executar algoritmos híbridos quântico-clássicos. Em 2025, o Qiskit Runtime é usado em aplicações como simulação de moléculas químicas e otimização logística, demonstrando a viabilidade de um QCOS rudimentar.
-
Cirq e TensorFlow Quantum (Google) O Cirq, combinado com o TensorFlow Quantum, forma um ecossistema para desenvolver e executar programas quânticos no hardware do Google, como o processador Sycamore. Essas ferramentas gerenciam a compilação de circuitos quânticos, a alocação de recursos e a integração com algoritmos de machine learning. Um exemplo prático é a simulação de sistemas quânticos em física de matéria condensada, onde o Cirq atua como uma interface de sistema operacional quântico.
-
SpinQ QOS A SpinQ Technology, uma empresa chinesa, lançou em 2025 o Quantum Operating System (QOS), projetado para seus processadores quânticos de pequena escala (2-20 qubits). O QOS gerencia a inicialização de qubits, a execução de circuitos e a correção de erros em tempo real, com uma interface amigável para pesquisadores. Ele é usado em educação e pesquisa, permitindo experimentos com algoritmos como Shor e Grover em hardware acessível.
-
Orca Computing PT-1 A Orca Computing desenvolveu um sistema operacional quântico para seu processador fotônico PT-1, que opera com qubits baseados em fótons. Esse sistema gerencia a multiplexação temporal de qubits e a integração com sistemas clássicos, sendo aplicado em problemas de otimização em finanças e telecomunicações.
-
D-Wave Ocean SDK O Ocean SDK da D-Wave é um sistema operacional quântico híbrido que combina recozimento quântico com computação clássica. Ele permite a modelagem de problemas de otimização complexos, como roteamento de veículos e alocação de recursos, utilizando o processador quântico Advantage. O Ocean SDK gerencia a alocação de qubits, a execução de algoritmos quânticos e a integração com sistemas clássicos.
Estes sistemas operacionais quânticos, se já pudermos chamar assim, estão em estágios iniciais de desenvolvimento. Contudo, já demonstram a viabilidade de gerenciar recursos quânticos e executar algoritmos complexos:
- Simulação Química: O Qiskit Runtime foi usado pela Merck em 2025 para simular interações moleculares, reduzindo o tempo de desenvolvimento de novos fármacos.
- Otimização Logística: A D-Wave, com seu sistema operacional híbrido para recozimento quântico, otimizou rotas de entrega para empresas como a Amazon, integrando recursos quânticos e clássicos.
- Criptografia: O QOS da SpinQ permitiu experimentos com algoritmos quânticos resistentes a ataques, como os baseados em reticulados, em laboratórios acadêmicos.
O progresso na computação quântica ocorre por meio de coevolução interdependente entre hardware, software e algoritmos. Avanços no hardware quântico permitem QCOSs mais sofisticados, que por sua vez viabilizam algoritmos mais complexos, criando um ciclo de feedback positivo. Os sistemas operacionais quânticos estão no nexo dessa coevolução, atuando como elemento unificador entre hardware e software algorítmico, sendo essenciais para democratizar o acesso e operacionalizar o potencial da computação quântica.## As Funções Essenciais: O Que Todo Sistema Operacional Deve Fazer
Funções Essenciais: O Que Todo Sistema Operacional Deve Fazer
Um sistema operacional desempenha uma miríade de funções para garantir que um sistema computacional opere de forma suave, eficiente e segura. Essas funções podem ser organizadas em um conjunto de categorias. Academicamente, existem dezenas, talvez centenas de formas diferentes de agregar estas funções. Eu escolhi uma forma que considero intuitiva e que pode ser facilmente compreendida por quem está começando a estudar sistemas operacionais. A Figura 8 ilustra um mapa intuitivo das funções essenciais de um sistema operacional, com o Sistema Operacional no centro.
 Figura 8: Mapa Intuitivo das funções essenciais de um sistema operacional
Figura 8: Mapa Intuitivo das funções essenciais de um sistema operacional
A seguir, a esforçada leitora encontrará uma descrição detalhada de cada uma dessas funções essenciais, organizadas em categorias que refletem as responsabilidades primárias de um sistema operacional.
Gerenciamento de Processos: Coordenando a Execução
Um processo é um programa em execução, incluindo o código do programa, seus dados, pilha, contador de programa e registradores da CPU. O sistema operacional é responsável por todas as atividades relacionadas aos processos. Fundamentalmente teremos:
- Criação e exclusão de processos de usuário e de sistema, os processos de usuário são aqueles iniciados por usuários, enquanto os processos de sistema são iniciados pelo próprio sistema operacional;
- Suspensão e retomada de processos conforme necessário. Para isso, o sistema operacional deve manter o estado do processo, incluindo registradores, contador de programa e pilha;
- Sincronização de processos para coordenar acesso a recursos compartilhados, evitando condições de corrida e garantindo consistência de dados;
- Comunicação entre processos (IPC) por meio de pipes, sockets, memória compartilhada, mensagens ou sinais, permitindo que processos troquem informações e coordenem suas atividades;
- Tratamento de deadlocks - situações nas quais processos ficam permanentemente bloqueados, impedindo que continuem sua execução, o sistema operacional deve detectar e resolver deadlocks para manter a operação do sistema.
Escalonamento da CPU: Gerenciando o Tempo do Processador
O escalonador da CPU é o componente do sistema operacional que decide qual dos processos na fila de prontos será alocado para execução na CPU. Sua função é gerenciar o acesso ao processador de forma a otimizar o desempenho geral do sistema, equilibrando objetivos que muitas vezes são conflitantes, como maximizar a vazão (throughput) e minimizar o tempo de resposta para o usuário.
Para avaliar a eficiência de um algoritmo de escalonamento, utilizamos métricas que medem o tempo gasto pelos processos em diferentes estados. As duas métricas que se destacam nesta análise são o Tempo de Resposta e o Tempo de Espera.
-
Tempo de Resposta (Turnaround Time): mede o intervalo de tempo total desde a chegada de um processo no sistema até a sua conclusão. É a soma do tempo de execução e do tempo de espera.
\[\text{Tempo de Resposta} = \text{Tempo de Término} - \text{Tempo de Chegada}\]Neste cálculo, consideramos:
- Tempo de Término: instante em que o processo finaliza sua execução;
- Tempo de Chegada: instante em que o processo entra na fila de prontos.
-
Tempo de Espera (Waiting Time): representa o tempo total que um processo passa aguardando na fila de prontos, esperando para ser executado pela CPU. Esta é a porção do tempo de resposta em que o processo não está em execução.
\[\text{Tempo de Espera} = \text{Tempo de Resposta} - \text{Tempo de Execução}\]Neste caso, temos:
- Tempo de Execução: tempo total que o processo efetivamente gasta utilizando a CPU.
A análise dessas métricas permite comparar diferentes algoritmos de escalonamento (como FCFS, SJF, Round Robin, etc.) e escolher o mais adequado para um determinado ambiente computacional.
Algoritmos de Escalonamento em Foco Abaixo estão três dos algoritmos de escalonamento mais fundamentais mencionados no documento. Cada um aborda o desafio de alocar a CPU de uma maneira diferente.
First-Come, First-Served (FCFS): os processos são executados na ordem de chegada. É o método mais simples, operando como uma fila de banco. O primeiro processo que solicita a CPU é o primeiro a recebê-la e a mantém até sua conclusão.
Shortest Job First (SJF): prioriza processos com menor tempo de execução estimado. Quando a CPU fica livre, ela é alocada ao processo que tem o menor tempo de execução previsto. Isso é eficiente para reduzir o tempo médio de espera, mas seu desafio prático é saber a duração de cada processo antecipadamente.
Round Robin (RR): cada processo recebe uma fatia de tempo fixa para executar. Uma pequena unidade de tempo, chamada quantum, é definida. Nenhum processo pode rodar por mais tempo que um quantum. Se não terminar, ele é movido para o final da fila e a CPU é passada para o próximo processo. É projetado para sistemas de tempo compartilhado, garantindo que o sistema permaneça responsivo a todos os usuários.
Gerenciamento de Memória: Otimizando o Uso de RAM
A memória principal, também conhecida como RAM (Random Access Memory), representa um dos recursos mais importantes e voláteis que devem ser gerenciados cuidadosamente em qualquer sistema operacional moderno. Diferentemente do armazenamento permanente, a RAM perde todo seu conteúdo quando a energia é removida, tornando seu gerenciamento uma tarefa que exige precisão e eficiência constantes.
O controle de alocação de processos em memória envolve manter um registro detalhado e atualizado de quais partes da memória estão em uso por processos ativos e quais permanecem disponíveis. A alocação dinâmica aumenta a complexidade desta tarefa ao exigir que o sistema constantemente atribua e libere espaço conforme processos são criados e terminados, criando um ambiente dinâmico de constante mudança. Além disso, o sistema deve lidar com a fragmentação da memória, que ocorre quando blocos de memória livre são divididos em pedaços pequenos e não contíguos, dificultando a alocação eficiente de novos processos.
Hierarquia de Memória
A hierarquia de memória é um conceito que representa a organização dos sistemas de armazenamento em um computador, organizados por velocidade, capacidade e custo. No topo desta hierarquia estão as unidades de armazenamento mais rápidas e caras, registradores da CPU e cache, enquanto na base estão os dispositivos de armazenamento mais lentos, mas de maior capacidade, discos rígidos e armazenamento óptico. Este conceito hierárquico existe por motivos econômicos. Porém, serve como base para a criação de rotinas para o uso eficiente de memória. Dois pontos desta hierarquia são importantes para esta introdução aos sistemas operacionais:
A memória cache serve como um buffer de alta velocidade entre a CPU e a memória principal, tipicamente implementada usando SRAM, do inglês Static RAM. Processadores modernos incluem múltiplos níveis de cache: cache L1, mais próximo aos núcleos da CPU, ~32KB-64KB, cache L2, ~256KB-1MB, e frequentemente cache L3, ~8MB-32MB, compartilhado entre núcleos. O cache opera no princípio da localidade temporal. Ou seja, considera que dados acessados recentemente provavelmente serão acessados novamente e localidade espacial, dados próximos provavelmente serão acessados em breve. Quando a CPU solicita dados, primeiro verifica sua existência no cache; um cache hit, o dado está no cache, fornece dados em 1-3 ciclos de clock, enquanto um cache miss, o dado não está no cache, requer acessar níveis de memória mais lentos.
A memória principal (RAM) consiste em um conjunto de chips DRAM volátil, do inglês Dynamic RAM, que armazena programas em execução e seus dados. Embora significativamente mais lenta que o cache, com latência típica de 100-300 ciclos de clock, a RAM fornece capacidade muito maior, alguma coisa entre 8GB e 64GB em sistemas modernos, a um custo razoável. O sistema operacional gerencia a alocação de RAM, mapeamento de memória virtual e o movimento de dados entre níveis de armazenamento. A RAM serve como o espaço de trabalho primário para processos ativos, com o sistema operacional tratando page faults, erros que ocorrem quando dados solicitados não estão presentes na memória física.
A proteção de memória garante que processos não acessem memória de outros processos, prevenindo interferências maliciosas ou acidentais que possam comprometer a estabilidade do sistema. O gerenciamento de memória virtual complementa essas responsabilidades ao criar a ilusão de o processo tem mais memória disponível que a memória fisicamente disponível, permitindo que múltiplos programas executem simultaneamente mesmo em sistemas com RAM limitada. À esta memória virtual damos o nome de espaço de endereçamento. Para implementar essas responsabilidades, os sistemas operacionais empregam técnicas como o particionamento fixo que divide a memória em partições de tamanho fixo predeterminado, oferecendo previsibilidade. Esta técnica relativamente simples corre o risco de ser ineficiente quando os tamanhos dos processos não correspondem aos tamanhos das partições fixamente definidas. Uma técnica mais complexa, o particionamento dinâmico, oferece maior flexibilidade ao criar partições conforme necessário. Neste caso, quando um novo processo solicita memória, o sistema cria uma partição exatamente do tamanho necessário, maximizando a utilização da memória disponível e eliminando o desperdício interno das partições fixas.
Uma técnica conhecida como paginação revoluciona o gerenciamento de memória ao dividir tanto a memória física quanto o espaço de endereçamento dos processos em páginas de tamanho fixo. Esta técnica permite que processos sejam carregados de forma não-contígua na memória física, resolvendo problemas de fragmentação externa. Nesta técnica o cálculo do endereço físico segue a fórmula:
\[\text{Endereço Físico} = \text{Número da Página} \times \text{Tamanho da Página} + \text{Offset}\]A segmentação oferece uma alternativa ao dividir a memória em segmentos de tamanho variável que correspondem mais naturalmente à estrutura lógica dos programas, com diferentes segmentos contendo código, dados, pilha ou heap.
 Figura 9: Diagrama ilustrativo de paginação e segmentação na memória, mostrando como processos são divididos em páginas e segmentos, com endereços físicos correspondentes.
Figura 9: Diagrama ilustrativo de paginação e segmentação na memória, mostrando como processos são divididos em páginas e segmentos, com endereços físicos correspondentes.
Memória Virtual
O conceito de memória virtual representa uma das inovações mais impactantes no gerenciamento de memória. Esta técnica permite, como vimos antes, que programas maiores que a memória física sejam executados, criando transparentemente a ilusão de abundância de memória por meio de duas estratégias principais. O primeiro é o swapping, que envolve mover processos inteiros entre a memória física e o disco rígido quando necessário. Embora eficaz, o swapping pode introduzir latências significativas durante as transferências, especialmente se os processos forem grandes ou se houver muitos processos ativos simultaneamente.
O segundo é a paginação sob demanda, que refina o conceito de swapping ao carregar apenas as páginas necessárias de um processo na memória física quando elas são realmente requisitadas. Isso minimiza tanto o uso da memória física quanto o tempo de carregamento inicial dos programas, permitindo que sistemas modernos executem dezenas de processos simultaneamente mesmo com quantidades modestas de RAM física.
 Figura 10: Diagrama ilustrativo de paginação e segmentação na memória, mostrando como processos são divididos em páginas e segmentos, com endereços físicos correspondentes.
Figura 10: Diagrama ilustrativo de paginação e segmentação na memória, mostrando como processos são divididos em páginas e segmentos, com endereços físicos correspondentes.
Gerenciamento do Sistema de Arquivos: Organizando Dados Persistentes
Se a compassiva leitora permitir eu vou me referir ao sistema de arquivos como uma das partes mais importantes de um sistema operacional, responsável por organizar, armazenar e recuperar dados persistentes em dispositivos de armazenamento. O gerenciamento do sistemas de arquivos atua como uma ponte entre o hardware de armazenamento e os usuários ou aplicações. Neste contexto, podemos destacar as seguintes funções:
-
Interface de Operações com Arquivos e Diretórios: o sistema de arquivos oferece uma API, Interface de Programação de Aplicações, consistente que permite aos usuários e programas realizarem operações fundamentais. Isso inclui a capacidade de
write,readedeletetanto arquivos quanto diretórios, abstraindo os comandos complexos do hardware de armazenamento em ações simples e padronizadas. -
Organização e Navegação Hierárquica: para organizar os dados de forma intuitiva, os sistemas de arquivos implementam uma estrutura de diretórios em árvore. Nessa estrutura, um diretório raiz contém arquivos e outros subdiretórios, que por sua vez podem conter mais arquivos e subdiretórios. Esse modelo permite que cada arquivo no sistema seja unicamente identificado por seu caminho, path, em inglês, que é a sequência de diretórios desde a raiz até o arquivo.
-
Mapeamento Lógico para Físico: uma das funções centrais do sistema de arquivos é atuar como uma camada de abstração entre a visão lógica de um arquivo, uma sequência contígua de bytes, e sua representação física fragmentada no dispositivo de armazenamento. O sistema de arquivos traduz os nomes e os deslocamentos lógicos de um arquivo para os endereços exatos dos blocos físicos, no inglês:blocks. Em um disco rígido ou SSD, ocultando a complexidade da localização física dos dados.
 Figura 11: Diagrama mostrando como funciona o mapeamento de arquivos, com blocos lógicos e físicos representados.
Figura 11: Diagrama mostrando como funciona o mapeamento de arquivos, com blocos lógicos e físicos representados. -
Gerenciamento de Espaço em Disco: o sistema de arquivos monitora e gerencia todo o espaço de armazenamento disponível. Ele mantém o controle de quais blocos estão em uso, a quais arquivos eles pertencem e quais estão livres para serem alocados. Quando novos dados precisam ser gravados, é o sistema de arquivos que decide quais blocos livres utilizar, otimizando o uso do espaço e, em alguns casos, o desempenho de futuras leituras.
-
Segurança e Controle de Acesso: para garantir a integridade e a confidencialidade dos dados, o sistema de arquivos implementa mecanismos de controle de acesso. Ele associa permissões, como leitura, escrita e execução, a cada arquivo e diretório, verificando a identidade do usuário ou do grupo que tenta realizar uma operação. Dessa forma, ele reforça as políticas de segurança, permitindo ou negando o acesso aos recursos conforme as regras definidas.
Estruturas de Dados Fundamentais
Para implementar essas funções, os sistemas de arquivos utilizam várias estruturas de dados fundamentais:
-
Blocos de Dados: a unidade básica de armazenamento em um sistema de arquivos. Os dados são armazenados em blocos, que são sequências contíguas de bytes. O tamanho do bloco pode variar, mas é geralmente fixo para um determinado sistema de arquivos. Cada bloco é endereçado fisicamente no dispositivo de armazenamento.
-
Metadados do Arquivo: cada arquivo no sistema é acompanhado por um conjunto de informações descritivas, conhecido como metadados. Esses dados, frequentemente armazenados em estruturas como inodes, em sistemas Unix-like, incluem atributos vitais como o tamanho do arquivo, as datas de criação, modificação e último acesso, o proprietário, usuário e grupo, e, fundamentalmente, os ponteiros para os blocos de dados que contêm o conteúdo real do arquivo. As permissões de acesso também são parte dos metadados.
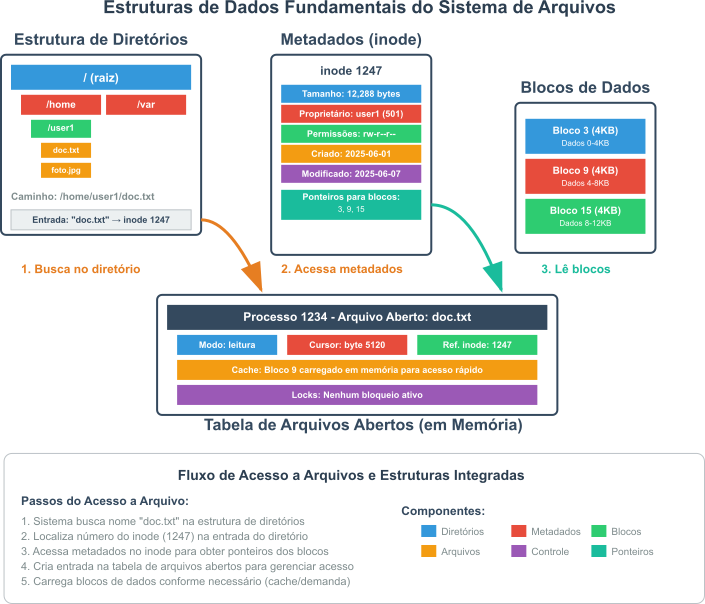 Figura 12: Diagrama mostrando as estruturas de dados fundamentais de um sistema de arquivos, incluindo blocos de dados, metadados e diretórios.
Figura 12: Diagrama mostrando as estruturas de dados fundamentais de um sistema de arquivos, incluindo blocos de dados, metadados e diretórios. -
Estrutura de Diretórios: um diretório é, em si, um tipo especial de arquivo cujo conteúdo consiste em uma lista de nomes de arquivos e referências para os metadados desses arquivos. Quando um programa acessa um arquivo pelo nome, o sistema de arquivos pesquisa nas estruturas de diretório correspondentes para encontrar a entrada daquele nome e, a partir dela, obter a localização dos metadados e, consequentemente, dos dados do arquivo.
-
Tabela de Arquivos Abertos: Para gerenciar os arquivos que estão sendo acessados ativamente, o sistema operacional mantém uma tabela em memória, chamada de tabela de arquivos abertos. Quando um processo abre um arquivo, uma entrada é criada nesta tabela, que armazena informações temporárias como o ponteiro de leitura/escrita, o cursor que indica a posição atual no arquivo, e referências às estruturas de metadados. Isso otimiza o acesso, evitando buscas repetidas no disco para operações subsequentes no mesmo arquivo.
Componentes Principais do Gerenciamento de E/S
Outro sistema importante do sistema operacional é o gerenciamento de Entrada/Saída (E/S), que lida com a comunicação entre o sistema e os dispositivos periféricos, como discos rígidos, impressoras, teclados e redes. O gerenciamento de E/S é a base para garantir que os dados sejam transferidos de forma eficiente entre o hardware e o software, permitindo que os usuários interajam com o sistema e acessem recursos externos. Vamos explorar os principais componentes e técnicas envolvidos no gerenciamento de E/S
-
Drivers de Dispositivo (Device Drivers): o sistema operacional utiliza drivers como uma camada de abstração essencial para a comunicação com o hardware. Cada driver é um software especializado, projetado para um dispositivo específico, como uma placa de vídeo, impressora ou disco rígido, que traduz as requisições genéricas de E/S do sistema operacional em comandos que o hardware consegue entender. Este é um processo de tradução de baixa complexidade, imprimir um arquivo, para um sistema de alta complexidade, todos os detalhes do hardware.
-
Sistema de Interrupções: para evitar que a CPU desperdice tempo verificando constantemente o estado dos dispositivos, processo conhecido em inglês como polling, o sistema utiliza interrupções. Uma interrupção é um sinal enviado pelo hardware para a CPU, informando que um evento que requer atenção ocorreu, como a finalização de uma operação de leitura ou a chegada de dados em uma porta de rede. Ao receber o sinal, a CPU pausa sua tarefa atual, executa uma rotina para tratar o evento, por exemplo, mover os dados recebidos para a memória, e depois retoma seu trabalho. Esse mecanismo permite que a CPU execute outras tarefas enquanto os dispositivos de E/S, que são muito mais lentos, realizam suas operações.
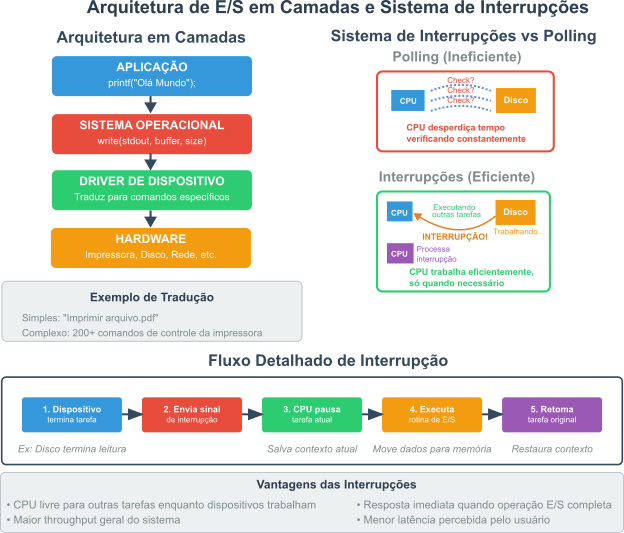 Figura 13: Diagrama mostrando a arquitetura de E/S com interrupções, destacando como a CPU interage com dispositivos e trata interrupções.
Figura 13: Diagrama mostrando a arquitetura de E/S com interrupções, destacando como a CPU interage com dispositivos e trata interrupções.
-
Buffering: O buffering consiste em usar uma área de memória temporária, o buffer, para armazenar dados durante a transferência entre dispositivos com velocidades diferentes. Por exemplo, ao receber dados de uma rede, eles são primeiro acumulados em um buffer na memória principal antes de serem processados pela CPU ou gravados em um disco mais lento. Isso suaviza o fluxo de dados, compensa as diferenças de velocidade e permite transferências em blocos maiores e mais eficientes, em vez de lidar com cada byte individualmente.
-
Caching: O caching é uma técnica de otimização que armazena cópias de dados frequentemente acessados em uma memória mais rápida e próxima à CPU, a memória cache. Quando o sistema precisa ler dados de um dispositivo lento, como um HD, ele primeiro verifica se uma cópia já existe na cache. Se existir, um cache hit, os dados são recuperados instantaneamente, evitando o acesso lento ao dispositivo. Se não existir, um cache miss, os dados são lidos do dispositivo e uma cópia é armazenada na cache para acelerar acessos futuros.
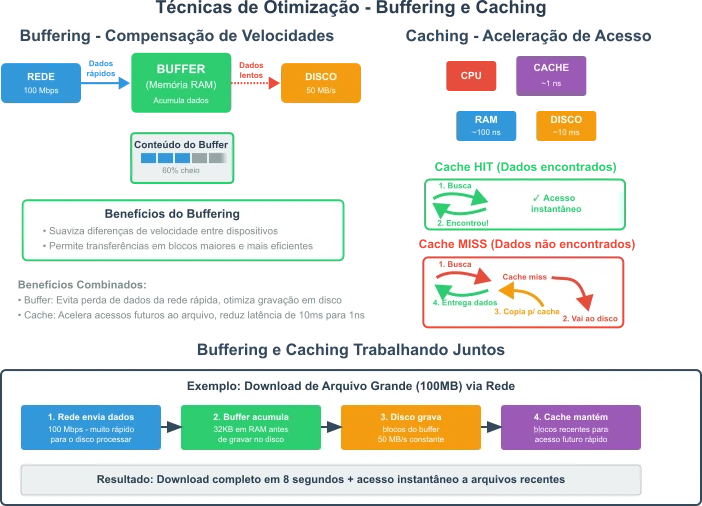 Figura 14: Diagrama mostrando o funcionamento de buffering e caching na E/S, destacando como os dados são armazenados temporariamente para otimizar transferências.
Figura 14: Diagrama mostrando o funcionamento de buffering e caching na E/S, destacando como os dados são armazenados temporariamente para otimizar transferências.
Técnicas de Realização de Entrada/Saída
-
E/S Programada (Programmed I/O - PIO): nesta abordagem, a CPU tem controle total sobre a operação de E/S e fica dedicada a ela. A CPU inicia a requisição e entra em um laço de espera ativa (busy-waiting), consultando repetidamente o registrador de status do dispositivo para saber se a operação foi concluída. Essa técnica é simples de implementar, mas extremamente ineficiente, pois mantém a CPU 100% ocupada com uma única tarefa de E/S, impedindo-a de realizar qualquer outro processamento.
-
E/S Guiada por Interrupção (Interrupt-driven I/O): uma técnica mais eficiente. A CPU inicia a operação de E/S e, em vez de esperar, continua a executar outras tarefas. Quando o dispositivo termina seu trabalho, ele envia um sinal de interrupção para a CPU. A CPU então salva seu contexto atual, executa o código necessário para tratar a interrupção, como por exemplo transferir os dados para memória, e depois retorna à tarefa que estava executando. Isso permite uma espécie de paralelismo funcional entre o processamento da CPU e as operações de E/S, melhorando significativamente a utilização do sistema.
-
Acesso Direto à Memória (em inglês: Direct Memory Access - DMA): para transferências de grandes volumes de dados, o DMA é a técnica mais avançada e eficiente. A CPU delega a operação a um controlador de DMA, um componente de hardware especializado. A CPU informa ao controlador de DMA a localização dos dados, o destino na memória e a quantidade de dados a serem transferidos. O controlador de DMA então gerencia a transferência diretamente entre o dispositivo e a memória principal, sem qualquer envolvimento da CPU. A CPU só é interrompida uma única vez, no final da transferência completa do bloco de dados, o que a libera para executar outras tarefas computacionais durante todo o processo. Neste caso, além do paralelismo entre o processamento e a E/S ser mais eficiente, também é mais rápido removendo da CPU todas as tarefas relacionadas a interface com os dispositivos de armazenamento mais lentos.
Suporte a Redes: Conectividade e Comunicação
A maioria dos Sistemas operacionais fornecem capacidades de rede integradas. Vamos esmiuçar as principais funcionalidades de rede que um sistema operacional deve oferecer:
-
Gerenciamento de Interfaces de Rede: o sistema operacional é responsável por identificar e gerenciar todo o hardware de conectividade, como placas de rede Ethernet, adaptadores Wi-Fi e interfaces virtuais. Essa gestão inclui a ativação e desativação das interfaces, a configuração de parâmetros essenciais como endereços IP, máscaras de sub-rede e gateways, e o monitoramento do tráfego e de possíveis erros, fornecendo uma base estável para toda a comunicação em rede.
-
Implementação de Protocolos de Comunicação: no núcleo de suas funcionalidades de rede, o sistema operacional implementa uma pilha de protocolos, sendo a pilha TCP/IP a mais comum. Essa pilha é formada por um conjunto de camadas de software que define como os dados são formatados, endereçados, transmitidos, roteados e recebidos. Inclui protocolos fundamentais como o IP para o endereçamento e roteamento de pacotes entre redes, o TCP para garantir uma comunicação orientada à conexão e confiável, e o UDP para transmissões rápidas e sem conexão confirmada. O sistema operacaional gerencia todo o ciclo de vida dos pacotes de dados por meio dessas camadas.
Pilha TCP/IP
A pilha TCP/IP é um conjunto de protocolos de comunicação organizados em camadas que permite a interconexão de redes heterogêneas, formando a base da Internet moderna. Este modelo de quatro camadas (Aplicação, Transporte, Internet e Acesso à Rede) foi desenvolvido para ser mais prático que o modelo OSI de sete camadas, focando na implementação real de protocolos. Cada camada possui responsabilidades específicas e se comunica apenas com as camadas adjacentes, criando uma abstração que permite que aplicações utilizem a rede sem conhecer detalhes de baixo nível da transmissão de dados.
A camada de Aplicação hospeda protocolos que interagem diretamente com programas do usuário, incluindo HTTP/HTTPS para navegação web, SMTP para email, FTP para transferência de arquivos, e DNS para resolução de nomes. A camada de Transporte gerencia a comunicação fim-a-fim entre processos, sendo o TCP, do inglês Transmission Control Protocol, responsável por conexões confiáveis com controle de fluxo e detecção de erros, enquanto o UDP, do inglês (User Datagram Protocol, oferece transmissão mais rápida sem garantias de entrega. Esta camada também implementa o conceito de portas, permitindo que múltiplas aplicações compartilhem a mesma conexão de rede.
A camada de Internet (ou Rede) é dominada pelo protocolo IP (Internet Protocol), responsável pelo roteamento de pacotes entre redes diferentes por meio de endereçamento lógico. O IP fornece um serviço de entrega no padrão best-effort sem garantias, delegando confiabilidade para camadas superiores. Protocolos auxiliares como ICMP (para mensagens de controle e erro) e ARP (para resolução de endereços físicos) também operam nesta camada. A camada de Acesso à Rede engloba protocolos de enlace de dados e físicos, como Ethernet para redes locais e Wi-Fi para conexões sem fio, responsáveis pela transmissão real de bits por meio do meio físico.
O sistema operacional implementa a pilha TCP/IP por meio de drivers de rede, buffers de socket e interfaces de programação como Berkeley Sockets API.
-
Compartilhamento de Recursos na Rede: uma das principais vantagens da conectividade é a capacidade que o sistema operacional oferece para compartilhar recursos locais com outros computadores. Isso permite que um sistema atue como um servidor, disponibilizando o acesso a arquivos e diretórios, impressoras, scanners e outros serviços. O sistema operacional controla as permissões de acesso a esses recursos compartilhados, garantindo que apenas usuários e sistemas autorizados possam utilizá-los.
-
Sistemas de Arquivos Distribuídos: esta é uma forma avançada de compartilhamento de recursos que torna o acesso a arquivos remotos transparente para o usuário. Utilizando protocolos como NFS, Network File System, comum em ambientes Unix/Linux, ou SMB/CIFS, Server Message Block, predominante em ambientes Windows, o sistema operacional permite montar um diretório localizado em um servidor remoto como se fosse um diretório local. Dessa forma, os usuários e aplicações podem manipular arquivos remotos usando as mesmas operações e caminhos que usariam para arquivos locais.
-
APIs para Comunicação Remota: o sistema operacional fornece interfaces de programação para que as aplicações possam se comunicar por meio da rede. A mais fundamental delas é a interface de sockets, que representa um ponto final de comunicação. Os programas podem criar sockets para enviar e receber dados usando um protocolo específico, como TCP ou UDP. Em um nível de abstração mais alto, existem mecanismos como o RPC, do inglês Remote Procedure Call, que permitem que um programa execute uma função ou procedimento em outro computador na rede de forma quase idêntica a uma chamada de função local, com o sistema operacional e a biblioteca de RPC cuidando de toda a comunicação de rede subjacente.
Segurança e Proteção: A Dupla Guarda da Integridade do Sistema
Para garantir a confiabilidade e a estabilidade de um sistema computacional, é indispensável distinguir e implementar dois conceitos interligados, mas distintos: proteção e segurança. A atenta leitora deve perceber que, embora frequentemente usados como sinônimos, estes conceitos abordam facetas diferentes do mesmo objetivo geral: resguardar os recursos do sistema.
Proteção: O Controle Interno de Acessos
A proteção refere-se aos mecanismos internos do sistema operacional que controlam o acesso de programas e processos aos recursos do sistema. O objetivo desta estrutra de controle é evitar que um processo interfira indevidamente com outro processo, ou com o próprio sistema operacional, seja por erro ou por intenção maliciosa. A proteção é a muralha que garante a ordem dentro do castelo.
Os mecanismos fundamentais de proteção incluem:
-
Modos de Operação (Dual-Mode Operation): uma das barreiras de proteção mais fundamentais é a distinção entre
user modeekernel mode. O código do sistema operacional executa nokernel mode, também conhecido como modo supervisor ou modo privilegiado, com acesso irrestrito a todo o hardware. As aplicações do usuário, por sua vez, rodam nouser mode, um estado com privilégios limitados. Qualquer operação sensível, como o acesso direto a um dispositivo de hardware, exige uma transição controlada para okernel modepor meio de uma chamada de funções específicas de sistema. -
Proteção de Memória: o sistema operacional deve garantir que cada processo acesse apenas seu próprio espaço de endereçamento. Espaço de endereçamento é o nome que damos a quantidade de memória virtual que foi alocada para um determinado processo. Isso cria uma camada isolamento que impede um processo de ler ou modificar os dados de outro processo ou do próprio kernel, prevenindo corrupção de dados e falhas em cascata. Seja esta leitura feita por erro ou maldade.
-
Proteção de E/S: O acesso a dispositivos de Entrada/Saída é uma operação privilegiada. O sistema operacional gerencia todas as requisições de E/S, impedindo que processos de usuário acessem diretamente o hardware, o que poderia levar a conflitos e instabilidade no sistema.
Segurança: A Defesa Contra Ameaças Externas e Internas
A segurança, por outro lado, lida com a defesa do sistema contra ameaças, tanto externas, como ataques de rede, quanto internas, como usuários mal-intencionados. Enquanto a proteção fornece os mecanismos, a segurança estabelece as políticas para usar esses mecanismos e defender o sistema contra tentativas de burlar as regras do sistema. A segurança é a política que define quem pode entrar no navio e o que pode fazer lá dentro.
As políticas de segurança são implementadas por meio de várias camadas de defesa:
-
Autenticação: o primeiro passo para a segurança é verificar a identidade de um usuário,
authentication. É o processo de responder à pergunta Quem é você?. Isso é comumente realizado por meio de senhas, biometria, tokens de segurança ou outros fatores que comprovem que o usuário é quem ele alega ser. -
Autorização: uma vez que um usuário é autenticado, a autorização,
authorization, determina quais recursos ele pode acessar e que operações pode realizar. É o processo de responder à pergunta O que você pode fazer?. Isso é gerenciado por meio de listas de controle de acesso (ACLs), permissões de arquivo (read,write,execute) e scripts de definição de permissão para usuários e grupos. -
Auditoria: para detectar violações de segurança e analisar incidentes, os sistemas mantêm registros, do inglês
logs, de atividades importantes. A auditoria, do inglêsauditing, envolve a análise desses registros para identificar padrões suspeitos, tentativas de acesso não autorizado ou atividades maliciosas, permitindo uma resposta adequada e o fortalecimento das defesas.
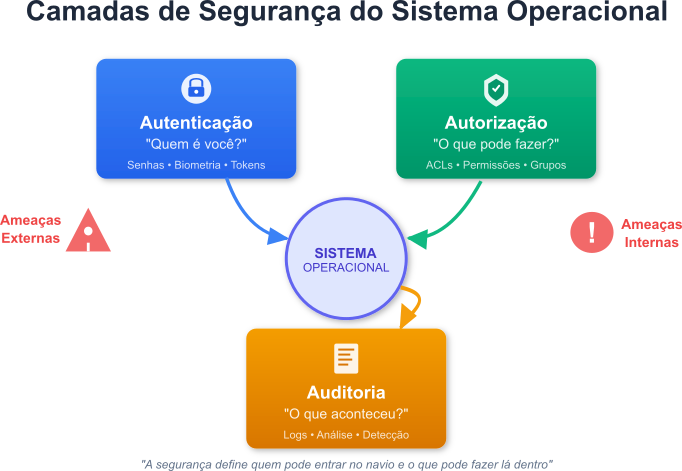 Figura 15: Diagrama mostrando o funcionamento de buffering e caching na E/S, destacando como os dados são armazenados temporariamente para otimizar transferências.
Figura 15: Diagrama mostrando o funcionamento de buffering e caching na E/S, destacando como os dados são armazenados temporariamente para otimizar transferências.
Duas Perspectivas Fundamentais: Compreendendo a Natureza Dual dos Sistemas Operacionais
Para compreender plenamente a natureza e o papel de um sistema operacional, será interessante se a criativa leitora puder considerá-lo sob duas perspectivas distintas, porém complementares: como um gerente de recursos e como uma máquina estendida. Neste caso, usaremos o conceito de máquina estendida para representa uma camada de abstração de hardware.
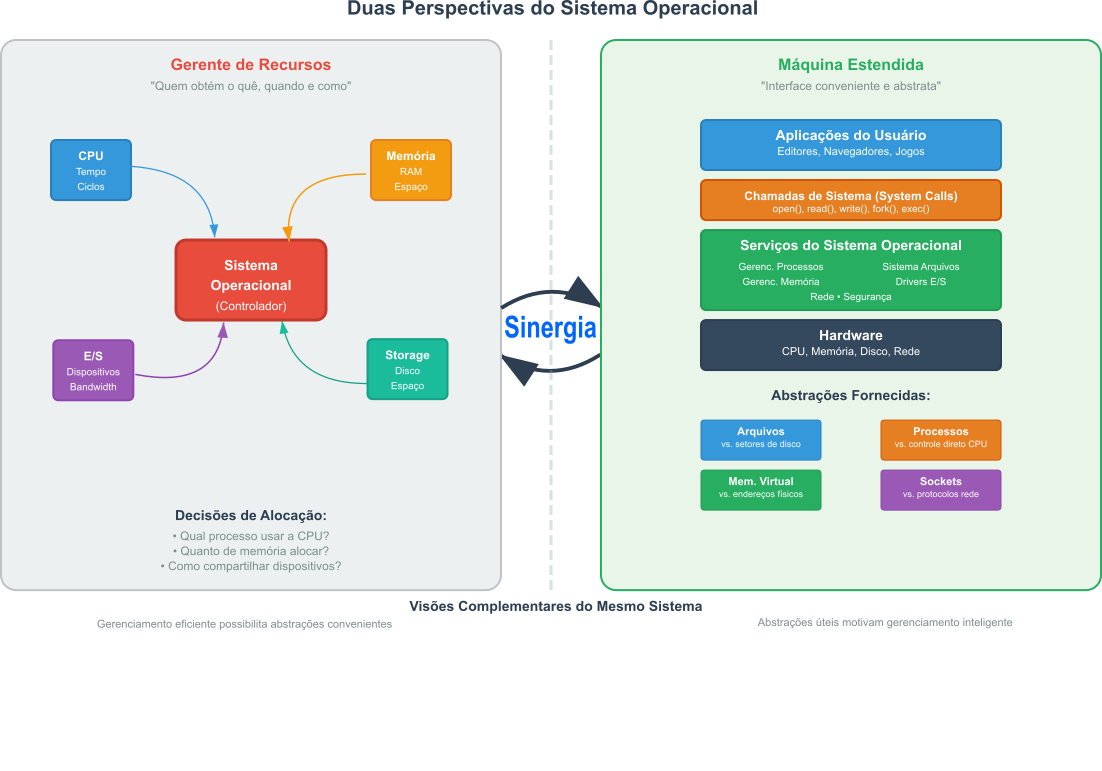 Figura 16: As duas perspectivas fundamentais dos sistemas operacionais - Gerente de Recursos e Máquina Estendida
Figura 16: As duas perspectivas fundamentais dos sistemas operacionais - Gerente de Recursos e Máquina Estendida
O Sistema Operacional como Gerente de Recursos
Na perspectiva centrada no usuário, o sistema operacional atua como um capitão experiente, cuja função primordial é gerenciar e alocar todos os recursos do sistema de forma controlada, eficiente e transparente. A atenta leitora pode imaginar que o sistema operacional atua como um programa de controle e governo, tomando decisões sobre como distribuir recursos escassos entre programas e usuários concorrentes. Em um ambiente formado por múltiplos processos que competem por recursos limitados, o sistema operacional deve agir como um árbitro justo e eficiente, garantindo que todos os processos tenham acesso adequado aos recursos necessários para sua execução.
Esta perspectiva revela uma natureza econômica dos sistemas operacionais: em um mundo de recursos finitos - CPU, memória, dispositivos de E/S e armazenamento - alguém deve decidir quem obtém o quê, quando e por quanto tempo. Esta é a essência da gestão de recursos computacionais.
-
Tempo da CPU: O Recurso Mais Valioso: provavelmente é o tempo de processamento que representa o recurso mais disputado em qualquer sistema computacional. O sistema efetiva o gerenciamento do tempo de processamento usando:
- Algoritmos de escalonamento sofisticados: desde o simples First-Come, First-Served (FCFS) até técnicas avançadas como Completely Fair Scheduler (CFS) do Linux;
- Agendamento de processos com prioridades: permitindo que tarefas críticas recebam precedência;
- Balanceamento de carga: em sistemas multicore, distribuindo processos entre núcleos disponíveis;
- Gerenciamento de threads: coordenando múltiplos fluxos de execução dentro de processos.
-
Espaço na Memória Principal: A Alocação Dinâmica: a memória RAM, volátil, limitada e lenta, requer:
- Alocação dinâmica: atribuindo e liberando blocos de memória conforme necessário;
- Fragmentação: combatendo a fragmentação interna e externa por meio de técnicas como compactação;
- Memória virtual: criando a ilusão de abundância por meio de paginação e segmentação;
- Proteção entre processos: garantindo isolamento e segurança por meio de espaços de endereçamento separados.
-
Espaço em Dispositivos de Armazenamento: A Persistência Organizada: o armazenamento secundário, maior que a memória principal porém muito mais lento que esta, apresenta desafios únicos de organização e acesso:
- Sistema de arquivos hierárquico: organizando dados em estruturas de árvore intuitivas;
- Alocação de blocos: gerenciando espaço livre e ocupado em dispositivos;
- Cache de disco: mantendo dados frequentemente acessados em memória para acelerar operações;
- Journaling: garantindo consistência e recuperação após falhas.
-
Dispositivos de Entrada/Saída: A Interface com o Mundo Exterior: os dispositivos periféricos requerem coordenação especializada:
- Drivers especializados: software que traduz comandos genéricos em instruções específicas de hardware;
- Filas de requisições: ordenando e priorizando operações de E/S;
- Buffering e spooling: otimizando transferências por meio de armazenamento temporário;
- Gerenciamento de interrupções: respondendo eficientemente a eventos de hardware.
Tarefas Fundamentais do Gerente de Recursos
Agora que nomeamos os principais recursos computacionais sobre a atenção do nosso capitão, podemos criar uma lista de tarefas que o sistema operacional, em seu papel de gerente de recursos, deve executar:
-
Monitoramento Contínuo: A Vigilância Constante: o sistema operacional deve manter vigilância constante sobre o estado e utilização de todos os recursos. Esta função inclui:
- Métricas em tempo real: coleta de dados sobre utilização de CPU, memória, disco e rede;
- Detecção de gargalos: identificação de recursos que se tornam limitantes ao desempenho;
- Accounting: registro detalhado de uso para auditoria e cobrança;
- Health monitoring: verificação da integridade de hardware e software.
# Exemplo de monitoramento em Linux $ top -p $(pgrep processo) $ iostat -x 1 $ vmstat 1 $ sar -u 1 5 -
Políticas de Alocação: A Sabedoria da Distribuição: as decisões sobre quem obtém qual recurso e quando constituem o coração da gestão de recursos. Estas políticas devem equilibrar:
- Eficiência: maximizar a utilização global dos recursos;
- Justiça: garantir que todos os processos recebam tratamento equitativo;
- Prioridade: atender necessidades críticas primeiro;
- Responsividade: manter o sistema responsivo para usuários interativos.
A implementação dessas políticas frequentemente envolve algoritmos matemáticos sofisticados. Por exemplo, o algoritmo Shortest Job First (SJF) minimiza o tempo médio de espera segundo a fórmula:
\[\text{Tempo Médio de Espera} = \frac{1}{n} \sum_{i=1}^{n} W_i\]na qual, $W_i$ representa o tempo de espera do processo $i$.
-
Recuperação e Reciclagem: O Ciclo da Reutilização: a liberação eficiente de recursos após o uso é indispensável para manter a saúde do sistema:
- Garbage collection: recuperação automática de memória não utilizada;
- Resource cleanup: liberação de handles, sockets e outras abstrações;
- Deadlock resolution: quebra de situações de bloqueio circular;
- Orphan process handling: limpeza de processos abandonados.
Exemplo Detalhado: A Coordenação do Escalonamento de CPU
Vamos tentar entender a complexidade da gestão de recursos, considerando o escalonamento de CPU em detalhes:
Fila de Processos Prontos:
┌─────────────────────────────────────────┐
│ Processo A (Prioridade: 10, Tempo: 5ms) │
│ Processo B (Prioridade: 15, Tempo: 3ms) │ ──→ Escalonador ──→ CPU
│ Processo C (Prioridade: 8, Tempo: 8ms) │ ↓
│ Processo D (Prioridade: 12, Tempo: 2ms) │ Política de
└─────────────────────────────────────────┘ Escalonamento
Os escalonadores modernos implementam múltiplas políticas simultaneamente:
As políticas de prioridade dinâmica formam a espinha dorsal do escalonamento moderno. O mecanismo de aging garante que processos que esperam mais tempo recebam prioridade crescente, evitando situações de inanição nos quais processos de baixa prioridade nunca conseguem executar. Complementarmente, o interactive bonus reconhece que processos interativos devem receber tratamento preferencial para manter a responsividade do sistema, enquanto a CPU-bound penalty reduz a prioridade de processos que consomem intensivamente a CPU, permitindo que outros processos tenham oportunidade de execução.
A implementação de algoritmos de justiça busca garantir distribuição equitativa dos recursos computacionais. O Completely Fair Scheduler (CFS) do Linux exemplifica essa abordagem ao assegurar que todos os processos recebam uma fatia justa de CPU baseada em suas necessidades e prioridades. O proportional share scheduling refina este conceito por meio da alocação baseada em pesos específicos atribuídos aos processos, enquanto o lottery scheduling introduz um elemento probabilístico na seleção. Neste algoritmo processos recebem tickets e a seleção ocorre por meio de sorteio ponderado.
Para maximizar o desempenho do sistema, diversas otimizações de eficiência são implementadas simultaneamente. A minimização de context switches agrupa operações relacionadas para reduzir o custo associado à troca de contexto entre processos. A cache affinity explora a localidade temporal ao preferir executar processos no mesmo núcleo em que executaram anteriormente, aproveitando dados ainda presentes no cache. Em sistemas multiprocessador, o load balancing distribui inteligentemente a carga de trabalho entre núcleos disponíveis, evitando situações nas quais alguns núcleos ficam sobrecarregados enquanto outros permanecem ociosos.
A complexidade deste sistema pode ser expressa matematicamente. Para um sistema com $n$ processos, a utilização da CPU pode ser modelada como:
\[U = \sum_{i=1}^{n} \frac{C_i}{T_i}\]na qual $C_i$ é o tempo de computação e $T_i$ é o período do processo $i$.
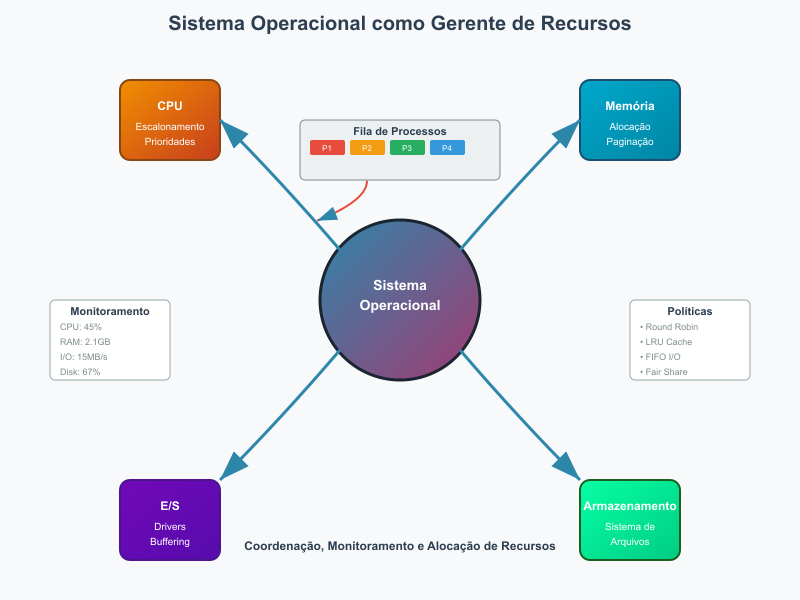 Figura 17: O sistema operacional como gerente de recursos
Figura 17: O sistema operacional como gerente de recursos
Métricas de Avaliação da Gestão de Recursos
Usamos métricas para avaliar a eficácia da gestão de recursos, permitindo que o sistema operacional ajuste suas políticas e algoritmos para otimizar o desempenho. As principais métricas incluem:
| Métrica | Definição | Fórmula | Objetivo |
|---|---|---|---|
| Throughput | Jobs completados por unidade de tempo | $\frac{\text{Jobs completados}}{\text{Tempo total}}$ | Maximizar |
| Turnaround Time | Tempo total desde submissão até conclusão | $T_{\text{término}} - T_{\text{chegada}}$ | Minimizar |
| Response Time | Tempo até primeira resposta | $T_{\text{primeira resposta}} - T_{\text{chegada}}$ | Minimizar |
| CPU Utilization | Percentual de tempo que CPU está ocupada | $\frac{T_{\text{CPU ativa}}}{T_{\text{total}}} \times 100\%$ | Maximizar |
| Waiting Time | Tempo em filas de espera | $T_{\text{turnaround}} - T_{\text{execução}}$ | Minimizar |
A tensão entre estas métricas exemplifica os trade-offs inerentes à gestão de recursos. Maximizar throughput pode conflitar com minimizar response time, exigindo que o sistema operacional encontre um equilíbrio baseado nas necessidades específicas do ambiente de execução.
A Complexidade Emergente da Gestão de Recursos
À medida que os sistemas se tornam mais complexos - com múltiplos núcleos, arquiteturas NUMA (Non-Uniform Memory Access), dispositivos heterogêneos e cargas de trabalho dinâmicas - a tarefa de gestão de recursos transcende algoritmos simples. Sistemas modernos empregam:
- Aprendizado de máquina: para predizer padrões de uso e otimizar alocações;
- Feedback loops: ajuste dinâmico de políticas baseado em performance observada;
- Hierarquias de escalonamento: múltiplos níveis de decisão para diferentes tipos de recursos;
- Quality of Service (QoS): garantias de desempenho para aplicações críticas.
Esta visão do sistema operacional como gerente de recursos revela sua natureza econômica e política. A esperta leitora deve ter percebido que Não se trata apenas de tecnologia, mas de governança digital - estabelecer e aplicar regras que determinem como recursos escassos são distribuídos entre demandas concorrentes, sempre buscando o equilíbrio entre eficiência, justiça e responsividade.
O Sistema Operacional como Máquina Estendida: A Arte da Abstração Computacional
Sob uma perspectiva complementar, o sistema operacional emerge como uma entidade que fornece uma interface mais simples, limpa e poderosa do que a oferecida diretamente pelo hardware bruto. A perspicaz leitora deve se esforçar para compreender que esta visão revela a natureza fundamentalmente transformadora dos sistemas operacionais: os sistemas operacionais não apenas gerenciam recursos, mas transformam a complexidade técnica em elegância operacional.
O estudo desta abordagem permite reconhecer que o hardware, em sua forma mais primitiva, apresenta uma interface hostil, desafiadora e fragmentada. Uma interface composta de registradores numerados, endereços de memória física, setores de disco identificados por cilindros e cabeças de leitura, protocolos de rede em camadas. Uma complexidade inevitável que o sistema operacional esconde atrás de abstrações elegantes e intuitivas.
Neste cenário, o sistema operacional atua como um tradutor universal, criando uma hierarquia de abstrações que transforma a complexidade técnica em simplicidade conceitual:
┌─────────────────────────────────────────┐
│ Aplicações │ ← Interface Amigável
├─────────────────────────────────────────┤
│ Sistema Operacional │ ← Camada de Abstração
│ (Chamadas de Sistema) │
├─────────────────────────────────────────┤
│ Hardware │ ← Complexidade Técnica
└─────────────────────────────────────────┘
Cada camada desta hierarquia esconde a complexidade da camada inferior, oferecendo uma interface progressivamente mais conveniente e conceptualmente mais rica para a camada superior. Esta estratificação não é meramente organizacional, mas representa uma transformação fundamental da natureza da interação computacional.
As Abstrações Fundamentais: Transformando Complexidade em Elegância
Arquivos e Diretórios: A Metáfora da Organização Humana
A abstração de arquivos representa talvez a transformação mais elegante realizada pelo sistema operacional. Em vez de forçar usuários a manipular setores, trilhas, cilindros e cabeças de leitura, o sistema operacional apresenta a metáfora familiar de documentos organizados em pastas hierárquicas.
Esta abstração oculta uma complexidade extraordinária. Quando um programa executa uma operação aparentemente simples como read("documento.txt", buffer, 1024), o sistema operacional deve:
- Resolver o nome do arquivo: navegar pela estrutura hierárquica de diretórios para localizar os metadados do arquivo;
- Traduzir offset lógico para localização física: converter a posição no arquivo para endereços específicos de setores no disco;
- Gerenciar cache: verificar se os dados solicitados já estão em memória antes de acessar o dispositivo;
- Coordenar acesso concorrente: garantir consistência quando múltiplos processos acessam o mesmo arquivo;
- Lidar com fragmentação: reunir dados que podem estar fisicamente dispersos em diferentes áreas do disco.
A matemática subjacente a esta transformação pode ser expressa como uma função de mapeamento:
\[f: \text{(arquivo, offset)} \rightarrow \text{(dispositivo, setor, posição)}\]neste caso, o sistema operacional implementa esta função complexa de forma transparente para o usuário.
Processos: A Ilusão da Máquina Dedicada
A abstração de processos cria a ilusão de que cada programa possui uma máquina computacional dedicada e exclusiva. Em vez de expor o controle direto dos registradores da CPU, modos de operação e mecanismos de interrupção, o sistema operacional apresenta uma interface na qual programas simplesmente executam.
Esta abstração encapsula sofisticados mecanismos de virtualização:
- Contexto de execução: cada processo mantém um estado completo incluindo registradores, contador de programa e pilha de execução;
- Espaço de endereçamento virtual: cada processo acredita ter acesso exclusivo a toda a memória disponível;
- Scheduling transparente: processos são multiplexados na CPU sem conhecimento explícito desta concorrência;
- Isolamento de proteção: processos não podem interferir uns com os outros acidentalmente.
O custo computacional da troca de contexto entre processos pode ser modelado como:
\[T_{\text{context switch}} = T_{\text{save state}} + T_{\text{load state}} + T_{\text{cache miss penalty}}\]na qual, o sistema operacional otimiza cada componente desta equação para minimizar custos computacionais.
Memória Virtual: A Expansão do Possível
A memória virtual representa uma das abstrações mais sofisticadas, criando a ilusão de abundância em um mundo de escassez. Em vez de forçar programadores a gerenciar endereços físicos limitados, o sistema operacional oferece espaços de endereçamento vastos e aparentemente ilimitados.
Esta transformação envolve múltiplas camadas de tradução:
\[\text{Endereço Virtual} \xrightarrow{\text{MMU}} \text{Endereço Físico}\]A Memory Management Unit (MMU) implementa esta tradução por meio de estruturas hierárquicas de página:
Endereço Virtual (32-bit):
┌──────────────┬──────────────┬──────────────┐
│ Page Dir │ Page Table │ Offset │
│ (10 bits) │ (10 bits) │ (12 bits) │
└──────────────┴──────────────┴──────────────┘
↓ ↓ ↓
Directory Table Entry Posição na
Index Index Página
A eficácia desta abstração pode ser quantificada por meio da taxa de acertos na TLB (Translation Lookaside Buffer):
\[\text{Hit Rate} = \frac{\text{TLB Hits}}{\text{TLB Hits + TLB Misses}}\]na qual valores típicos excedem 99%, demonstrando a eficiência desta abstração em sistemas reais.
Sockets: A Transparência da Comunicação Distribuída
A abstração de sockets universaliza a comunicação, transformando a complexidade dos protocolos de rede em operações familiares de leitura e escrita. Em vez de programar diretamente controladores de rede, configurar pilhas de protocolos e gerenciar buffers de transmissão, programas simplesmente “conversam” por meio de sockets.
Esta abstração oculta a complexidade da pilha TCP/IP:
Aplicação: write(socket, "Hello", 5)
↓
Socket Layer: Buffer management
↓
TCP Layer: Segmentação, controle de fluxo
↓
IP Layer: Roteamento, fragmentação
↓
Link Layer: Frame encoding, MAC addressing
↓
Physical: Transmissão elétrica/óptica
A transparência desta abstração permite que uma simples operação send(socket, data, length, flags) resulte em comunicação confiável por meio de continentes, ocultando toda a complexidade da infraestrutura de rede global.
Exemplo Detalhado: A Simplicidade Aparente da Operação de Arquivo
Para ilustrar a profundidade da abstração, consideremos a aparente simplicidade da operação:
int fd = open("relatorio.pdf", O_RDONLY);
ssize_t bytes = read(fd, buffer, 4096);
close(fd);
Esta sequência de três linhas de código oculta uma cascata de operações complexas:
Fase de Abertura (open):
- Resolução de caminho: o sistema navega por meio da hierarquia de diretórios, potencialmente atravessando múltiplos pontos de montagem e sistemas de arquivos;
- Verificação de permissões: consulta a matriz de controle de acesso para validar se o processo possui direitos adequados;
- Alocação de descritor: reserva uma entrada na tabela de arquivos abertos do processo;
- Inicialização de metadados: carrega informações sobre o arquivo incluindo tamanho, timestamps e localização física.
Fase de Leitura (read):
- Validação de parâmetros: verifica se o descritor é válido e o buffer é acessível;
- Tradução de offset: converte a posição lógica no arquivo para endereços físicos no dispositivo;
- Gerenciamento de cache: consulta o buffer cache para verificar se os dados já estão em memória;
- Operação de E/S: se necessário, programa o controlador de disco para transferir dados;
- Sincronização: coordena com outros processos que possam estar acessando o mesmo arquivo;
- Atualização de metadados: modifica timestamps de último acesso.
Fase de Fechamento (close):
- Liberação de recursos: remove a entrada da tabela de arquivos abertos;
- Flush de dados: garante que modificações pendentes sejam escritas no dispositivo;
- Liberação de locks: remove travas que o processo possa ter sobre o arquivo.
Esta complexidade pode ser quantificada por meio do número de operações de sistema subjacentes:
\[N_{\text{ops}} = N_{\text{directory traversal}} + N_{\text{permission checks}} + N_{\text{disk I/O}} + N_{\text{cache operations}}\]na qual valores típicos podem variar de dezenas a centenas de operações individuais para uma simples leitura de arquivo.
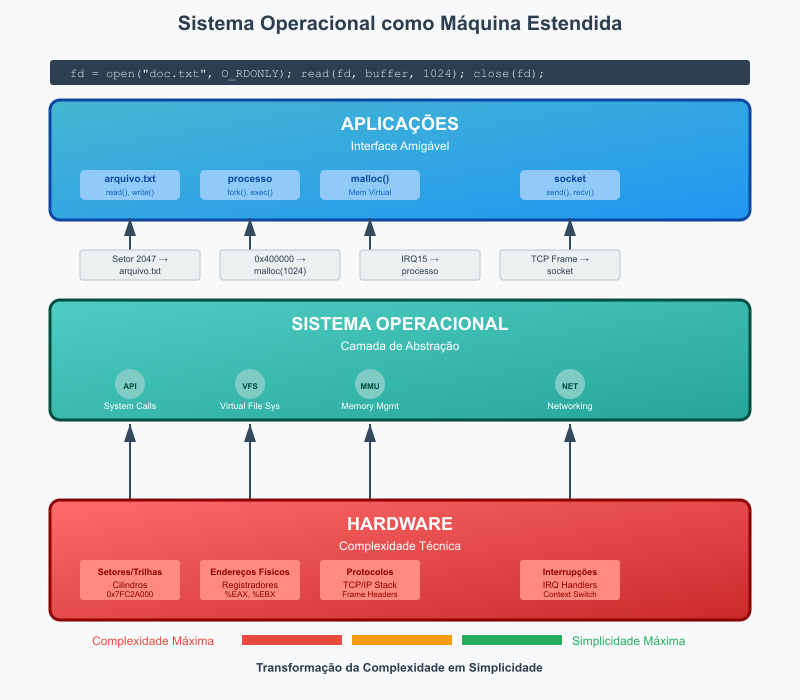 Figura 18: O sistema operacional como máquina estendida. Uma camada de abstração extra tornando a interação com o hardware mais simples
Figura 18: O sistema operacional como máquina estendida. Uma camada de abstração extra tornando a interação com o hardware mais simples
O Princípio da Transparência Progressiva
A eficácia do sistema operacional como máquina estendida baseia-se no princípio da transparência progressiva: cada camada de abstração deve ser suficientemente rica para ocultar a complexidade subjacente, mas suficientemente eficiente para não introduzir custos computacionais proibitivos.
Esta tensão pode ser expressa matematicamente por meio da relação eficiência-abstração:
\[E = \frac{F_{\text{funcionalidade} } }{C_{\text{overhead } } } \times T_{\text{transparência} }\]na qual $E$ representa a eficácia da abstração, $F$ a funcionalidade fornecida, $C$ o custo computacional introduzido, e $T$ o grau de transparência alcançado.
A Revolução Conceitual da Abstração
O sistema operacional como máquina estendida representa mais que uma convenção técnica - constitui uma revolução conceitual na forma como interagimos com sistemas computacionais. Ao transformar a complexidade técnica em simplicidade conceitual, o sistema operacional democratiza o poder computacional, tornando-o acessível não apenas a especialistas em hardware, mas a qualquer pessoa capaz de compreender metáforas familiares como arquivos, pastas e documentos.
Esta transformação não é meramente cosmética. Ela fundamentalmente altera a natureza do que significa programar e utilizar computadores, elevando o nível de discurso da manipulação de bits e registradores para a manipulação de conceitos e abstrações significativas.
Como um farol que torna navegável um litoral rochoso e perigoso, o sistema operacional ilumina e simplifica a paisagem computacional, permitindo que navegadores de todos os níveis de experiência explorem com segurança as vastas possibilidades do mundo digital.
Objetivos Orientadores: Os Princípios Fundamentais que Moldam o Design de Sistemas Operacionais
O projeto de um sistema operacional transcende a implementação técnica, constituindo-se como uma aplicação da arte de equilibrar objetivos frequentemente conflitantes. Estes conflitos determinam as escolhas arquiteturais e a filosofia que governam a interação entre usuários, aplicações e hardware. A perspicaz leitora deve imaginar que estes objetivos emergem da necessidade prática de criar sistemas que sejam simultaneamente poderosos e amigáveis, eficientes e confiáveis, simples e funcionais, versáteis e seguros.
Estes princípios servem como faróis que guiam os arquitetos de sistemas operacionais por meio do complexo território de decisões de design. Da mesma forma como faróis guiam barcos entre as rochas. Nos dois casos, cada escolha tem implicações profundas no desempenho, usabilidade, segurança e evolução do sistema resultante.
Conveniência para o Usuário: A Arte da Simplicidade Aparente
O primeiro e talvez mais fundamental objetivo no design de sistemas operacionais é proporcionar conveniência para o usuário, transformando a complexidade inerente dos sistemas computacionais em experiências fluidas e intuitivas.
O sistema operacional deve atuar como um tradutor universal, convertendo as intenções humanas em ações computacionais precisas. Esta tradução manifesta-se por meio de múltiplas camadas de abstração que, coletivamente, criam a ilusão de simplicidade sobre uma fundação de complexidade extraordinária.
A implementação da facilidade de uso começa com as interfaces com o usuário que devem ser amigáveis. Um conceito subjetivo, mas que todo mundo sabe o que significa. As interfaces amigáveis representam a face mais visível das preocupações com a facilidade de uso. seja por meio de interfaces gráficas de usuário (GUIs) que utilizam metáforas familiares como janelas e pastas, shells de comando que oferecem linguagens naturais para interação com o sistema, ou comandos intuitivos que espelham ações do mundo físico. A interface do usuário deve ser projetada para minimizar a curva de aprendizado, permitindo que usuários novos e experientes interajam com o sistema de forma eficiente e sem frustrações.
Além da interface, uma documentação clara constitui outro pilar fundamental da preocupação com a facilidade de uso. Aqui, a leitora há de me perdoar, estou incluindo não apenas manuais técnicos detalhados, mas sistemas de ajuda integrados que fornecem assistência contextual, e tutoriais que guiam usuários novatos por meio de um conjunto de tarefas que sejam comuns e frequentes.
Finalmente, não é raro que sejam incluídas ferramentas de produtividade para completar o ecossistema de conveniência e facilidade de uso. Neste caso, os sistemas operacionais costumam fornecer editores que compreendem e antecipam as necessidades dos usuários, compiladores que transformam linguagens de alto nível em código executável, e depuradores que auxiliam na identificação e correção de problemas de software. Um conjunto de ferramentas diversas e que podem ser adicionadas de acordo com a necessidade do usuário, mas que não são obrigatórias para o uso do sistema operacional.
Abstração de Complexidade: O Véu da Simplicidade
A verdadeira arte dos sistemas operacionais reside na capacidade de esconder detalhes técnicos desnecessários sem sacrificar funcionalidade ou controle quando necessário. Esta abstração opera por meio de múltiplos mecanismos coordenados.
As operações de alto nível permitem que usuários realizem tarefas complexas por meio de comandos simples, eliminando a necessidade de controle direto de hardware. Por exemplo, o comando aparentemente simples copy arquivo.txt destino/ oculta operações complexas de leitura de metadados, alocação de buffers, transferência de dados e atualização de estruturas de diretório. Que devem estar ocultas do usuário médio e, por outro lado, devem ser claras para o usuário desenvolvedor ou administrador.
O uso contínuo de sistemas operacionais permite perceber que existe um conjunto de tarefas que deve ser realizado com frequência. Neste ponto, a automatização assume a responsabilidade por estas tarefas repetitivas que tradicionalmente exigiriam intervenção manual constante, desde o gerenciamento de memória até a otimização de desempenho. Muitas destas tarefas hoje, são automatizadas e transparentes, sendo acessíveis apenas por estatísticas ou para usuários desenvolvedores. Por fim, um processo de configuração simplificada reduz a barreira de entrada para novos usuários, oferecendo instalação e manutenção facilitadas por meio de assistentes automatizados e configurações padrão inteligentes. A ideia é que seja simples e pouco demorado, instalar e configurar o sistema operacional, permitindo que usuários iniciantes possam começar a trabalhar rapidamente.
Sem dúvidas a simplicidade é um objetivo importante. A eficiência na utilização de recursos representa o segundo objetivo que precisamos estudar, refletindo a realidade econômica de que recursos computacionais, embora abundantes pelos padrões históricos, permanecem finitos e custosos. A leitora atenta deve compreender que a eficiência não é apenas uma questão de desempenho, mas uma questão de sustentabilidade e viabilidade econômica. Sistemas operacionais devem ser projetados para maximizar o uso de recursos disponíveis, minimizando desperdícios e otimizando o desempenho geral.
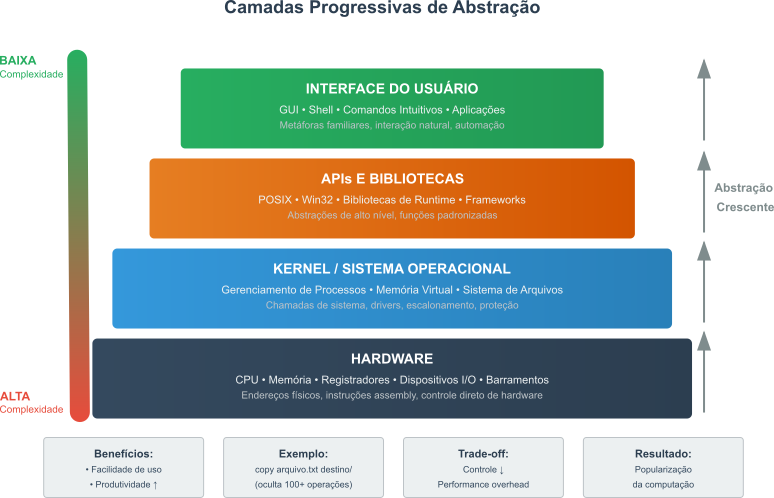 Figura 19: As camadas típicas de abstração do sistema operacional ordenadas de acordo com a complexidade, da menor para a maior.
Figura 19: As camadas típicas de abstração do sistema operacional ordenadas de acordo com a complexidade, da menor para a maior.
Otimização de Desempenho: Maximizando o Potencial do Sistema
A otimização de desempenho constitui uma ciência multifacetada que equilibra múltiplas métricas frequentemente conflitantes. Existem duas métricas principais que devem ser consideradas: o throughput máximo busca maximizar a quantidade de trabalho completado por unidade de tempo, uma métrica particularmente importante em ambientes de processamento em lote ou servidores de alto volume; O tempo de resposta mínimo prioriza a responsividade para sistemas interativos, garantindo que usuários não experimentem latências perceptíveis em suas interações. Estas métricas permitem determinar uma utilização equilibrada dos recursos. O sistema operacional busca coordenar CPU, memória e dispositivos de E/S para que trabalhem harmoniosamente, evitando gargalos. Pontos de operação nos quais um componente permanece ocioso enquanto outros estão saturados.
Na verdade, atenta leitora, a medição precisa da eficiência requer métricas quantitativas rigorosas que permitam comparações objetivas e otimizações dirigidas por dados. Por exemplo, a utilização da CPU pode ser expressa matematicamente como:
\[\text{Utilização da CPU} = \frac{\text{Tempo Útil de CPU} }{\text{Tempo Total} } \times 100\%\]nessa equação, o numerador representa o tempo durante o qual a CPU executa instruções produtivas, excluindo períodos de espera ou idle.
Apenas a utilização da CPU, ainda que importante, não é suficiente para permitir a análise da eficiência do sistema. O throughput do sistema, por sua vez, é quantificado por meio da relação:
\[\text{Throughput} = \frac{\text{Número de Jobs Completados} }{\text{Tempo Total} }\]O throughput do sistema fornece uma medida direta da produtividade do sistema. Ainda assim, esta métrica deve ser interpretada em conjunto com outras métricas para fornecer uma visão completa do desempenho.
A Complexidade das Métricas de Desempenho
A atenta leitora deve observar que métricas isoladas podem ser enganosas. Um sistema pode exibir alta utilização de CPU mas baixo throughput se estiver executando tarefas ineficientes, ou pode demonstrar excelente throughput para cargas de trabalho específicas mas resposta inadequada para tarefas interativas. A arte da otimização reside em compreender estas nuances e otimizar para o perfil de uso específico do sistema.
Capacidade de Evolução e Adaptação: Construindo para o Futuro
O terceiro objetivo fundamental reconhece que sistemas operacionais devem ser projetados não apenas para as necessidades atuais, mas para evoluir conforme novas tecnologias emergem e requisitos mudam. Esta capacidade de evolução determina a longevidade e relevância de um sistema operacional ao longo do tempo. Começando com a modularidade, que permite que componentes individuais sejam atualizados ou substituídos sem afetar o sistema como um todo, até a escalabilidade, que garante que o sistema possa crescer em resposta a demandas crescentes.
O design modular constitui a espinha dorsal da capacidade de evolução de qualquer sistema, permitindo que sistemas complexos sejam modificados e estendidos sem requerer reconstrução completa. Reduzindo os custos e tempos envolvidos na evolução. Esta abordagem manifesta-se por meio de interfaces bem definidas entre componentes do sistema, criando contratos de comunicação e interface claros que permitem a substituição ou atualização de módulos individuais sem afetar outros componentes. Isso permite que novos recursos sejam adicionados ou que componentes obsoletos sejam removidos sem comprometer a estabilidade do sistema. Esta modularidade é facilitada com a separação de política e mecanismo, neste cenário a lógica de controle (política) é separada da implementação técnica (mecanismo). Por exemplo, o sistema de arquivos pode ser implementado como um módulo separado que pode ser atualizado independentemente do núcleo do sistema operacional.
A separação de política e mecanismo oferece flexibilidade adicional, permitindo que a funcionalidade central (mecanismo) permaneça estável enquanto as políticas de uso podem ser ajustadas para diferentes ambientes ou requisitos. Os drivers carregáveis para dispositivos específicos, exemplificam esta filosofia, fornecendo suporte dinâmico para novo hardware sem requerer modificações no kernel principal.
Escalabilidade: Crescendo com as Demandas
A escalabilidade representa a capacidade de um sistema crescer em resposta ao aumento da demanda, seja em termos de processamento, memória, armazenamento ou número de usuários. Esta capacidade manifesta-se por meio do suporte a múltiplos processadores, incluindo arquiteturas SMP, do inglês: Symmetric Multiprocessing, e NUMA, do inglês Non-Uniform Memory Access, permitindo que sistemas aproveitem o poder da computação paralela disponível no hardware e na infraestrutura modernos.
O gerenciamento de grandes volumes de memória por meio de endereçamento de 64 bits, ou mais, remove limitações artificiais que poderiam restringir aplicações futuras. O suporte a sistemas distribuídos, incluindo clusters e computação em nuvem, permite que sistemas operacionais gerenciem recursos que transcendem máquinas físicas individuais.
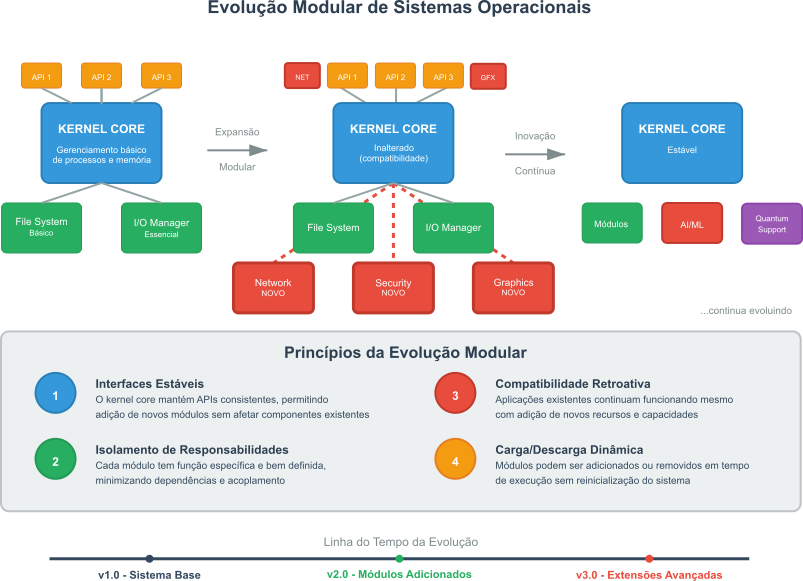 Figura 20: O Kernel do sistema operacional permite a evolução usando apis padronizadas e a possibilidade inclusão de novos módulos, drivers e interfaces.
Figura 20: O Kernel do sistema operacional permite a evolução usando apis padronizadas e a possibilidade inclusão de novos módulos, drivers e interfaces.
Confiabilidade e Tolerância a Falhas: Garantindo a Estabilidade
O quarto objetivo fundamental reconhece que sistemas operacionais devem operar confiavelmente mesmo diante de falhas de hardware, software ou condições ambientais adversas.
Robustez: A Arte de Falhar Graciosamente
A robustez de um sistema manifesta-se não na ausência de falhas, mas na capacidade de lidar com erros de forma graciosa e transparente para os usuários. A detecção de falhas implementa múltiplas técnicas, incluindo monitoramento contínuo de componentes do sistema, checksums para verificação de integridade de dados, e timeouts para identificar componentes que não respondem dentro de parâmetros esperados.
Os mecanismos de recuperação incluem técnicas sofisticadas como rollback para estados anteriores conhecidamente válidos, restart automático de componentes falhos, e failover para sistemas redundantes. O isolamento garante que falhas localizadas não se propaguem por meio do sistema, contendo danos e preservando a funcionalidade de componentes não afetados.
Integridade de Dados: O Fundamento da Confiança
A integridade de dados constitui a base sobre a qual toda confiabilidade é construída, garantindo que informações permaneçam consistentes e duráveis ao longo do tempo. As transações implementam operações atômicas que ou completam inteiramente ou não produzem efeito algum, prevenindo estados intermediários inconsistentes.
Os backups automáticos fornecem proteção contra perda de dados por meio de cópias redundantes, enquanto a verificação de integridade utiliza técnicas como checksums e ECC memory para detectar e corrigir corrupção de dados.
Trade-offs Inevitáveis: A Arte do Compromisso
A realidade do design de sistemas operacionais é que objetivos louváveis frequentemente entram em conflito direto, exigindo compromissos cuidadosamente calibrados que refletem as prioridades e contexto de uso específicos do sistema.
Segurança versus Desempenho: O Dilema Fundamental
A tensão entre segurança e desempenho exemplifica os trade-offs inerentes ao design de sistemas. Verificações de segurança introduzem custos computacionais extras mensuráveis. Cada operação deve ser validada contra políticas de acesso. A criptografia, embora essencial para proteger dados, consome recursos computacionais significativos para operações de cifragem e decifragem. O isolamento rigoroso entre processos, fundamental para segurança, pode limitar compartilhamento eficiente de recursos que poderia melhorar o desempenho global.
Simplicidade versus Funcionalidade: O Paradoxo da Completude
A adição de recursos aumenta inevitavelmente a complexidade do sistema, criando uma tensão fundamental entre simplicidade e funcionalidade. Interfaces simples podem limitar funcionalidade avançada necessária para usuários especialistas, enquanto a configuração automática, que simplifica o uso para novatos, pode conflitar com a necessidade de controle manual preciso para administradores experientes.
Portabilidade versus Otimização: O Conflito de Eficiência
Código específico para hardware frequentemente oferece desempenho superior, mas limita a portabilidade entre diferentes arquiteturas. Abstrações genéricas facilitam a portabilidade mas podem introduzir custos computacionais que reduzem a eficiência. APIs padronizadas promovem compatibilidade mas podem impedir o aproveitamento de recursos únicos específicos de certas plataformas.
| Trade-off | Benefício A | Benefício B | Implicação do Compromisso |
|---|---|---|---|
| Segurança vs. Desempenho | Proteção robusta | Execução rápida | Verificações introduzem latência |
| Simplicidade vs. Funcionalidade | Facilidade de uso | Recursos avançados | Complexidade crescente da interface |
| Portabilidade vs. Otimização | Compatibilidade ampla | Desempenho máximo | Abstrações reduzem eficiência |
Tabela: Principais trade-offs no design de sistemas operacionais e suas implicações
A Sabedoria do Equilíbrio
O design eficaz de sistemas operacionais requer não a eliminação destes trade-offs, mas sua gestão inteligente por meio de arquiteturas que permitem diferentes configurações para diferentes contextos de uso. Sistemas modernos frequentemente implementam múltiplos modos de operação ou perfis que enfatizam diferentes aspectos deste espectro de compromissos.
A maestria no design de sistemas operacionais reside na compreensão profunda destes objetivos orientadores e na habilidade de criar arquiteturas que os equilibrem de forma apropriada para o contexto de uso pretendido. Não existe uma solução universal; cada sistema operacional representa uma manifestação específica destes princípios, calibrada para atender às necessidades particulares de seus usuários e ambiente de operação.
Arquiteturas de Sistemas Operacionais: Estruturando a Complexidade
A organização interna de um sistema operacional representa uma das decisões mais fundamentais no projeto de sistemas computacionais, determinando sua eficiência operacional, sua confiabilidade, escalabilidade e capacidade de evolução ao longo do tempo. A escolha da arquitetura reflete uma filosofia profunda sobre como gerenciar e dominar a complexidade inerente aos sistemas operacionais modernos, estabelecendo as fundações sobre as quais todas as funcionalidades serão construídas.
As diferentes abordagens arquiteturais não são meras variações técnicas. Estas escolhas representam diferentes paradigmas de pensamento sobre a organização de sistemas complexos. Mas, não se deixe enganar, atenta leitora, cada arquitetura incorpora um conjunto específico de trade-offs e prioridades, balanceando considerações como performance, segurança, manutenibilidade e evolução tecnológica.
Como um arquiteto que projeta um edifício considerando não apenas sua função atual, mas sua capacidade de adaptação futura, os projetistas de sistemas operacionais devem equilibrar necessidades imediatas com visão de longo prazo.
Neste capítulo, a atenta leitora encontrará uma análise das principais arquiteturas de sistemas operacionais,começaremos com a arquitetura monolítica e terminaremos com as tendências de futuro passando pela arquitetura de MicroKernel e pela arquitetura em camadas. Como pode ser visto na figura abaixo:
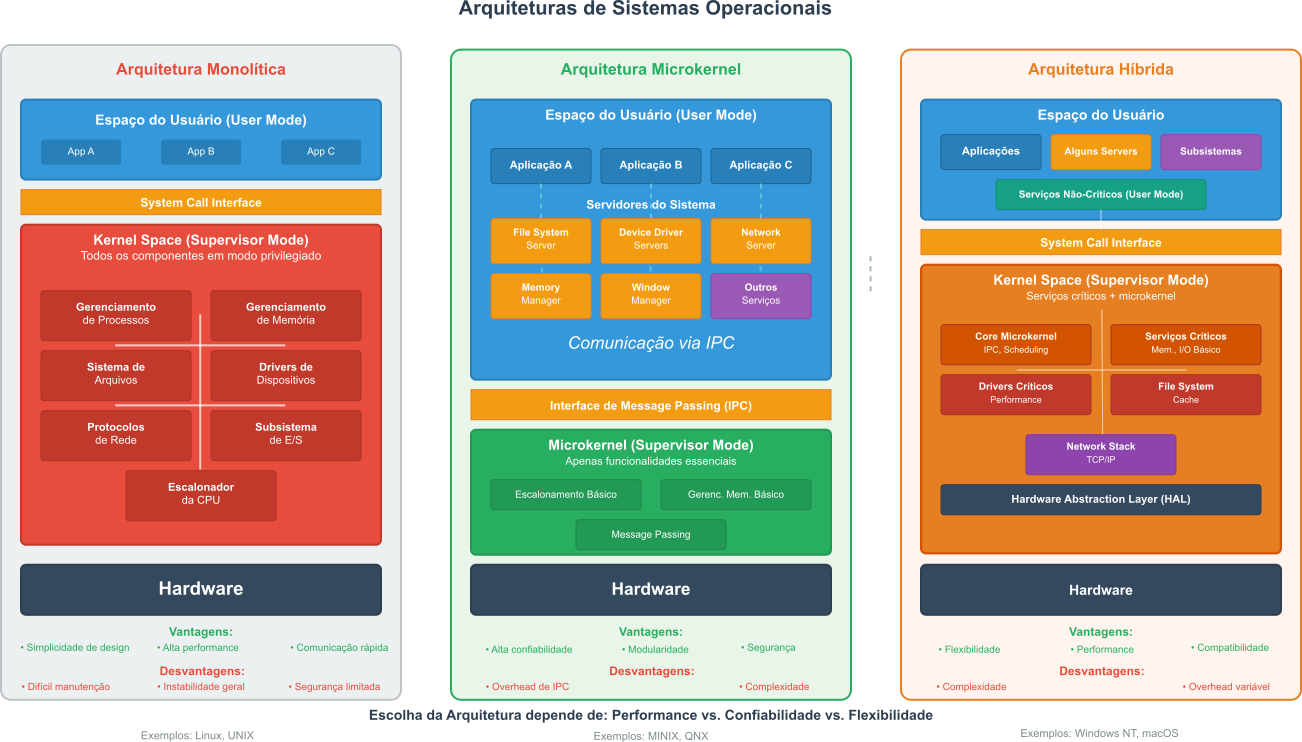 Figura 21: Comparação entre diferentes arquiteturas de sistemas operacionais
Figura 21: Comparação entre diferentes arquiteturas de sistemas operacionais
Arquitetura Monolítica: O Poder da Coesão e Simplicidade
Na arquitetura monolítica, encontramos uma abordagem que privilegia a simplicidade conceitual e a eficiência operacional por meio da unificação. Todo o sistema operacional executa como uma entidade coesa em um único espaço de endereçamento em modo kernel, com todos os serviços fundamentais operando no mesmo nível de privilégio máximo. Esta unificação, embora possa parecer arcaica pelos padrões contemporâneos, encerra uma elegância operacional que explica sua persistência em sistemas críticos.
A essência da arquitetura monolítica reside na eliminação de barreiras internas. Quando todos os componentes compartilham o mesmo espaço de memória e executam com privilégios idênticos, a comunicação entre eles torna-se quase instantânea. A comunicação é realizada por chamadas diretas de função sem custos computacionais extras para tradução, entre espaços de endereço diferentes, ou de validação de segurança de acesso. Esta intimidade arquitetural cria eficiência e velocidade.
Características Arquiteturais Fundamentais
De forma geral podemos caracterizar a arquitetura monolítica por:
-
Unidade de Espaço de Endereçamento: todos os componentes do sistema operacional compartilham um espaço de memória comum, permitindo acesso direto e imediato a estruturas de dados globais. Esta característica elimina a necessidade de mecanismos de tradução de endereços entre componentes, resultando em performance superior para operações internas. Com uma única tabela de páginas para todo o sistema, a latência de acesso à memória é minimizada. Porém, o uso de estruturas de dados compartilhadas pode introduzir complexidade adicional na sincronização e gerenciamento de concorrência. Sempre há um porém.
-
Comunicação Direta Inter-Componentes: módulos do sistema podem invocar funções uns dos outros diretamente, sem intermediação de protocolos de comunicação complexos. Esta característica reduz a latência de operações que requerem coordenação entre diferentes subsistemas. Economizando tempo, ciclos de processamento e espaço de memória. No entanto, esta comunicação direta pode introduzir dependências rígidas entre componentes, dificultando a manutenção e evolução do sistema. Quando não há um porém, há um no entanto.
-
Execução em Modo Privilegiado Universal: todo código do sistema operacional executa no nível de privilégio máximo, que em inglês chamamos de kernel mode. Este nível garante acesso irrestrito ao hardware e eliminando verificações de segurança que poderiam introduzir custo computacional extra.
-
Otimização de Performance Intrínseca: a ausência de barreiras entre componentes permite otimizações agressivas, incluindo inlining de funções críticas e compartilhamento direto de estruturas de dados complexas.
Estas características conferem à arquitetura monolítica uma performance bruta que é difícil de igualar em outras abordagens. No entanto, esta performance vem com um custo: a complexidade de manutenção e evolução do sistema. Neste contexto, a eficiência computacional representa talvez o benefício mais tangível da arquitetura monolítica. A comunicação entre componentes ocorre à velocidade de chamadas de função locais, sem o custo extra das mudanças de contexto, passagem de mensagens, ou verificações de validação que caracterizam arquiteturas mais compartimentalizadas. Para sistemas que priorizam performance bruta sobre outras considerações, esta eficiência pode ser determinante. Por outro lado, a simplicidade de implementação oferece vantagens significativas durante o desenvolvimento. Programadores podem implementar funcionalidades complexas sem preocupar-se com protocolos de comunicação inter-processo ou mecanismos de sincronização sofisticados. Esta simplicidade reduz tanto o tempo de desenvolvimento quanto a probabilidade de bugs relacionados à comunicação entre componentes.Finalmente, o compartilhamento transparente de recursos permite que diferentes subsistemas acessem e modifiquem estruturas de dados comuns de forma direta e eficiente. Este compartilhamento facilita a implementação de funcionalidades que requerem coordenação estreita entre múltiplos componentes do sistema.
Neste ponto, a atenta leitora deve ter percebido que a arquitetura monolítica apresenta uma série de vantagens que a tornam atraente para sistemas que priorizam performance e simplicidade de implementação. No entanto, estas vantagens vêm acompanhadas de desafios significativos que limitam sua aplicabilidade em ambientes modernos.
Limitações e Desafios Intrínsecos
A arquitetura monolítica, carrega consigo vulnerabilidades fundamentais que se manifestam como limitações operacionais significativas. Neste caso, considere que todo o sistema roda em um mesmo espaço de endereçamento, um único processo em kernel mode. Ou seja, a fragilidade sistêmica representa o calcanhar de Aquiles desta abordagem: uma falha em qualquer componente pode comprometer a estabilidade de todo o sistema. Esta vulnerabilidade existe precisamente devido à intimidade arquitetural que confere suas vantagens de performance. Além disso, este modo de operação implica que qualquer bug ou falha de segurança em um módulo pode potencialmente afetar todo o sistema, tornando-o suscetível a ataques e comprometimentos. Esta segurança limitada emerge como consequência natural da execução universal em modo privilegiado. Quando todo código possui acesso total ao hardware, a superfície de ataque torna-se vasta, e a contenção de vulnerabilidades de segurança torna-se extremamente desafiadora. Um bug em um driver de dispositivo pode potencialmente comprometer todo o sistema. Se a atenta leitora já trabalhou com sistemas monolíticos, deve ter percebido que a dificuldade de depuração é uma consequência direta da complexidade intrínseca desta abordagem. Com todos os componentes interligados em um único espaço de endereçamento, rastrear a origem de falhas torna-se uma tarefa monumental. Bugs podem se manifestar em locais distantes do ponto de origem, tornando o processo de identificação e correção extremamente trabalhoso. Ou seja, a complexidade de manutenção aumenta exponencialmente com o tamanho do sistema. Modificações em qualquer componente podem ter consequências imprevistas em outras partes do sistema, criando uma teia de interdependências que dificulta a evolução e o debugging. Esta complexidade pode tornar proibitiva a adição de novas funcionalidades ou a correção de bugs em sistemas maduros.
Exemplos Importantes
UNIX Tradicional: a implementação original do UNIX exemplifica a elegância da arquitetura monolítica. Desenvolvido em uma era na qual simplicidade e eficiência eram primordiais, o UNIX original demonstrou como um sistema monolítico bem projetado poderia oferecer funcionalidade robusta com o mínimo de custo computacional.
MS-DOS: embora primitivo pelos padrões modernos, o MS-DOS ilustra a simplicidade arquitetural extrema possível em sistemas monolíticos. Sua simplicidade contribuiu para sua adoção generalizada e demonstrou que sistemas monolíticos podem ser altamente eficazes para casos de uso específicos.
Linux Moderno: o kernel Linux representa uma evolução da arquitetura monolítica, incorporando módulos carregáveis que permitem alguma flexibilidade sem sacrificar a eficiência fundamental da abordagem monolítica. Esta abordagem híbrida permite que drivers e funcionalidades sejam adicionados dinamicamente, mantendo os benefícios de performance das chamadas diretas de função para operações principais. A Figura abaixo ilustra a pilha de abstração típica do Ubuntu 22.04 LTS, um exemplo moderno de sistema operacional monolítico:
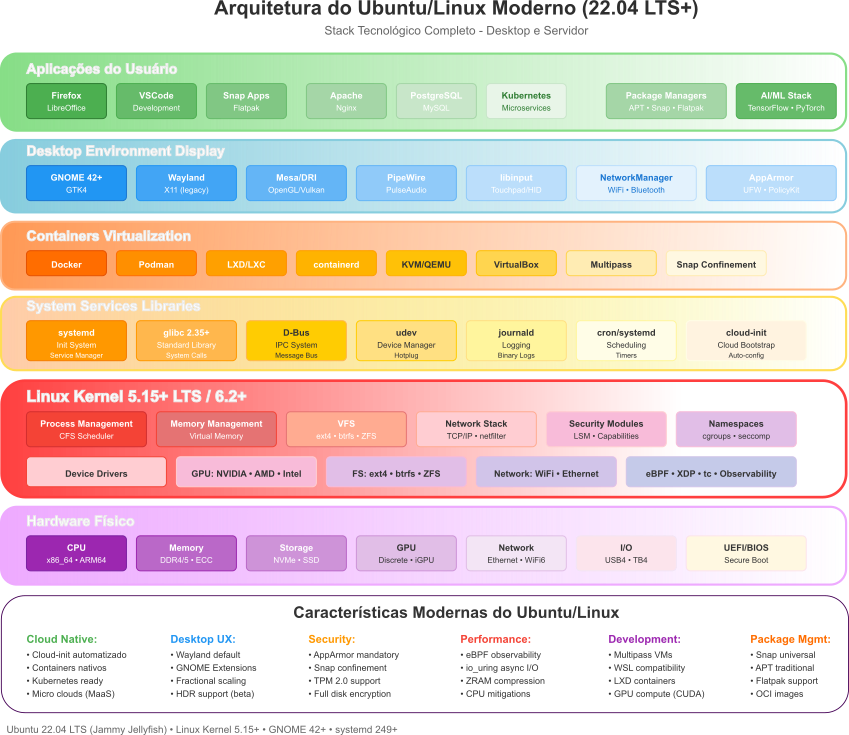 Figura 22: Diagrama em Blocos do Ubuntu 22.04 LTS destacando as camadas do sistema operacional.
Figura 22: Diagrama em Blocos do Ubuntu 22.04 LTS destacando as camadas do sistema operacional.
A Evolução do Linux: Monolítico com Flexibilidade
O kernel Linux representa uma evolução fascinante da arquitetura monolítica tradicional por meio da introdução de módulos carregáveis. Esta inovação permite que funcionalidades sejam adicionadas ou removidas dinamicamente sem requerer recompilação do sistema ou reinicialização. Os módulos executam no mesmo espaço de endereçamento do kernel, mantendo os benefícios de performance das chamadas diretas de função, mas podem ser carregados ou descarregados conforme necessário.
Os módulos carregáveis do kernel Linux foram introduzidos na versão 1.1.85 em janeiro de 1995, quando foi introduzido o arquivo README.modules no patch 1.1.85. A versão 1.0 do Linux havia sido lançada em março de 1994, então os módulos carregáveis vieram aproximadamente 10 meses depois da primeira versão considerada estável para produção. Inicialmente, poucos drivers estavam disponíveis como módulos, mas dentro de alguns anos tudo que fazia sentido como módulo estava disponível nessa forma. Esta funcionalidade permitiu que o kernel mantivesse suas características monolíticas de performance while adding the flexibility to load and unload components dynamically without kernel recompilation or system reboot.
Esta abordagem resolveu algumas das limitações tradicionais da arquitetura monolítica sem sacrificar suas vantagens fundamentais. Drivers podem ser desenvolvidos independentemente e carregados quando necessário, enquanto o kernel principal permanece estável e compacto.
O sistema de módulos do Linux demonstra como inovações arquiteturais podem abordar fraquezas tradicionais preservando forças fundamentais, criando abordagens híbridas que combinam o melhor de diferentes paradigmas arquiteturais.
Arquitetura de Microkernel: A Filosofia da Modularidade Extrema
A arquitetura de microkernel representa uma partida filosófica revolucionária da abordagem monolítica, abraçando modularidade e isolamento como princípios organizacionais fundamentais. Esta arquitetura move deliberadamente a vasta maioria dos serviços do sistema operacional para o espaço do usuário, deixando apenas as funcionalidades mais essenciais e irredutíveis no kernel. Esta separação radical cria um sistema no qual o kernel propriamente dito torna-se uma fundação mínima sobre a qual serviços mais complexos são construídos como entidades independentes.
A genialidade do microkernel reside em seu princípio minimalista. Em vez de tentar incorporar toda funcionalidade possível em uma entidade monolítica, esta arquitetura identifica o conjunto absolutamente mínimo de serviços que devem executar em modo privilegiado, relegando todas as outras funcionalidades para processos rodando em espaço de usuário, no inglês, user-space, que se comunicam com o núcleo essencial por meio de interfaces estrutural e logicamente bem definidas. Esta separação aumenta as oportunidades de modularidade, confiabilidade e segurança que são difíceis, ou impossíveis, de alcançar em sistemas monolíticos.
Princípios Arquiteturais Fundamentais
O kernel mínimo constitui o coração da filosofia microkernel. Este kernel implementa apenas as funcionalidades que absolutamente não podem ser implementadas com segurança ou eficiência em user-space: gerenciamento básico de processos para criar e escalonar contextos de execução, gerenciamento de memória de baixo nível para fornecer isolamento de espaço de endereçamento, e mecanismos de comunicação inter-processo para permitir comunicação controlada entre processos que estejam rodando em user-space. A consequência da relocação de serviços para user space fornece fronteiras naturais de isolamento e permite desenvolvimento, teste e implantação independentes de diferentes serviços do sistema. A relocação, promovida pela arquitetura microkernel remove serviços tradicionais do kernel, tais como sistemas de arquivos, drivers de dispositivo e stacks de protocolo de rede para processos separados que executam com privilégios normais de usuário. O que cria um ambiente onde cada serviço opera em seu próprio espaço de endereçamento, isolado dos outros. Esta separação não apenas melhora a confiabilidade, mas também permite que serviços sejam atualizados ou substituídos independentemente, aumentando a flexibilidade do sistema. Por outro lado, aumenta a complexidade de comunicação entre serviços, que deve ser cuidadosamente projetada para evitar sobrecarga excessiva e garantir eficiência. A comunicação inter-processo (IPC) torna-se o mecanismo central de interação entre serviços em user-space. Em vez de chamadas diretas de função, serviços comunicam-se por meio de mensagens estruturadas que são enviadas e recebidas por meio do microkernel. Esta abordagem não apenas fornece isolamento, mas também permite que serviços sejam distribuídos em diferentes máquinas em sistemas distribuídos, aumentando a escalabilidade e flexibilidade do sistema. Porém, a comunicação por meio de IPC introduz custos computacionais adicionais, pois cada mensagem deve ser serializada, enviada e desserializada, o que pode impactar a performance em sistemas com alta carga de comunicação. Embora esta substituição introduza algum custo extra de performance, ela fornece garantias fortes de isolamento e permite que serviços executem em espaços de endereçamento separados ou mesmo em máquinas separadas em sistemas distribuídos.
Estrutura Organizacional Típica
User Space - Serviços Isolados:
┌─────────────┬─────────────┬─────────────┬─────────────┐
│ Sistema │ Device │ Network │ Outros │
│ de │ Drivers │ Stack │ Serviços │
│ Arquivos │ Servers │ Server │ do SO │
└─────────────┴─────────────┴─────────────┴─────────────┘
↕ IPC Estruturado ↕
┌───────────────────────────────────────────────────────┐
│ Microkernel Minimal │
│ • Gerenciamento Básico de Processos │
│ • Gerenciamento de Memória de Baixo Nível │
│ • Comunicação Inter-Processo (IPC) │
│ • Escalonamento Fundamental │
│ • Tratamento de Interrupções │
└───────────────────────────────────────────────────────┘
Hardware Físico
A separação entre serviços em user space e o microkernel cria fronteiras naturais que simplificam o entendimento do sistema e permitem evolução independente de diferentes componentes. Cada serviço torna-se uma entidade auto-contida que pode ser desenvolvida, testada e implantada independentemente.
Vantagens Sistêmicas Significativas
Esta estrutura modularizada oferece uma série de vantagens significativas que a tornam atraente para sistemas modernos já que minimizaram os problemas que existiam na arquitetura monolítica original dos sistemas operacionais. Entre estas vantagens, a confiabilidade por meio do isolamento representa uma das mais interessantes e convincentes da arquitetura microkernel. Quando um serviço falha, sua falha é naturalmente contida dentro de seu próprio espaço de endereçamento, prevenindo falhas em cascata que poderiam comprometer outros componentes, ou o sistema como um todo. Este isolamento fornece tolerância a falhas inerente que é difícil de alcançar em arquiteturas monolíticas. A mesma vantagem de isolamento também contribui para a segurança. Neste caso dizemos que obtemos segurança por meio da compartimentalização. Ou seja a fragmentação do kernel em serviços independentes limita o raio de explicitação e exploração de vulnerabilidades de segurança. Se um driver de dispositivo ou serviço de rede é comprometido, um atacante ganha acesso apenas àquele serviço específico, não ao sistema inteiro. Esta compartimentalização cria fronteiras naturais de segurança que limitam os danos que podem ser causados por código malicioso ou componentes comprometidos.
Na arquitetura microkernel a flexibilidade arquitetural, criada pela fragmentação, permite a configuração dinâmica do sistema e facilita sua evolução. Serviços podem ser iniciados, parados, atualizados ou substituídos sem afetar outros componentes ou requerer reinicialização do sistema. Esta flexibilidade é particularmente valiosa em ambientes que requerem alta disponibilidade ou atualizações frequentes. Servidores de alta disponibilidade, por exemplo, podem atualizar serviços críticos sem interromper o sistema inteiro. A portabilidade facilitada é outra vantagem significativa da arquitetura microkernel. Como o kernel é minimalista e contém apenas funcionalidades essenciais, ele pode ser facilmente portado para novas arquiteturas de hardware. Serviços em user-space, que são frequentemente independentes do kernel, podem ser reutilizados em diferentes plataformas com modificações mínimas. Esta portabilidade reduz o custo e o tempo necessários para adaptar o sistema operacional a novas arquiteturas de hardware.
Desafios Inerentes
A arquitetura microkernel, contudo, possui seu próprio conjunto de desafios que devem ser cuidadosamente considerados. O custo computacional extra de comunicação representa uma preocupação primária, pois operações de IPC são inerentemente mais caras que chamadas diretas de função. Toda interação entre serviços requer mudanças de contexto, construção e análise de mensagens, e potencial cópia de dados, tudo isso introduz um fator extra de custo computacional. Além disso, a complexidade de design aumenta significativamente quando uma dada funcionalidade é distribuída por meio de múltiplos serviços independentes. Arquitetos de sistema devem projetar protocolos de IPC críticos, lidar com dependências de serviços e garantir sequenciamento adequado de operações por meio da definição de fronteiras de serviços. Esta complexidade pode tornar o entendimento e a manutenção do sistema mais desafiadores. Implicando em um custo extra de desenvolvimento. Esse Custo extra de desenvolvimento pode ser substancial. Desenvolvedores devem criar e manter múltiplos serviços independentes em vez de adicionar funcionalidade a uma base de código monolítica. Cada serviço requer seu próprio sistema de construção, compilação, rotinas de testes e mecanismos de implantação, aumentando a carga geral de desenvolvimento.
Implementações Notáveis e Influentes
MINIX: desenvolvido por Andrew Tanenbaum para propósitos educacionais, o MINIX demonstrou a viabilidade e elegância da arquitetura microkernel. Sua influência se estendeu muito além da educação, inspirando designs subsequentes de microkernel e contribuindo para uma compreensão mais ampla da arquitetura modular de sistemas. O famoso debate entre Tanenbaum e Linus Torvalds sobre os méritos relativos de arquiteturas microkernel versus monolíticas ajudou a cristalizar muitas das questões-chave no design de sistemas operacionais.
QNX: um sistema operacional comercial de tempo real, o QNX demonstra como arquiteturas microkernel podem entregar confiabilidade excepcional e performance de tempo real. Seu uso em aplicações críticas como sistemas de controle automotivo e dispositivos médicos valida a abordagem microkernel para ambientes exigentes que requerem tempos de resposta garantidos e tolerância a falhas.
Família L4: a família de microkernels L4 representa um esforço sustentado para otimizar performance de microkernel mantendo seus benefícios arquiteturais. por meio de atenção cuidadosa à eficiência de IPC e design mínimo de kernel, implementações L4 demonstram que a lacuna de performance entre sistemas microkernel e monolíticos pode ser significativamente reduzida sem sacrificar benefícios de modularidade.
Arquitetura em Camadas e Híbrida: A Abordagem Moderna
A arquitetura em camadas é, na prática, a arquitetura mais comum no design de sistemas operacionais modernos. Sem nenhum esforço imaginativo seríamos capazes de classificar nesta arquitetura os sistemas:
-
Windows NT/Windows modernos: apresenta uma arquitetura claramente estratificada com camadas bem definidas - HAL (Hardware Abstraction Layer), kernel, executive services, subsistemas de ambiente e aplicações de usuário. Cada camada fornece interfaces específicas para a camada superior.
-
macOS/Darwin: segue uma estrutura em camadas baseada no Mach microkernel com BSD Unix, organizando-se em kernel space, system frameworks, application frameworks e user applications. A separação entre kernel e user space é bem definida.
-
QNX: sistema operacional de tempo real que implementa uma arquitetura em camadas rigorosa, com microkernel na base, seguido por serviços de sistema, managers de recursos e aplicações.
-
Sistemas Android: embora baseado no kernel Linux, o Android implementa uma arquitetura em camadas clara - kernel Linux, HAL, runtime Android, application framework e applications.
-
Sistemas embarcados/IoT: muitos sistemas embarcados modernos adotam arquiteturas em camadas por necessidade de organização e recursos limitados, especialmente em RTOS (Real-Time Operating Systems).
Ainda assim, nenhum destes sistemas é estritamente monolítico ou microkernel, mas sim uma combinação de ambos, o que nos leva a concluir que a arquitetura em camadas é uma abordagem híbrida que combina os melhores aspectos de ambos os paradigmas.
A abordagem em camadas oferece um meio-termo convincente entre a eficiência de sistemas monolíticos e a modularidade de arquiteturas microkernel. Esta arquitetura organiza o sistema operacional como uma hierarquia cuidadosamente estruturada de camadas, cada uma das quais utiliza apenas os serviços da camada imediatamente inferior. Esta organização hierárquica cria um sistema que é simultaneamente modular e eficiente, permitindo separação clara de responsabilidades mantendo características de performance previsíveis.
A estruturação disciplinada em camadas cria um conjunto natural de ferramentas para entendimento e desenvolvimento do sistema. Cada camada fornece uma abstração bem definida que esconde a complexidade das camadas abaixo enquanto fornece serviços para as camadas acima. Esta hierarquia de abstração permite que desenvolvedores trabalhem em um nível apropriado de detalhe para suas tarefas específicas, sem precisar entender os detalhes de implementação de todos os componentes do sistema.
Estrutura Hierárquica Clássica
Camada 7: Aplicações de Usuário
↓ Interface de Sistema ↓
Camada 6: Interface do Usuário (GUI/CLI)
↓ Chamadas de Sistema ↓
Camada 5: Comunicação e Controle de E/S
↓ Operações de Dispositivo ↓
Camada 4: Comunicação Inter-Processo
↓ Sincronização ↓
Camada 3: Memória Virtual e Paginação
↓ Gerenciamento de Memória ↓
Camada 2: Escalonamento de CPU
↓ Controle de Processo ↓
Camada 1: Gerenciamento de Hardware
↓ Instruções de Máquina ↓
Camada 0: Hardware Físico
Cada camada nesta hierarquia fornece um conjunto coeso de serviços que se constroem sobre as capacidades das camadas abaixo. Esta abordagem estruturada permite desenvolvimento e teste sistemáticos, pois cada camada pode ser validada independentemente antes que camadas superiores sejam construídas sobre ela.
Características Organizacionais
A estrutura hierárquica em camadas oferece uma série de características organizacionais que a tornam atraente para sistemas operacionais modernos. A atenta leitora pode começar considerando que a hierarquia rígida impõe padrões de comunicação disciplinados que previnem interações arbitrárias entre camadas não adjacentes. Esta restrição cria comportamento previsível do sistema e simplifica a manutenção do sistema. As interações são limitadas por interfaces bem definidas que existem entre camadas adjacentes. Esta, por assim dizer pilha, de camadas permite a criação de um ambiente com abstração progressiva na qual cada camada forneça uma interface mais sofisticada e amigável ao usuário, ou ao desenvolvedor, que as camadas abaixo. Conforme percorremos a hierarquia para cima, as operações tornam-se mais abstratas e poderosas, escondendo quantidades crescentes de complexidade de baixo nível dos componentes de alto nível. Isto é uma forma de modularidade estruturada que facilita o entendimento e manutenção do sistema por meio de separação clara de responsabilidades e liberdades. Ou seja, cada camada tem um papel bem definido em conjunto de responsabilidades e liberdades, tornando mais fácil localizar e corrigir problemas ou criar novas funcionalidades. Tudo que é necessário para adicionar uma nova funcionalidade é criar uma nova camada que se encaixe na hierarquia existente, utilizando as interfaces definidas pelas camadas adjacentes. Finalmente, a reutilização de código é facilitada pela estruturação em camadas, pois camadas inferiores podem ser reutilizadas por múltiplas camadas superiores sem duplicação de código. Esta reutilização reduz o custo de desenvolvimento e manutenção, permitindo que funcionalidades comuns sejam implementadas uma vez e utilizadas em diferentes contextos.
O Sistema THE: Um Exemplo Histórico
O Sistema Operacional THE, desenvolvido por Edsger Dijkstra nos anos 1960, serve como uma demonstração clássica dos benefícios da estruturação em camadas no design de sistemas operacionais. A atenção cuidadosa de Dijkstra ao isolamento de camadas e design de interface criou um sistema que era tanto compreensível quanto confiável, demonstrando que abordagens arquiteturais disciplinadas poderiam melhorar significativamente a qualidade do sistema.
A abordagem em camadas do sistema THE permitiu verificação sistemática de correção em cada camada, uma abordagem que foi revolucionária para sua época e continua a influenciar práticas modernas de design de sistemas. Sua ênfase em abstrações claras e interfaces mínimas entre camadas estabeleceu princípios que permanecem relevantes na arquitetura de sistemas contemporâneos.
Arquiteturas Híbridas: Síntese e Adaptação Pragmática
E aqui está o resultado de décadas de desenvolvimento e experimentação: a arquitetura híbrida. Esta abordagem representa uma síntese madura dos princípios de design de sistemas operacionais, combinando elementos de diferentes paradigmas arquiteturais para criar sistemas que são ao mesmo tempo eficientes, modulares e adaptáveis. Em vez de se comprometer com uma única filosofia arquitetural, os sistemas operacionais modernos adotam uma abordagem pragmática que reconhece a complexidade e diversidade dos ambientes computacionais contemporâneos.
A evolução em direção a arquiteturas híbridas representa um reconhecimento pragmático de que abordagens arquiteturais puras frequentemente envolvem escolhas entre custos e performance que são desnecessárias e, frequentemente, contraproducentes. Aplicando seletivamente diferentes princípios arquiteturais a diferentes componentes do sistema, designs híbridos podem capturar os benefícios de múltiplas abordagens enquanto mitigam suas fraquezas individuais.
Windows NT: Kernel Híbrido Pioneiro
Windows NT e suas iterações sucessivas representam uma abordagem híbrida sofisticada que combina modularidade de microkernel com performance monolítica. Este kernel híbrido coloca serviços sensíveis à performance em modo kernel enquanto relega funcionalidade menos crítica para processos em user-space.
A Camada de Abstração de Hardware (HAL) isola código específico de plataforma, permitindo portabilidade por meio de diferentes arquiteturas de hardware mantendo performance. Esta abstração demonstra como estruturação cuidadosa em camadas pode fornecer benefícios de portabilidade sem sacrificar eficiência.
Subsistemas protegidos permitem que diferentes ambientes de programação (Win32, POSIX) coexistam no mesmo sistema, cada um implementado como subsistemas separados que comunicam por meio de interfaces bem definidas. Esta abordagem fornece compatibilidade e flexibilidade mantendo integridade do sistema.
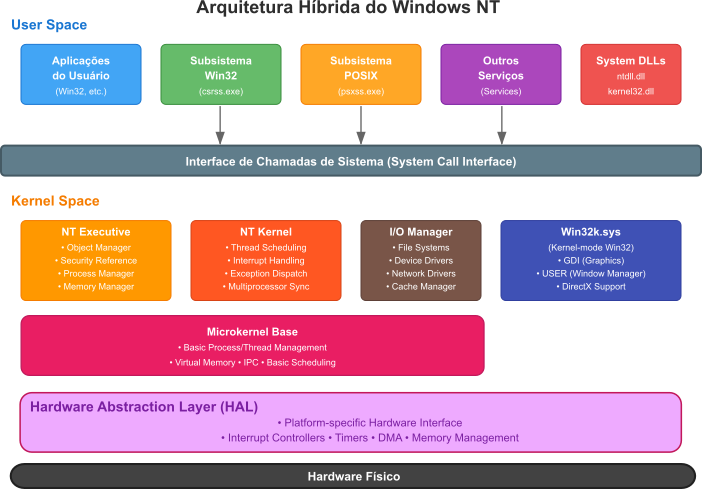 Figura 22: Arquitetura híbrida do Windows NT, demonstrando a sofisticada combinação de elementos microkernel e monolíticos para otimização de performance e flexibilidade
Figura 22: Arquitetura híbrida do Windows NT, demonstrando a sofisticada combinação de elementos microkernel e monolíticos para otimização de performance e flexibilidade
macOS/Darwin: Fundação Microkernel com Melhorias Monolíticas
O kernel XNU no macOS representa uma abordagem híbrida particularmente interessante que combina uma fundação microkernel Mach com componentes monolíticos BSD. Esta combinação aproveita as capacidades de mensagens e modularidade do Mach enquanto fornece a performance e funcionalidade de serviços UNIX tradicionais.
IOKit fornece um framework orientado a objetos para drivers de dispositivo que combina os benefícios de segurança da execução em user-space com as necessidades de performance da operação em kernel-space. Este framework demonstra como princípios de design orientado a objetos podem ser aplicados a componentes de sistema operacional sem sacrificar performance.
A distribuição de serviços entre kernel space e user space no macOS reflete análise cuidadosa de quais serviços verdadeiramente requerem privilégios de kernel e quais podem ser implementados com segurança em user space sem penalidades inaceitáveis de performance.
Conceitos Avançados: Expandindo os Horizontes dos Sistemas Operacionais
A atenta leitora já deve ter percebido que a evolução dos sistemas operacionais transcende as implementações tradicionais, abraçando paradigmas computacionais que redefinem as fronteiras entre hardware e software. Esta expansão conceitual reflete a complexidade crescente dos ambientes computacionais da terceira década do século XXI, nos quais sistemas operacionais devem gerenciar não apenas recursos locais, mas coordenar operações distribuídas, garantir responsividade temporal e fornecer camadas de abstração sobre infraestruturas virtualizadas.
Estes conceitos avançados representam a materialização de décadas de pesquisa e desenvolvimento, transformando propostas teóricas em implementações práticas que moldam a infraestrutura computacional contemporânea. A compreensão destes paradigmas é indispensável para profissionais que desejam navegar efetivamente no panorama tecnológico atual e futuro.
Virtualização: A Arte da Abstração de Hardware
A virtualização constitui uma das inovações mais transformadoras na arquitetura de sistemas computacionais, permitindo que múltiplos sistemas operacionais executem simultaneamente em uma única máquina física. Cada sistema operacional convidado opera sob a ilusão de possuir controle exclusivo do hardware, quando na realidade compartilha recursos físicos por meio de camadas sofisticadas de abstração.
Esta tecnologia fundamenta-se no conceito de camadas de abstração, nais quais um software especializado, denominado hypervisor ou monitor de máquina virtual, interpõe-se entre o hardware físico e os sistemas operacionais convidados. O hypervisor assume a responsabilidade de gerenciar e alocar recursos físicos, criando ambientes virtualizados que emulam máquinas completas.
A implementação da virtualização manifesta-se por meio de três paradigmas principais, cada um com características técnicas e casos de uso específicos:
-
Virtualização Completa (Full Virtualization)
Na virtualização completa, o hypervisor fornece uma emulação integral do hardware subjacente, criando uma abstração transparente que permite a execução de sistemas operacionais convidados sem qualquer modificação. Esta abordagem oferece compatibilidade máxima, permitindo que sistemas operacionais existentes sejam executados em ambientes virtualizados sem alterações no código fonte.
O hypervisor intercepta e traduz todas as instruções privilegiadas dos sistemas convidados, mantendo o isolamento entre máquinas virtuais enquanto fornece acesso controlado aos recursos físicos. Esta intermediação introduz custos computacionais extras, mas garante isolamento robusto e compatibilidade universal.
Casos Importantes: VMware vSphere, Microsoft Hyper-V, Oracle VirtualBox.
-
Paravirtualização
A paravirtualização requer modificações específicas nos sistemas operacionais convidados para colaborar ativamente com o hypervisor. Em vez de emular completamente o hardware, esta abordagem expõe interfaces especializadas que permitem comunicação direta entre o sistema convidado e o hypervisor.
Esta colaboração elimina a necessidade de interceptação e tradução de instruções, resultando em performance superior comparada à virtualização completa. O custo desta eficiência reside na necessidade de modificação dos sistemas operacionais convidados, limitando a compatibilidade com sistemas existentes.
Casos Importantes: Xen Hypervisor (modo paravirtualizado).
-
Virtualização de Containers
A virtualização de containers representa uma abordagem fundamentalmente diferente que compartilha o kernel do sistema operacional hospedeiro entre múltiplos ambientes isolados. Cada container encapsula uma aplicação e suas dependências, mas utiliza o mesmo kernel subjacente, criando um isolamento de processo ao nível do sistema operacional.
Esta abordagem oferece eficiência superior em termos de recursos, pois elimina a sobrecarga de múltiplos kernels de sistema operacional. O isolamento é implementado por meio de namespaces e cgroups, tecnologias que criam ambientes separados para processos, sistemas de arquivos, redes e recursos.
Casos Importantes: Docker, LXC (Linux Containers), Containerd.
Comparação de Eficiência entre Abordagens de Virtualização
A eficiência relativa das diferentes abordagens de virtualização pode ser quantificada por meio de métricas de performance:
- Virtualização Completa: custos computacionais extras típicos de $5-15\%$ devido à interceptação de instruções;
- Paravirtualização: custo computacional extra reduzido de $2-5\%$ por meio da colaboração kernel-hypervisor;
- Containerização: custo computacional extra mínimo $<2\%$ devido ao compartilhamento de kernel.
Esses valores de custos extras variam significativamente conforme a carga de trabalho específica e a eficiência da implementação do hypervisor.
Benefícios Sistêmicos da Virtualização
A adoção da virtualização transcende considerações puramente técnicas, oferecendo vantagens operacionais e econômicas significativas que transformam a forma como sistemas computacionais são projetados e gerenciados. A atenta leitora deve considerar a virtualização permite que múltiplos sistemas operacionais sejam executados em hardware único, maximizando a utilização de recursos e reduzindo custos de infraestrutura física. Chamamos este benefício de Consolidação de Infraestrutura. Esta consolidação reduz a necessidade de hardware físico dedicado para cada sistema, resultando em economia significativa de custos operacionais e energéticos enquanto permite que cada máquina virtual opera em um ambiente isolado, garantindo que falhas ou comprometimentos de segurança em um sistema não afetem outros sistemas executando no mesmo hardware. Este benefício é conhecido como Isolamento de Segurança. Além disso, a virtualização permite a criação de Snapshots e Clones, facilitando backup, recuperação e replicação de ambientes inteiros com facilidade. Esta capacidade de capturar o estado completo de uma máquina virtual em um dado momento simplifica significativamente operações de manutenção e recuperação de desastres. Além disso, máquinas virtuais podem ser migradas entre hosts físicos sem interrupção de serviço, facilitando manutenção de hardware e balanceamento de carga dinâmico. Esta é a Flexibilidade Operacional. Finalmente, a virtualização fornece ambientes controlados para desenvolvimento e teste, permitindo a criação rápida de configurações específicas sem investimento em hardware adicional.
Sistemas Distribuídos: Coordenação em Escala
Sistemas operacionais distribuídos enfrentam o desafio fundamental de gerenciar recursos espalhados por múltiplas máquinas físicas, apresentando uma visão unificada e coerente do sistema para usuários e aplicações. Esta unificação requer a solução de problemas intrinsecamente complexos relacionados à comunicação, sincronização e coordenação em ambientes onde falhas parciais são inevitáveis. Imagine o qual complicado estes sistemas devem ser.
A complexidade dos sistemas distribuídos surge da necessidade de manter consistência e coordenação sem assumir comunicação instantânea ou confiabilidade perfeita da infraestrutura de rede. Estas limitações fundamentais criam desafios únicos que não existem em sistemas centralizados. Podemos avaliar estes desafios em quatro categorias:
-
Transparência Operacional
O objetivo da transparência é ocultar a natureza distribuída do sistema dos usuários finais, criando a ilusão de um sistema centralizado uniforme. Esta transparência manifesta-se em múltiplas dimensões:
- Transparência de Localização: usuários acessam recursos sem conhecer sua localização física;
- Transparência de Migração: recursos podem ser movidos sem afetar usuários;
- Transparência de Replicação: múltiplas cópias de dados existem sem conhecimento do usuário;
- Transparência de Falhas: o sistema continua operando mesmo com falhas de componentes.
-
Escalabilidade Horizontal
Sistemas distribuídos devem funcionar eficientemente conforme o número de vértices aumenta de dezenas para milhares ou milhões. Esta escalabilidade requer algoritmos e protocolos que não degradem significativamente com o crescimento do sistema.
A escalabilidade enfrenta limitações fundamentais relacionadas à largura de banda de rede, latência de comunicação e complexidade de coordenação. Algoritmos centralizados tornam-se impraticáveis em escalas grandes, exigindo abordagens descentralizadas.
-
Tolerância a Falhas
A probabilidade de falha de pelo menos um dos componentes de sistemas distribuídos grandes aproxima-se de 100%. Sistemas devem ser projetados assumindo que falhas são norma, não exceção, e continuar operando mesmo com perda de componentes individuais.
-
Consistência de Dados
Manter dados sincronizados entre múltiplos vértices de um mesmo sistema distribuído apresenta a necessidade da realização de escolhas entre os custos de consistência, disponibilidade e tolerância, formalizadas pelo Teorema CAP (Consistency, Availability, Partition tolerance).
O Teorema CAP: A Impossibilidade Fundamental dos Sistemas Distribuídos
O Teorema CAP, formulado por Eric Brewer em 2000 e posteriormente provado por Gilbert e Lynch em 2002, estabelece uma limitação fundamental para sistemas distribuídos. O teorema afirma que é impossível para qualquer sistema distribuído garantir simultaneamente as três propriedades seguintes:
Consistency (Consistência): Todos os vértices veem os mesmos dados ao mesmo tempo. Qualquer operação de leitura recebe a escrita mais recente ou um erro. Formalmente, o sistema se comporta como se houvesse uma única cópia dos dados.
Availability (Disponibilidade): O sistema permanece operacional 100% do tempo. Toda requisição recebe uma resposta (sem garantia de que contenha a escrita mais recente). O sistema nunca retorna erro devido à indisponibilidade.
Partition tolerance (Tolerância a Partições): O sistema continua operando mesmo quando mensagens entre vértices são perdidas ou atrasadas devido a falhas de rede. A rede pode dividir-se em partições isoladas.
Como partições de rede são inevitáveis em sistemas distribuídos reais, os arquitetos de sistemas devem escolher entre um de dois sistemas possíveis CP (Consistency + Partition tolerance) ou AP (Availability + Partition tolerance):
- Sistemas CP: priorizam consistência. Durante partições, alguns vértices tornam-se indisponíveis para manter consistência. Exemplos: sistemas bancários, bancos de dados ACID tradicionais.
- Sistemas AP: Priorizam disponibilidade. Durante partições, o sistema aceita inconsistências temporárias. Exemplos: DNS, sistemas de cache distribuído, redes sociais.
O teorema aplica-se apenas durante partições de rede. Em operação normal, sistemas podem fornecer todas as três propriedades. Além disso, as definições são binárias - na prática, existem graus de consistência e disponibilidade que permitem trade-offs mais refinados.
Modelos de Consistência
A consistência de dados e informações entre sistemas fisicamente distantes é um dos problemas mais complexos e importantes no desenvolvimento de sistemas operacionais distribuídos. Para resolver este problema os sistemas distribuídos empregam diferentes modelos de consistência conforme os requisitos específicos da aplicação entre eles vamos destacar:
-
Consistência Forte (Strong Consistency)
\[\forall \text{ operações de leitura retornam o valor da escrita mais recente}\]Este modelo garante que todas as réplicas mantenham estado idêntico em todos os momentos, mas impõe custos significativos de coordenação e pode limitar a disponibilidade.
-
Consistência Eventual (Eventual Consistency)
\[\text{Sistema converge para estado consistente após cessarem as atualizações}\]Este modelo permite inconsistências temporárias em troca de maior disponibilidade e performance, sendo adequado para aplicações que toleram dados ligeiramente desatualizados.
Caberá ao arquiteto do sistema, ou ao desenvolvedor, escolher o modelo de consistência mais adequado para a aplicação específica, considerando um balanceamento entre os custos da consistência, disponibilidade e performance.
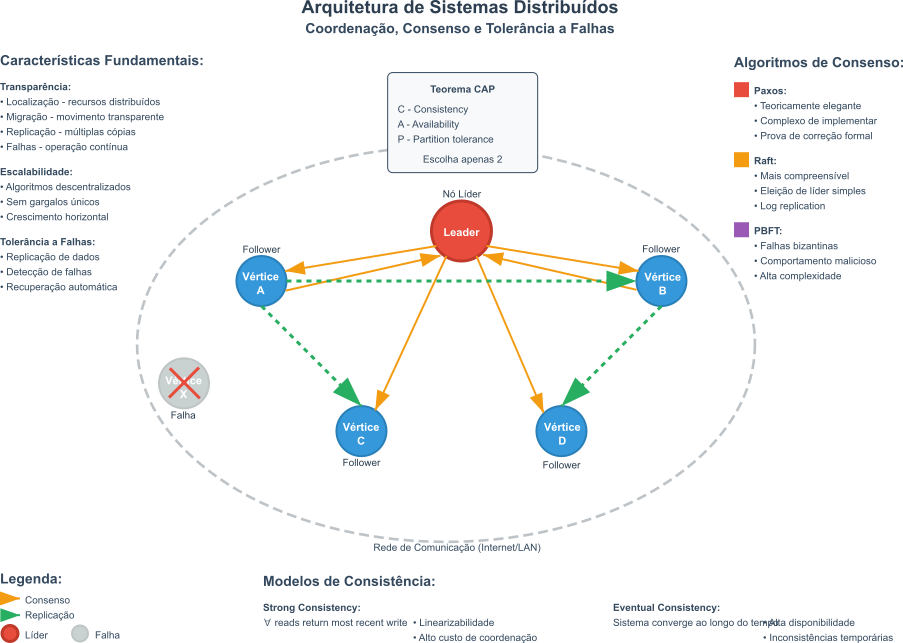 Figura 25: Diagrama de um sistema distribuído em rede.
Figura 25: Diagrama de um sistema distribuído em rede.
Algoritmos de Consenso
A coordenação em sistemas distribuídos frequentemente requer que vértices alcancem consenso sobre valores específicos mesmo na presença de falhas. Neste cenário, algoritmos de consenso desempenham um papel crucial, permitindo que vértices distribuídos concordem sobre decisões críticas, como a escolha de um líder ou o valor de uma variável compartilhada. Entre os algoritmos mais importantes vamos destacar
Paxos: algoritmo teórico fundamental que resolve o problema de consenso em sistemas assíncronos sujeitos a falhas de parada. Embora matematicamente elegante, sua complexidade de implementação limitou a adoção prática.
Raft: algoritmo projetado para ser mais compreensível que Paxos, mantendo garantias de correção similares. Raft divide o problema de consenso em eleição de líder, replicação de log e verificação de segurança.
PBFT (Practical Byzantine Fault Tolerance): algoritmo que tolera falhas bizantinas arbitrárias, incluindo comportamento malicioso de vértices. Adequado para ambientes adversariais onde vértices podem ser comprometidos.
| Algoritmo | Tipo de Falha Tolerada | Complexidade de Implementação | Eficiência |
|---|---|---|---|
| Paxos | Falhas de parada | Alta | Moderada |
| Raft | Falhas de parada | Moderada | Alta |
| PBFT | Falhas bizantinas | Muito Alta | Baixa |
Tabela 9: Comparação de Algoritmos de Consenso
Sistemas de Tempo Real: Garantindo Determinismo Temporal
Os Sistemas de tempo real operam sob restrições temporais rígidas, onde a correção não depende apenas da computação realizada, mas do momento em que os resultados são produzidos. Atrasos na resposta podem resultar em falhas catastróficas, tornando a previsibilidade temporal tão importante quanto a correção funcional.
Estes sistemas diferem fundamentalmente de sistemas convencionais por priorizarem previsibilidade sobre throughput. A otimização dos sistemas operacionais em sistemas de tempo real visa garantir que limites temporais de respostas críticos sejam cumpridos consistentemente, mesmo que isso resulte em menor utilização média de recursos. O objetivo é ter sistemas que interajam com o ambiente em tempo real, respondendo a eventos dentro de prazos estritos. Podemos classificar estes sistemas em três categorias principais:
-
Hard Real-Time (Tempo Real Crítico)
Sistemas nos quais deadlines absolutas nunca podem ser violadas. Uma única violação de deadline pode resultar em falha catastrófica do sistema, perda de vidas humanas ou danos econômicos significativos.
Casos Importantes: sistemas de controle de voo, marcapassos, sistemas de frenagem automotiva, controladores de usinas nucleares.
-
Soft Real-Time (Tempo Real Flexível)
Sistemas nos quais deadlines representam objetivos preferenciais, mas violações ocasionais são toleráveis. A utilidade dos resultados decresce gradualmente após o deadline, mas não se torna completamente inútil.
Casos Importantes: sistemas multimídia, jogos interativos, sistemas de telecomunicações.
-
Firm Real-Time (Tempo Real Firme)
Sistemas nos quais resultados tardios tornam-se completamente inúteis, mas não causam dano ao sistema. Violações de deadline resultam em perda de utilidade, mas não em falha catastrófica.
Casos Importantes: sistemas de transmissão de vídeo, processamento de transações financeiras de alta frequência.
Características do Escalonamento em Tempo Real
O escalonamento em sistemas de tempo real emprega algoritmos especializados que consideram as datas limites de entrega além de prioridades tradicionais. As principais características incluem: o Escalonamento Preemptivo, no qual tarefas de maior prioridade podem interromper tarefas de menor prioridade para garantir cumprimento de datas críticas; e os algoritmos de Análise de Escalonabilidade. Nos quais, a verificação matemática de que todas as tarefas cumprirão seus prazos de entrega sob condições específicas de carga.
Entre os algoritmos de escalonamento mais importantes, destacamos:
-
Rate Monotonic (RM)
Para tarefas periódicas com deadlines iguais aos períodos, o algoritmo Rate Monotonic atribui prioridades inversamente proporcionais aos períodos das tarefas:
\[U = \sum_{i=1}^{n} \frac{C_i}{T_i} \leq n(2^{1/n} - 1)\]Nesta inequação, $C_i$ representa o tempo de execução e $T_i$ o período da tarefa $i$. O conjunto de tarefas é escalonável se a utilização total não exceder o limite estabelecido.
-
Earliest Deadline First (EDF)
O algoritmo EDF prioriza dinamicamente tarefas baseando-se na proximidade de seus deadlines. Para sistemas com utilização total:
\[U = \sum_{i=1}^{n} \frac{C_i}{T_i} \leq 1\]o conjunto de tarefas é escalonável. EDF é optimal para sistemas de tempo real, garantindo escalonabilidade sempre que matematicamente possível.
 Figura 26: Diagrama dos algoritmos de escalonamento comuns em sistemas operacionais de tempo real
Figura 26: Diagrama dos algoritmos de escalonamento comuns em sistemas operacionais de tempo real
Teste de Escalonabilidade para Rate Monotonic
O limite de utilização para Rate Monotonic decresce conforme o número de tarefas aumenta:
- n = 1: U ≤ 1.000 (100%)
- n = 2: U ≤ 0.828 (82.8%)
- n = 3: U ≤ 0.780 (78.0%)
- n → ∞: U ≤ 0.693 (69.3%)
Esta degradação reflete o custo crescente de coordenação entre múltiplas tarefas periódicas.
Referências Bibliográficas
ACM. The development of the C programming language. Disponível em: https://dl.acm.org/doi/10.1145/234286.1057834. Acesso em: 7 jun. 2025.
AMD. Computação quântica. Disponível em: https://www.amd.com/pt/solutions/quantum-computing.html. Acesso em: 15 out. 2024.
AMNIC. Cloud Computing Elasticity: A Game Changer for Modern Businesses. Amnic, [s.d.]. Disponível em: https://amnic.com/blogs/cloud-computing-elasticity. Acesso em: 15 out. 2024.
ANDRADE, W. L.; SANTOS, G. L.; MACEDO, R. J. A. de. ANÁLISE E AVALIAÇÃO FUNCIONAL DE SISTEMAS OPERACIONAIS MÓVEIS: VANTAGENS E DESVANTAGENS. Revista de Sistemas de Informação da UNIFACS – RSI, Salvador, n. 3, p. 3-13, jan./jun. 2013. Disponível em: https://revistas.unifacs.br/index.php/rsc/article/download/2581/1950. Acesso em: 15 out. 2024.
APPLEINSIDER. Apple turns to AI for battery management in iOS 19. AppleInsider, 12 may 2025. Disponível em: https://appleinsider.com/articles/25/05/12/apple-turns-to-ai-for-battery-management-in-ios-19. Acesso em: 15 out. 2024.
ARUTE, F. et al. Quantum supremacy using a programmable superconducting processor. Nature, v. 574, n. 7779, p. 505-510, Oct. 2019.
AZURE. Introdução à computação quântica híbrida - Azure Quantum. Microsoft Learn, 07 ago. 2024. Disponível em: https://learn.microsoft.com/pt-br/azure/quantum/hybrid-computing-overview. Acesso em: 15 out. 2024.
BELL, J. Operating Systems: Introduction. Computer Science, University of Illinois at Chicago. Disponível em: https://www.cs.uic.edu/~jbell/CourseNotes/OperatingSystems/1_Introduction.html. Acesso em: 6 jun. 2025.
BERTRAND, E. D. Introduction to Operating Systems. School of Electrical and Computer Engineering, Purdue University. Disponível em: https://engineering.purdue.edu/~ebertd/469/notes/EE469-ch1.pdf. Acesso em: 6 jun. 2025.
| BRITANNICA. **Dennis M. Ritchie | Biography & Facts**. Disponível em: https://www.britannica.com/biography/Dennis-M-Ritchie. Acesso em: 7 jun. 2025. |
CARVALHO, C. A. G. F. Características de Sistemas Distribuídos. Universidade Federal de Pernambuco, Centro de Informática. Disponível em: https://www.cin.ufpe.br/~cagf/sdgrad/aulas/Caracteristicas.pdf. Acesso em: 15 out. 2024.
| CLOUDFLARE. **O que é multilocação? | Arquitetura multi-inquilinos**. Cloudflare. Disponível em: https://www.cloudflare.com/pt-br/learning/cloud/what-is-multitenancy/. Acesso em: 15 out. 2024. |
CLOUDZERO. What Is Cloud Elasticity? (+How Does It Affect Cloud Spend?). CloudZero. Disponível em: https://www.cloudzero.com/blog/cloud-elasticity/. Acesso em: 15 out. 2024.
COMPUTER HISTORY MUSEUM. Dennis Ritchie - CHM. Disponível em: https://computerhistory.org/profile/dennis-ritchie/. Acesso em: 7 jun. 2025.
CORE. Operating systems for computer networks. Academic Repository. Disponível em: https://core.ac.uk/download/pdf/228680543.pdf. Acesso em: 6 jun. 2025.
DEITEL, H. M.; DEITEL, P. J.; CHOFFNES, D. R. Operating Systems. 3. ed. Boston: Pearson, 2004.
DENNIS Ritchie and Ken Thompson on the history of UNIX. Disponível em: https://my3.my.umbc.edu/groups/csee/media/1799. Acesso em: 7 jun. 2025.
EARLY UNIX history and evolution. Nokia Bell Labs. Disponível em: https://www.nokia.com/bell-labs/about/dennis-m-ritchie/hist.html. Acesso em: 7 jun. 2025.
FREERTOS. FreeRTOS - Market leading RTOS for embedded systems. Disponível em: https://www.freertos.org/. Acesso em: 22 jun. 2025.
FERRIOLS, F. iPhone 17 AI Battery Improvements in iOS 19: More Than Just a Nice-to-Have. Thinborne, 23 May 2025. Disponível em: https://thinborne.com/blogs/news/iphone-17-ai-battery-improvements-in-ios-19-more-than-just-a-nice-to-have. Acesso em: 15 out. 2024.
FOSSCOMICS. The Origins of UNIX and the C Language. Disponível em: https://fosscomics.com/8.%20The%20Origins%20of%20Unix%20and%20the%20C%20Language/. Acesso em: 7 jun. 2025.
GIORTAMIS, E. et al. QOS: A Quantum Operating System. arXiv:2406.19120v2, 28 Jun. 2024. Disponível em: https://arxiv.org/html/2406.19120v2. Acesso em: 15 out. 2024.
HONEYWELL. How Quantum Will Transform the Future of 5 Industries. Honeywell, Jul. 2020. Disponível em: https://www.honeywell.com/br/pt/news/2020/07/how-quantum-will-transform-the-future-of-5-industries. Acesso em: 15 out. 2024.
IBM QUANTUM. Qiskit Runtime Overview. Disponível em: https://quantum-computing.ibm.com/services/runtime. Acesso em: 22 jun. 2025.
IT BRIEFCASE. New Trends Increase the Effectiveness of Distributed Computing. IT Briefcase, 17 Dec. 2024. Disponível em: https://itbriefcase.net/new-trends-increase-the-effectiveness-of-distributed-computing/. Acesso em: 15 out. 2024.
JONES, P. J. Operating Systems. Department of Computer Science, University of Manchester. Disponível em: https://www.cs.man.ac.uk/~pjj/cs1011/filestore/node2.html. Acesso em: 6 jun. 2025.
KERNIGHAN, Brian. Computer Hope. Disponível em: https://www.computerhope.com/people/brian_kernighan.htm. Acesso em: 7 jun. 2025.
KLABUNDE, R. et al. Hybrid Quantum-Classical Computing Systems: Architectures, Interfaces, and Applications. arXiv:2503.18868v1, 27 Mar. 2025. Disponível em: https://arxiv.org/html/2503.18868v1. Acesso em: 15 out. 2024.
KNOTT, W. J. UNIX and Operating Systems Fundamentals. Department of Computing, Imperial College London. Disponível em: http://www.doc.ic.ac.uk/~wjk/UNIX/Lecture1.html. Acesso em: 6 jun. 2025.
LESSONS Learned from 30 Years of MINIX. Communications of the ACM. Disponível em: https://cacm.acm.org/research/lessons-learned-from-30-years-of-minix/. Acesso em: 7 jun. 2025.
LIBERTY UNIVERSITY. Operating Systems – CSIS 443. Liberty University Online. Disponível em: https://www.liberty.edu/online/courses/csis443/. Acesso em: 6 jun. 2025.
LIVINGINTERNET. History of C Programming Language. Disponível em: https://www.livinginternet.com/i/iw_unix_c.htm. Acesso em: 7 jun. 2025.
MELL, P.; GRANCE, T. The NIST Definition of Cloud Computing. National Institute of Standards and Technology, Special Publication 800-145, Sep. 2011. Disponível em: https://peasoup.cloud/nist-definition-of-cloud-computing/ e https://cic.gsa.gov/basics/cloud-basics. Acesso em: 15 out. 2024.
MICROSOFT AZURE. O que é computação elástica?. Dicionário de Computação em Nuvem do Azure. Disponível em: https://azure.microsoft.com/pt-br/resources/cloud-computing-dictionary/what-is-elastic-computing. Acesso em: 15 out. 2024.
MIT OPENCOURSEWARE. 6.828 Operating System Engineering. Electrical Engineering and Computer Science Department. Disponível em: https://ocw.mit.edu/courses/6-828-operating-system-engineering-fall-2012/. Acesso em: 6 jun. 2025.
MOBILE OPERATING SYSTEM. The Flying Theatre Company. Disponível em: https://theflyingtheatre.com/UserFiles/images/files/punel.pdf. Acesso em: 15 out. 2024.
NORTHWESTERN UNIVERSITY. COMP_SCI 343: Operating Systems. Computer Science Department, McCormick School of Engineering. Disponível em: https://www.mccormick.northwestern.edu/computer-science/academics/courses/descriptions/343.html. Acesso em: 6 jun. 2025.
NUTT, G. Operating Systems: A Modern Perspective. 3. ed. Boston: Addison-Wesley, 2004.
ORACLE. O que é computação em nuvem?. Oracle Brasil. Disponível em: https://www.oracle.com/br/cloud/what-is-cloud-computing/. Acesso em: 15 out. 2024.
ORGANICK, E. I. The Multics System: An Examination of its Structure. Cambridge: MIT Press, 1972.
POWER MANAGEMENT TECHNIQUES IN SMARTPHONES OPERATING SYSTEMS. IJCSI International Journal of Computer Science Issues, v. 9, i. 3, n. 3, May 2012. Disponível em: https://www.researchgate.net/publication/268409514_Power_Management_Techniques_in_Smartphones_Operating_Systems. Acesso em: 15 out. 2024.
QUANTUM COMPUTING: AN EMERGING ECOSYSTEM AND INDUSTRY USE CASES. McKinsey & Company, Dec. 2021. Disponível em: https://www.westconference.org/WEST25/Custom/Handout/Speaker0_Session11706_1.pdf. Acesso em: 15 out. 2024.
REPOSITÓRIO UNIFESSPA. Os desafios da computação em nuvem. Universidade Federal do Sul e Sudeste do Pará. Disponível em: https://repositorio.unifesspa.edu.br/bitstream/123456789/228/1/TCC_%20Os%20desafios%20da%20computa%C3%A7%C3%A3o%20em%20nuvem.pdf. Acesso em: 15 out. 2024.
RIOT-OS. RIOT: The friendly operating system for IoT. Disponível em: https://www.riot-os.org/. Acesso em: 22 jun. 2025.
RITCHIE, D. M.; THOMPSON, K. The UNIX Time-Sharing System. Communications of the ACM, v. 17, n. 7, p. 365-375, 1974.
SALTZER, J. H.; SCHROEDER, M. D. The protection of information in computer systems. Proceedings of the IEEE, v. 63, n. 9, p. 1278-1308, 1975.
SHARMA, A. One UI 7 could bring even smarter power-saving options to Galaxy phones. Android Authority, 15 May 2025. Disponível em: https://www.androidauthority.com/one-ui-7-power-saving-options-3558362/. Acesso em: 15 out. 2024.
SIEGFRIED, S. CSC 553 Operating Systems - Lecture 2. Computer Science Department, Adelphi University. Disponível em: https://home.adelphi.edu/~siegfried/cs553/553l2.pdf. Acesso em: 6 jun. 2025.
SILBERSCHATZ, A.; GALVIN, P. B.; GAGNE, G. Operating System Concepts. 10. ed. Hoboken: John Wiley & Sons, 2018.
SPINQ. Quantum Computer Operating System: The Key to Quantum Power. SpinQ Technology, 16 Jan. 2025. Disponível em: https://www.spinquanta.com/news-detail/quantum-computer-operating-system-the-key-to-quantum-power20250116104617. Acesso em: 15 out. 2024.
STALLINGS, W. Operating Systems: Internals and Design Principles. 9. ed. Boston: Pearson, 2018.
SWEISS, W. Chapter 1: Introduction to Operating Systems. Computer Science Department, Hunter College, CUNY. Disponível em: https://www.cs.hunter.cuny.edu/~sweiss/course_materials/csci340/slides/chapter01.pdf. Acesso em: 6 jun. 2025.
TANENBAUM, A. S.; BOS, H. Modern Operating Systems. 4. ed. Boston: Pearson, 2015.
THE MOONLIGHT. QOS: A Quantum Operating System. The Moonlight Review. Disponível em: https://www.themoonlight.io/en/review/qos-a-quantum-operating-system. Acesso em: 15 out. 2024.
TOPTAL. Why the C Programming Language Still Runs the World. Disponível em: https://www.toptal.com/c/after-all-these-years-the-world-is-still-powered-by-c-programming. Acesso em: 7 jun. 2025.
UNIVERSITY OF COLORADO. CSCI 3753 Operating Systems Syllabus. Computer Science Department. Disponível em: https://home.cs. Acesso em: 6 jun. 2025.
UNIX and Multics. Disponível em: https://multicians.org/UNIX.html. Acesso em: 7 jun. 2025.
| **UNIX | Definition, Meaning, History, & Facts**. Britannica. Disponível em: https://www.britannica.com/technology/UNIX. Acesso em: 7 jun. 2025. |
UNIX - Wikipedia. Wikipedia. Disponível em: https://en.wikipedia.org/wiki/UNIX. Acesso em: 7 jun. 2025.
VON KYPKE, L.; WACK, A. How an Operating System for Quantum Computers Should Be Architected. arXiv:2410.13482v1, 21 Oct. 2024. Disponível em: https://arxiv.org/html/2410.13482v1. Acesso em: 15 out. 2024.
ZDNET. I changed 12 settings on my Android phone to give it an instant battery boost. ZDNet. Disponível em: https://www.zdnet.com/article/i-changed-12-settings-on-my-android-phone-to-give-it-an-instant-battery-boost/. Acesso em: 15 out. 2024.
ZEPHYR PROJECT. Zephyr RTOS Documentation. Disponível em: https://docs.zephyrproject.org/. Acesso em: 22 jun. 2025.
Glossário - Sistemas Operacionais: Fundamentos e Evolução
A
Abstração Processo de esconder detalhes complexos de implementação, fornecendo uma interface mais simples e amigável para os usuários e programadores.
ACLs (Access Control Lists) Listas que especificam quais usuários ou processos têm permissão para acessar determinados recursos do sistema e que tipo de operações podem realizar.
Adaptive Battery Recurso de IA (Inteligência Artificial) em sistemas operacionais móveis, como o Android, que aprende os padrões de uso do usuário para otimizar o consumo de energia.
AKKA Toolkit e runtime para construir aplicações concorrentes, distribuídas e resilientes na JVM, baseado no modelo de atores.
Alocação de Memória Processo de atribuir blocos de memória principal aos processos que necessitam de espaço para execução.
Android Sistema operacional móvel desenvolvido pelo Google, baseado no kernel Linux e de código aberto.
Android Runtime (ART) Ambiente de execução usado pelo Android para executar aplicativos, substituindo a antiga máquina virtual Dalvik.
API (Application Programming Interface) Conjunto de rotinas, protocolos e ferramentas que especificam como componentes de software devem interagir.
B
Batch Processing (Processamento em Lote) Método de processamento no qual os programas são executados sequencialmente sem interação direta do usuário, maximizando a utilização da CPU.
Buffering Técnica que utiliza áreas de memória temporária para compensar diferenças de velocidade entre dispositivos, melhorando o desempenho do sistema.
C
Cache Memória de alta velocidade que armazena dados frequentemente acessados para reduzir o tempo de acesso médio.
Chamadas de Sistema (System Calls) Interface programática por meio da qual processos solicitam serviços do sistema operacional.
CFS (Completely Fair Scheduler) Algoritmo de escalonamento do kernel Linux que visa garantir uma distribuição justa do tempo de CPU entre os processos.
Colossus Um dos primeiros computadores eletrônicos, utilizado pelo Reino Unido durante a Segunda Guerra Mundial para decifrar códigos.
Computação em Nuvem Modelo de fornecimento de serviços de computação (servidores, armazenamento, bancos de dados, etc.) pela internet (“a nuvem”).
Computação Quântica Paradigma de computação que utiliza princípios da mecânica quântica, como superposição e emaranhamento, para processar informações.
Concorrência Capacidade de múltiplos processos ou threads executarem simultaneamente, compartilhando recursos do sistema.
Context Switch (Troca de Contexto) Processo de salvar o estado de um processo em execução e carregar o estado de outro processo para execução.
CP/M (Control Program for Microcomputers) Um dos primeiros sistemas operacionais dominantes para microcomputadores de 8 bits, que influenciou o MS-DOS.
CPU Scheduling Processo de determinar qual processo deve utilizar a CPU em um determinado momento.
CTSS (Compatible Time-Sharing System) Sistema pioneiro de tempo compartilhado desenvolvido no MIT que estabeleceu conceitos fundamentais de sistemas interativos.
D
Dalvik Máquina virtual utilizada em versões mais antigas do Android para executar aplicativos, posteriormente substituída pela ART.
Deadlock Situação na qual dois ou mais processos ficam permanentemente bloqueados, cada um esperando que o outro libere um recurso.
Device Driver Software específico que permite ao sistema operacional comunicar-se com dispositivos de hardware particulares.
DMA (Direct Memory Access) Técnica que permite a dispositivos de E/S acessar a memória principal diretamente, sem intervenção da CPU.
Docker Plataforma de software que permite a criação, teste e implantação de aplicações em containers.
Dual-Mode Operation Mecanismo de proteção de hardware que distingue entre o modo de usuário (user mode), com privilégios limitados, e o modo de kernel (kernel mode), com acesso irrestrito.
E
Earliest Deadline First (EDF) Algoritmo de escalonamento de tempo real que prioriza dinamicamente as tarefas com o prazo final (deadline) mais próximo.
EDA (Event-Driven Architecture) Arquitetura de software na qual os componentes do sistema reagem a eventos, promovendo baixo acoplamento e escalabilidade.
EDVAC Um dos primeiros computadores eletrônicos a utilizar o conceito de programa armazenado na memória.
Emaranhamento (Entanglement) Fenômeno quântico no qual múltiplos qubits se tornam interligados, de forma que o estado de um afeta instantaneamente o estado dos outros.
ENIAC Um dos primeiros computadores digitais eletrônicos de grande escala, desenvolvido nos EUA durante a Segunda Guerra Mundial.
Escalonamento (Scheduling) Processo de decidir qual processo, thread ou tarefa deve ser executado em um determinado momento.
Espaço de Endereçamento Conjunto de endereços de memória que um processo pode utilizar para armazenar dados e código.
F
FCFS (First-Come, First-Served) Algoritmo de escalonamento no qual os processos são executados na ordem de chegada.
File System (Sistema de Arquivos) Método de organizar e armazenar arquivos em dispositivos de armazenamento secundário.
FMS (Fortran Monitor System) Um dos primeiros sistemas de monitoramento para programas FORTRAN.
G
GPU (Graphics Processing Unit) Processador especializado projetado para renderizar gráficos, mas também utilizado para acelerar tarefas de computação paralela.
GUI (Graphical User Interface) Interface que utiliza elementos gráficos como janelas, ícones e menus para interação com o usuário.
H
HAL (Hardware Abstraction Layer) Camada de software que esconde diferenças específicas de hardware, proporcionando uma interface uniforme.
Hypervisor Software ou hardware que cria e executa máquinas virtuais (VMs), também conhecido como Monitor de Máquina Virtual (VMM).
I
IaaS (Infrastructure as a Service) Modelo de computação em nuvem que oferece recursos de computação virtualizados pela internet.
IBSYS Sistema batch para o IBM 7094 que estabeleceu muitos conceitos fundamentais de sistemas operacionais.
Inodes Estrutura de dados em sistemas de arquivos do tipo Unix que armazena metadados sobre um arquivo ou diretório.
Interrupção Sinal que informa à CPU sobre a ocorrência de um evento que requer atenção imediata.
IOKit Framework orientado a objetos no macOS para a criação de drivers de dispositivo.
iOS Sistema operacional móvel proprietário da Apple, utilizado em iPhones e iPads.
IPC (Inter-Process Communication) Mecanismos que permitem a processos trocar dados e sincronizar suas atividades.
J
JCL (Job Control Language) Linguagem específica utilizada para instruir sistemas batch sobre como processar trabalhos.
Job Termo usado principalmente em sistemas batch para se referir a uma tarefa ou trabalho a ser executado. O equivalente moderno é o processo.
K
Kernel Parte central do sistema operacional que gerencia recursos do sistema e fornece serviços fundamentais.
Kubernetes Plataforma de orquestração de containers de código aberto para automatizar a implantação, o escalonamento e a gestão de aplicações em containers.
L
L4 Família de microkernels de segunda geração, conhecida por seu alto desempenho e design minimalista.
Linguagem C Linguagem de programação de propósito geral desenvolvida por Dennis Ritchie, intimamente ligada ao desenvolvimento do sistema operacional UNIX.
Linux Kernel de sistema operacional de código aberto, monolítico e semelhante ao UNIX, criado por Linus Torvalds. É a base para muitas distribuições de SO.
Lisp Família de linguagens de programação com uma longa história e uma sintaxe distintiva baseada em S-expressions.
LLM (Large Language Model) Modelo de inteligência artificial treinado com grandes volumes de texto para compreender e gerar linguagem humana.
LLMOS (Large Language Model Operating System) Conceito de sistema operacional que integra LLMs em seu núcleo para revolucionar a interação do usuário por meio de linguagem natural.
LPU (Language Processing Unit) Tipo de processador especializado, como o da Groq, projetado para acelerar a inferência de modelos de linguagem.
LSI (Large Scale Integration) Tecnologia de circuitos integrados que permitiu a criação de microprocessadores e computadores pessoais.
LXC (Linux Containers) Tecnologia de virtualização no nível do sistema operacional para rodar múltiplos ambientes Linux isolados (containers) em um único host.
M
Máquina Virtual Abstração de software que simula um computador completo, permitindo execução de múltiplos sistemas operacionais.
Macintosh OS (Classic Mac OS) Sistema operacional da Apple que popularizou a interface gráfica do usuário (GUI) com sua metáfora de área de trabalho.
Memory Management Função do sistema operacional responsável por controlar e coordenar o uso da memória principal.
Microserviços Estilo arquitetural que estrutura uma aplicação como uma coleção de serviços pequenos, independentes e fracamente acoplados.
MINIX Sistema operacional semelhante ao Unix, baseado em uma arquitetura de microkernel, criado por Andrew S. Tanenbaum para fins educacionais.
MMU (Memory Management Unit) Componente de hardware responsável por traduzir endereços virtuais em endereços físicos.
MS-DOS (Microsoft Disk Operating System) Sistema operacional de linha de comando que dominou computadores pessoais compatíveis com IBM na década de 1980.
MULTICS (Multiplexed Information and Computing Service) Sistema de tempo compartilhado avançado que introduziu conceitos como memória virtual e sistema de arquivos hierárquico, e que influenciou o UNIX.
Multiprocessamento Técnica que permite que múltiplos programas residam na memória simultaneamente, melhorando a utilização da CPU.
Multitasking Capacidade de um sistema executar múltiplas tarefas aparentemente em paralelo por meio de compartilhamento de tempo.
N
NFS (Network File System) Sistema que permite acesso a arquivos por meio de uma rede como se fossem locais.
NISQ (Noisy Intermediate-Scale Quantum) Era atual da computação quântica, caracterizada por processadores com um número intermediário de qubits que são suscetíveis a ruído.
O
OS/360 Família de sistemas operacionais da IBM para seus mainframes System/360, que estabeleceu muitos conceitos fundamentais de Multiprocessamento.
P
PaaS (Platform as a Service) Modelo de computação em nuvem que fornece uma plataforma permitindo aos clientes desenvolver, executar e gerenciar aplicações sem a complexidade de construir e manter a infraestrutura.
Paginação Técnica de gerenciamento de memória que divide a memória em páginas de tamanho fixo.
Paxos Família de protocolos para resolver o consenso em uma rede de processos não confiáveis.
PBFT (Practical Byzantine Fault Tolerance) Algoritmo de consenso projetado para tolerar falhas bizantinas (comportamento malicioso ou arbitrário) em sistemas distribuídos.
PCB (Process Control Block) Estrutura de dados que contém informações sobre um processo específico.
PIO (Programmed I/O) Método de transferência de dados entre a CPU e um periférico no qual a CPU executa um programa que controla a transferência.
POSIX Conjunto de padrões especificados pelo IEEE para manter a compatibilidade entre sistemas operacionais, especialmente variantes do Unix.
Preemptive Scheduling Tipo de escalonamento no qual o sistema operacional pode interromper um processo em execução para dar lugar a outro.
Processo Programa em execução, incluindo código, dados, pilha e contexto de execução.
PRISM Projeto de sistema operacional cancelado da DEC, do qual Dave Cutler, arquiteto do Windows NT, fazia parte.
Q
QCOS (Quantum Computer Operating System) Sistema operacional projetado para gerenciar os recursos de um computador quântico.
Qernel Componente central de um QCOS, análogo ao kernel clássico, que gerencia os recursos quânticos como qubits.
QNX Sistema operacional comercial de tempo real baseado em uma arquitetura de microkernel, usado em sistemas embarcados críticos.
Quantum Fatia de tempo atribuída a um processo em algoritmos de escalonamento round-robin. Também chamado de Time Slice.
Qubit Unidade básica de informação quântica, análoga ao bit clássico, mas que pode existir em uma superposição de estados.
R
Raft Algoritmo de consenso projetado para ser mais fácil de entender que o Paxos.
Rate Monotonic (RM) Algoritmo de escalonamento de tempo real de prioridade fixa, usado para tarefas periódicas.
Round Robin Algoritmo de escalonamento no qual cada processo recebe uma fatia de tempo fixa antes de ser preemptado.
RPC (Remote Procedure Call) Mecanismo que permite a um programa executar um procedimento ou função em outro computador na rede como se fosse uma chamada local.
RTOS (Real-Time Operating System) Sistema operacional destinado a aplicações de tempo real que processam dados à medida que chegam, geralmente sem atrasos de buffer.
S
SaaS (Software as a Service) Modelo de licenciamento e entrega de software no qual o software é licenciado por assinatura e hospedado centralmente.
Sandboxing Mecanismo de segurança para separar programas em execução, restringindo o ambiente em que o código pode operar.
Scala Linguagem de programação que combina programação orientada a objetos e funcional, projetada para ser concisa e escalável.
Segmentação Técnica de gerenciamento de memória que divide o espaço de endereçamento em segmentos lógicos.
SJF (Shortest Job First) Algoritmo de escalonamento que prioriza processos com menor tempo de execução estimado.
SMB/CIFS Protocolo de rede para compartilhamento de arquivos, impressoras e outros recursos, predominantemente usado em ambientes Windows.
Spooling (Simultaneous Peripheral Operation On-Line) Técnica que utiliza disco como buffer para operações de E/S, como a impressão.
SQLite Biblioteca de software que implementa um banco de dados SQL autônomo, sem servidor e sem configuração.
Swapping Técnica de mover processos inteiros entre memória principal e armazenamento secundário.
System Call Interface por meio da qual programas de usuário solicitam serviços do kernel.
T
TCP/IP Conjunto de protocolos de comunicação que formam a base da Internet, organizados em camadas (Aplicação, Transporte, Internet, Acesso à Rede).
Teorema CAP Princípio fundamental dos sistemas distribuídos que afirma ser impossível garantir simultaneamente Consistência, Disponibilidade e Tolerância a Partições.
THE (Technische Hogeschool Eindhoven) Sistema operacional influente desenvolvido por Edsger Dijkstra, pioneiro na utilização de uma arquitetura estritamente em camadas.
Thread Unidade básica de utilização da CPU dentro de um processo, permitindo execução concorrente.
Throughput Medida da quantidade de trabalho realizado por unidade de tempo, como o número de tarefas concluídas por hora.
Time-Sharing (Tempo Compartilhado) Sistema no qual múltiplos usuários compartilham recursos computacionais simultaneamente, com o SO alternando rapidamente entre eles.
Time Slice Período de tempo durante o qual um processo pode utilizar a CPU antes de ser preemptado. Também chamado de Quantum.
TLB (Translation Lookaside Buffer) Cache de memória usado pela unidade de gerenciamento de memória (MMU) para acelerar a tradução de endereços virtuais para físicos.
TPU (Tensor Processing Unit) Acelerador de IA especializado, desenvolvido pelo Google, para processamento de redes neurais.
U
UNIX Sistema operacional multiusuário e multitarefa, portável e influente, desenvolvido nos Bell Labs. Sua filosofia de design impactou muitos outros sistemas.
V
Válvulas Termiônicas (Tubos de Vácuo) Componentes eletrônicos usados nos primeiros computadores, como o ENIAC, que controlavam o fluxo de elétrons no vácuo.
Virtual Memory (Memória Virtual) Técnica que permite a execução de programas maiores que a memória física disponível, utilizando o armazenamento secundário como uma extensão da RAM.
VLSI (Very Large Scale Integration) Tecnologia avançada de circuitos integrados que permitiu maior densidade de componentes.
VMS (Virtual Memory System) Sistema operacional da DEC, conhecido por sua robustez, que influenciou o design do Windows NT.
W
Wake Locks Mecanismo no Android que permite que aplicações mantenham a CPU ou a tela ativas para realizar tarefas em segundo plano.
Windows Família de sistemas operacionais desenvolvidos pela Microsoft, que evoluiu de um ambiente gráfico sobre o MS-DOS para sistemas operacionais completos.
Windows NT (New Technology) Linha de sistemas operacionais da Microsoft construída com uma arquitetura híbrida, formando a base para todas as versões modernas do Windows.
X
XNU Kernel do macOS e iOS, que combina o microkernel Mach com componentes do BSD Unix, formando uma arquitetura híbrida.
Z
Z3 O primeiro computador programável e totalmente automático do mundo, criado por Konrad Zuse na Alemanha em 1941.
-
O pobre autor começou sua vida profissional em um velho mainframe IBM 360/30, com o OS/360 rodando Cobol, PL/1 e RPG. O sistema era tão antigo que o manual de operação era um livro de papel, com mais de 1000 páginas, e o computador tinha apenas 32 KB de memória. Era o final dos anos 1970 poucos meses antes deste 360/30 ser descomissionado e substituído por um IBM 370/10 que, usando memória virtual chegava a 16 MBytes de memória. Imagine! ↩
-
O pobre autor teve que comprar uma placa de expansão para rodar o CP/M no seu Apple II. A placa tinha um processador Z80, 64 KB de memória e um drive de disquete de 5.25 polegadas. O CP/M rodava em modo texto, mas permitia o uso de programas como o WordStar e o dBase II, que eram muito populares na época. O CP/M foi um dos primeiros sistemas operacionais a permitir a execução de múltiplos programas simultaneamente, embora não fosse multitarefa no sentido moderno. Mais importante, eu tinha, em casa, a disposição, uma máquina que podia ser programada em C. Me livrando do Basic infernal do Apple II. ↩
-
Este, o pobre autor, rodava em um PC-386, com co-processador matemático, comprado em consórcio e construído pela Cobra Informática, uma empresa brasileira que importava componentes e montava computadores sob medida. O MS-DOS era o sistema operacional padrão para PCs compatíveis com IBM, e eu o utilizava para rodar programas como o WordPerfect e o Lotus 1-2-3. Usava o Borland C++ para programar em C++, e o Turbo Pascal para programar em Pascal. Mas, devo confessar, este último só quando eu queria me martirizar. ↩